My assistants response time is below 1s in the playground but when I send the same query over API my Netlify environment kills the connection after 26s (max timeout level). The API has been degrading slowly over time since I first tried it. I guess the reason is given in this post /t/assistants-api-too-slow-for-realtime-production/493627/2. How much do I need to spend to get a decent response time sustained? 10s would be ok-ish.
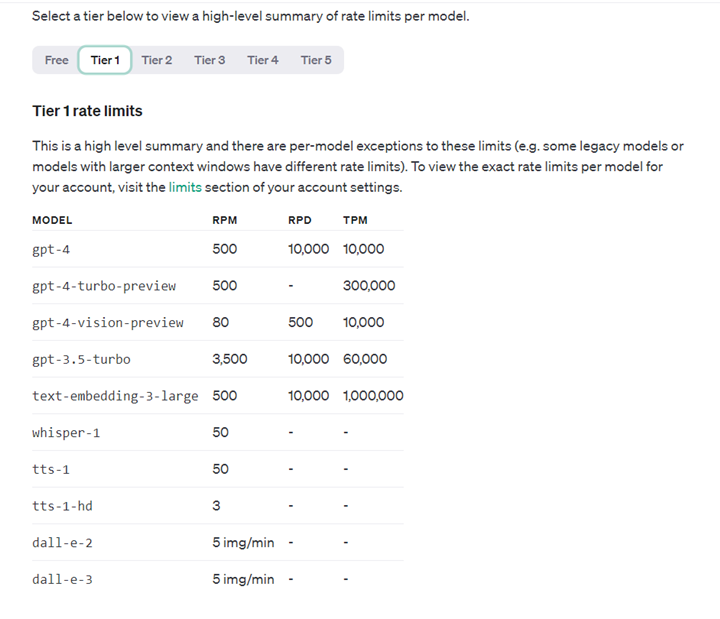
You can view the rate and usage limits for your organization under the limits section of your account settings. As your usage of the OpenAI API and your spend on our API goes up, we automatically graduate you to the next usage tier. This usually results in an increase in rate limits across most models.
Note, though, even at Tier 5 you might run into snags with the API (including low latency…) However, once you get to a certain point, you can likely contact sales, but there’s a lot of companies spending a lot of money right now, so you might have to work with the lower levels…
It is always the function call that causes pain. I just switched to GPT4 turbo but not getting better. I am a single user cause I am still developing the app thus I will not create huge amount of spending yet. But as long as I stay on Tier 1 I can’t onboard any users since the application is rendered useless. Users won’t forgive the timeouts. Can I use the Chat Completion instead of an Assistant and still get a response that can reliably trigger a function call?
Hey guys were you able to figure this out? I cannot find information in all docs about how to get access to 128k context window, I need it for adding a custom language reference (Verse programming, a DSL by Epic games for unreal) alongside my requests in the API, but currently capped at 8k tokens, I’m happily a paying customer, but I need to know at what point I’ll get access to 32k and 128k of gpt4 models (any of them really) otherwise it’s a random guess and I’ll throw 250$ into the balance (no problem with that of course, I will use it one day even if it’ll not work for my current idea about Verse coding) but will not get the ability to run the 32k context at least (as a minimum, will put the short version of language reference into it, might still work for some of my queries) it’s a waste could anyone point me to where we can see those actual access tiers? in case you figured it out
I’m on 1, but these models are limited to 8k in my case in the Assistants api, that’s what I use. So I thought the token limits are in addition to the name of models, and the name doesn’t mean it’ll actually allow sending more to the input. In my case they don’t allow, errors out with “you sent more than N tokens”.
Are you explicitly using gpt-4-turbo models for the Assistant’s API or the original GPT-4 model? GPT-4 or GPT-4-0613 are by default restricted to 8k context window. For GPT-4-turbo models you should have higher context window for Assistants. Personally I am not aware of a restriction in the access to GPT-4 turbo models under the Assistants API due to a lower tier (other than the free tier).
aha! so here’s what happens in the assistants api in playground:
but in the Chat it does not show me such error. I wonder if the one in “Chat” actually can consume all documentation of 50k tokens that I paste, will try now to see if it only reads part of it, or has access to all of it in one same request.
32k that it shows here is about characters, so it’s roughly the 8k tokens unfortunately, that’s why I’m trying to understand what is it and at which tier I can expect this to have a full context window. This error is for all gpt4 turbo model names, I tried all 3 (preview, 0125, 1106, all same error in assistants menu in playground). and the old gpt4 has a “per minute 10k tokens” so I can’t even feed a few requests to it, but that’s fine, it’s old and powerful and we’re not supposed to use it since it’s expensive on the hardware. The current per minute for ‘turbo’ is 300k for me, but this error about single context window size in request is what blocking me for now.
$50 paid and 7+ days since first successful payment
We have anecdotal evidence that it may take a few days to upgrade. If you don’t see any change in the next couple of days, you should reach out with a message via the OpenAI chat support function.
How to access the OpenAI chat support function? need to ask about upgrading tiers.
I’d like to upgrade to tier 4 but payment won’t allow me to put in $250 ??
Hi @apps6 - you either click on the help button on the bottom left in the developer platform, which will bring up the chat, or you can access the chat widget via https://help.openai.com/en/.
What specific error are you getting when trying to add $250 to your developer account?