Hey text you if I can speech dude Holly f****** s*** dude that didn’t even come out close. But I definitely would like to talk to you about some of this agent stuff that I’ve been doing.
Very cool, I started on a very similar project earlier this year called Convo-Lang, but with a heavy focus on function calling. Would you be interested in collaborating?
My repo is named convo-lang/convo-lang on GitHub. I’d include a link but I’m not allowed to share links in the post lol
I’ll take a look! I’m curious to see your approach.
Sharing a link to the tutorial for Convo-lang as it’s definitely interesting and worth a look:
@convo-lang there are some similarities but also differences approach wise. The conversational interpreter you’ve built is interesting and hats off to you as I can tell you’ve put a lot of effort into it. The edge message concept is particularly interesting as I normally think of messages as being immutable once they’re delivered. I’d need to mull that one over a bit but I get what you’re going for.
I’d say the key difference is that I’m not trying to build an explicit interpreter with convo. Or if anything I’m leaning on the LLM itself to be the interpreter. I view convo as a discovery as much as anything. Yes I defined a convo spec but the contents of that spec really doesn’t matter. It’s just a prop to put the model in the right mindset to write pseudocode. Even the fact I slapped the “convo” label on all of this is a bit arbitrary. It’s just pseudocode.
Not to take anything away from what you’ve built though. It’s super cool and I plan to dig deeper into it. I see some clever ideas lurking. My idea is a bit pedestrian in comparison.
I say that I view convo as more of a discovery because it was really just the realization that the model already maps all programming constructs to a sort of pseudocode internally anyway. When you ask the model to translate JavaScript-> Python, the model has to first map the code from JS to some abstract internal representation which it then maps into Python. My observation was that the starting point for such a transformation can be any language which means that you can also start with pseudocode. And what’s great about pseudocode is that your programs can be much more succinct and there’s no rigged syntax or grammar so while you can have logic problems in pseudocode it’s impossible to have syntax problems.
I’m working on a project that uses Claude to dynamically create powerpoint presentations and this entire project:

The source files, package.json, tsconfig.json, .env, .gitignore, and README.md files were created from this convo file as a seed:
Section: Initialize Presentation Generation
To initialize presentation generation:
Load stored api_key from a secure source.
Read the contents of "topic.txt" into a variable called presentation_data.
Read the contents of "theme.json" into a variable called presentation_theme.
Read the contents of "templates.json" into a variable called slide_templates.
Set up the system prompt as follows:
```
<CONTEXT>
Date: ${current date in ISO format}
<PRESENTATION_THEME>
${presentation_theme}
<SLIDE_TEMPLATES>
${slide_templates}
<PRESENTATION_SCHEMA>
{"title":"<presentation title>","layout":"wide","sections":[{"id":"<section_id>","title":"<section title>","slides":[]}]}
<PRESENTATION_INSTRUCTIONS>
Long lists should be split across multiple slides to avoid being truncated.
Markdown blocks only support bulleted & numbered lists, bold, and italics.
<PRESENTATION_DATA>
${presentation_data}
```
Define an empty JSON structure called presentation_schema that follows <PRESENTATION_SCHEMA> format.
Initialize presentation_schema with a title of "Generated Presentation", layout "wide", and an empty sections list.
Section: Generate Presentation Outline
To generate presentation outline:
Define a user message saying:
"Let's create a presentation for the provided PRESENTATION_DATA as a JSON object that follows the PRESENTATION_SCHEMA. We'll use the PRESENTATION_INSTRUCTIONS and the provided PRESENTATION_THEME and SLIDE_TEMPLATES when generating slides. Before creating the presentation, let's start by creating an outline of the presentation we want to create."
Call "send message to Claude with model 'claude-3-5-sonnet-20241022', using message content that returns text" with the user message.
Capture the response from Claude as outline_text.
Add outline_text to the conversation history.
