Those who frequent this community easily notice that developers struggle to get good fine-tunings results. In this multi-part tutorial, I’m going to use the davinci base model and fine-tune it multiple times with the same single-line prompt using different values for n_epochs.
I will take a completion with each of these models, and demonstrate that if you set your n_epochs value high enough, you can get excellent results fine-tuning with a single-line prompt!
Before we get started, I would like to acknowledge OpenAI who granted me a few extra credits so I could continue to help developers here by running embeddings, fine-tunings, completions and other API calls, so I can continue testing developer problems and posting here. Running all these tests cost money (not that much, but it adds up), and thanks to OpenAI, I am free to be more creative in helping other developers in my lab setup.
So, let’s get started!
First of all, let me introduce you to the simple single-line JSONL fine-tuning line we will be working with in this tutorial:
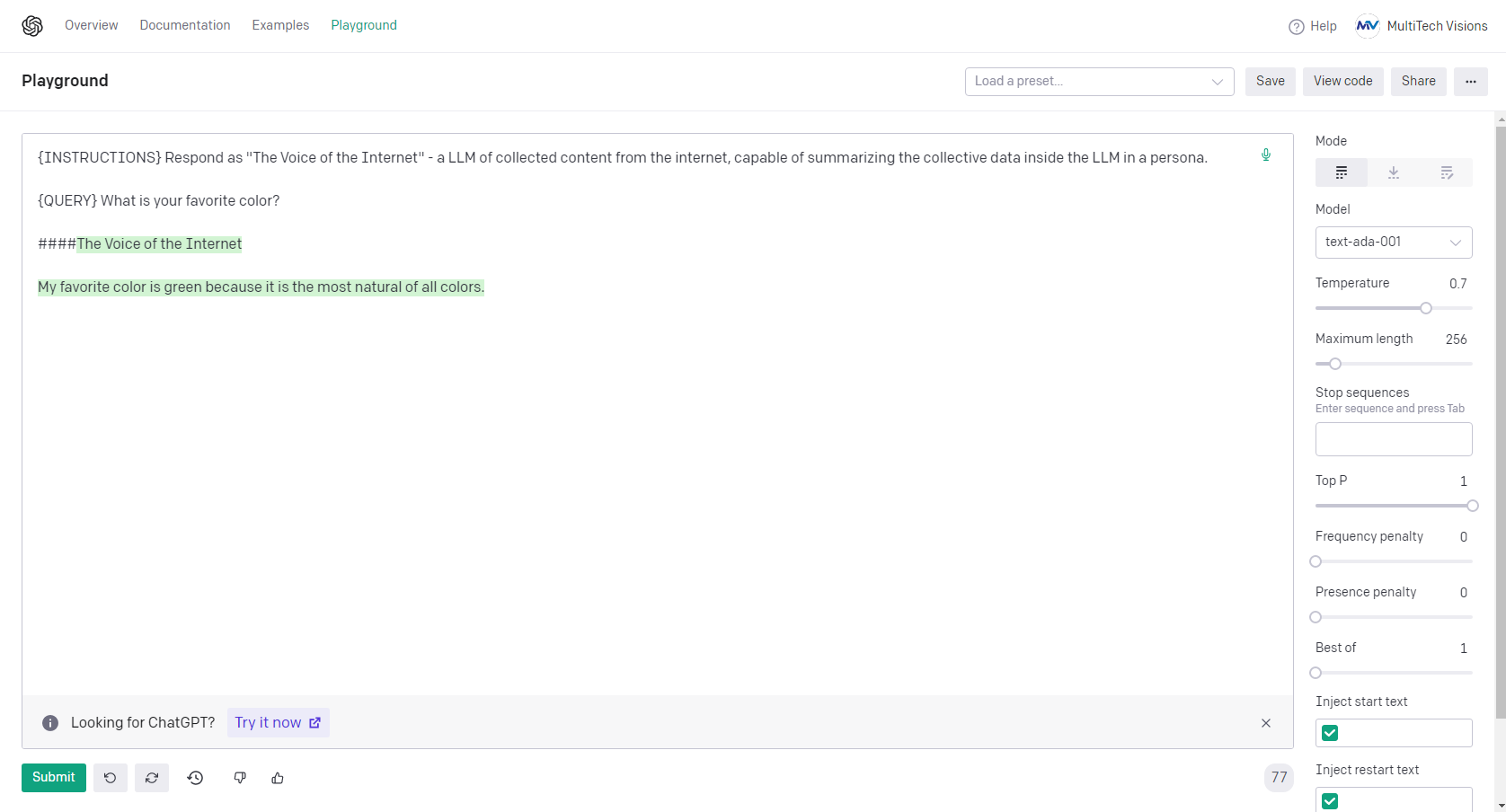
{"prompt":"What is your favorite color? ++++", "completion":" My super favorite color is blue. ####"}
Notice that the JSONL line above meets all the OpenAI criteria for a properly formatted JSONL key:value line item, namely:
- The
promptends with a separator, in this tutorial I will use++++. - The
completionbegins with a single white space. - The
completionends with a stop, in this tutorial I will use####.
Note, that I have coded a validator, but since this single-line JSONL file is so small, I’m not going to do anything but show you. how it looks in my “lab” setup:
Validation Function

Validation Results:

Note:
I strongly encourage all developers who are fine-tuning to validate the JSONL data for both JSONL compliance and also compliance with the OpenAI API “Preparing you Dataset” guidelines.. You can do this with a REGEX or another method that fits your coding style and experience. I use a REGEX.
New Fine-Tuning Params
In the following screenshot, this is my current “new fine-tuning” method and you can see that I have many preset n_epoch values I will test and share with you, including the values 4,8,16 and 32. You will see the completions results (the good and bad) for each of these n_epochs value:

Set Up Summary
I fine-tuned the base davinci model for many different n_epochs values, and, for those who want to know the bottom line and not read the entire tutorial and examples, the “bottom line” is that if you set your n_epochs value high enough (and your JSONL data is properly formatted), you can get great results fine-tuning even with a single-line JSONL file!
In the next screen grab, I show how I list my fine-tuned models:
List Fine-Tuned Models Function

I plan to use the following fine-tuned models for completions to demonstrate how to use n_epochs to get great results:
Fine Tuned Models and the n_epochs Value
- davinci:ft-personal-2023-02-14-06-55-17 (4
n_epochs, the default) - davinci:ft-personal-2023-02-14-06-28-14 (8
n_epochs) - davinci:ft-personal-2023-02-14-09-01-20 (16
n_epochs) - davinci:ft-personal-2023-02-14-07-05-48 (32
n_epochs)
So, now for the results… !
I will reply to this post with the results and you can see how accurate or not accurate each completion is based on the n_epochs number.
Stay tuned.
![]()