Note: outline_text serves as a guide for Claude's slide generation in subsequent steps.
Section: Slide Generation Loop
To generate all slides:
Define a variable called completed with a value of False.
While completed is not True, perform the following steps:
If this is the first iteration, define a user message saying:
"We'll need to create the presentation in chunks. Let's start by creating the first set of slides as a complete presentation object. Return <DONE> after the last section is returned."
Otherwise, define a user message saying:
"Return the next set of slides as a complete presentation object. The slides will be merged into the existing presentation. Return <DONE> after the last set of slides is returned."
Call "send message to Claude with model 'claude-3-5-sonnet-20241022', using message content that returns JSON" with the user message and conversation history.
Capture the JSON response from Claude as slide_chunk.
Check if the response contains "<DONE>":
If "<DONE>" is found, set completed to True.
Remove "<DONE>" from slide_chunk to clean the JSON.
Extract the "sections" list from slide_chunk and append each section to the "sections" list in presentation_schema.
Add the JSON response from Claude (slide_chunk) to the conversation history as:
"```JSON\n<slide_chunk JSON>\n```"
Section: Save and Convert
To save final JSON and convert to PPTX:
Write presentation_schema to a file named "output.pptx.json".
Call convertToPptx("output.pptx.json", "output.pptx").
Note: This function converts the JSON schema to a PowerPoint file using predefined logic.
Section: Re-Generate PPTX from Existing JSON
To regenerate PPTX from existing JSON:
Check if "output.pptx.json" exists.
If it exists,
Load "output.pptx.json" into presentation_schema.
Call convertToPptx("output.pptx.json", "output.pptx").
Display "Regeneration complete. The file output.pptx has been updated."
Otherwise,
Display "Error: output.pptx.json not found. Please run the presentation generation process first."
Section: Main Program Flow
To create presentation from input files:
Check if the "--regenerate" flag is passed as a command line argument.
If "--regenerate" flag is passed,
Call regenerate PPTX from existing JSON.
Otherwise,
Call initialize presentation generation.
Call generate presentation outline.
Call generate all slides.
Call save final JSON and convert to PPTX.
Display "Presentation generation complete. The file output.pptx has been created."
Section: Claude Sonnet Model Calls
To send message to Claude with model "claude-3-5-sonnet-20241022", using message content that returns text:
Make an HTTP POST request to "https://api.anthropic.com/v1/messages".
Set headers to:
x-api-key as stored api_key,
anthropic-version as "2023-06-01",
content-type as "application/json".
Set the body of the request to:
```
{
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 8182,
"system": "<system prompt>",
"messages": [
{"role": "user", "content": "<user message>"},
... conversation history
]
}
```
Return the response from Claude.
To send message to Claude with model "claude-3-5-sonnet-20241022", using message content that returns JSON:
Make an HTTP POST request to "https://api.anthropic.com/v1/messages".
Set headers to:
x-api-key as stored api_key,
anthropic-version as "2023-06-01",
content-type as "application/json".
Use the "assistant prefill" support of Claude to condition to return JSON.
Set the body of the request to:
```
{
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 8182,
"system": "<system prompt>",
"messages": [
{"role": "user", "content": "<user message>"},
{"role": "assistant", "content": "```JSON"},
... conversation history
]
}
```
Parse the response by extracting everything up to the closing ``` and then parse as JSON.
Return the response from Claude.
The conversation history should be updated to include the returned JSON object formatted as "```JSON\n${object}\n```"
I ran Sonnet in an agentic loop to design the project and then write all of the files. I just compiled things and fed errors and bugs back into sonnet for debugging. It took an hour or two but Sonnet got everything to a working state without me having to directly touch a line of code. I ended up re-writing its logic for parsing JSON responses from the model to be less brittle but the bulk of the code Sonnet wrote and thanks to the convo program i gave it as input it was super close functionality wise on the first shot.
Here’s an example of the types of presentations it can generate…

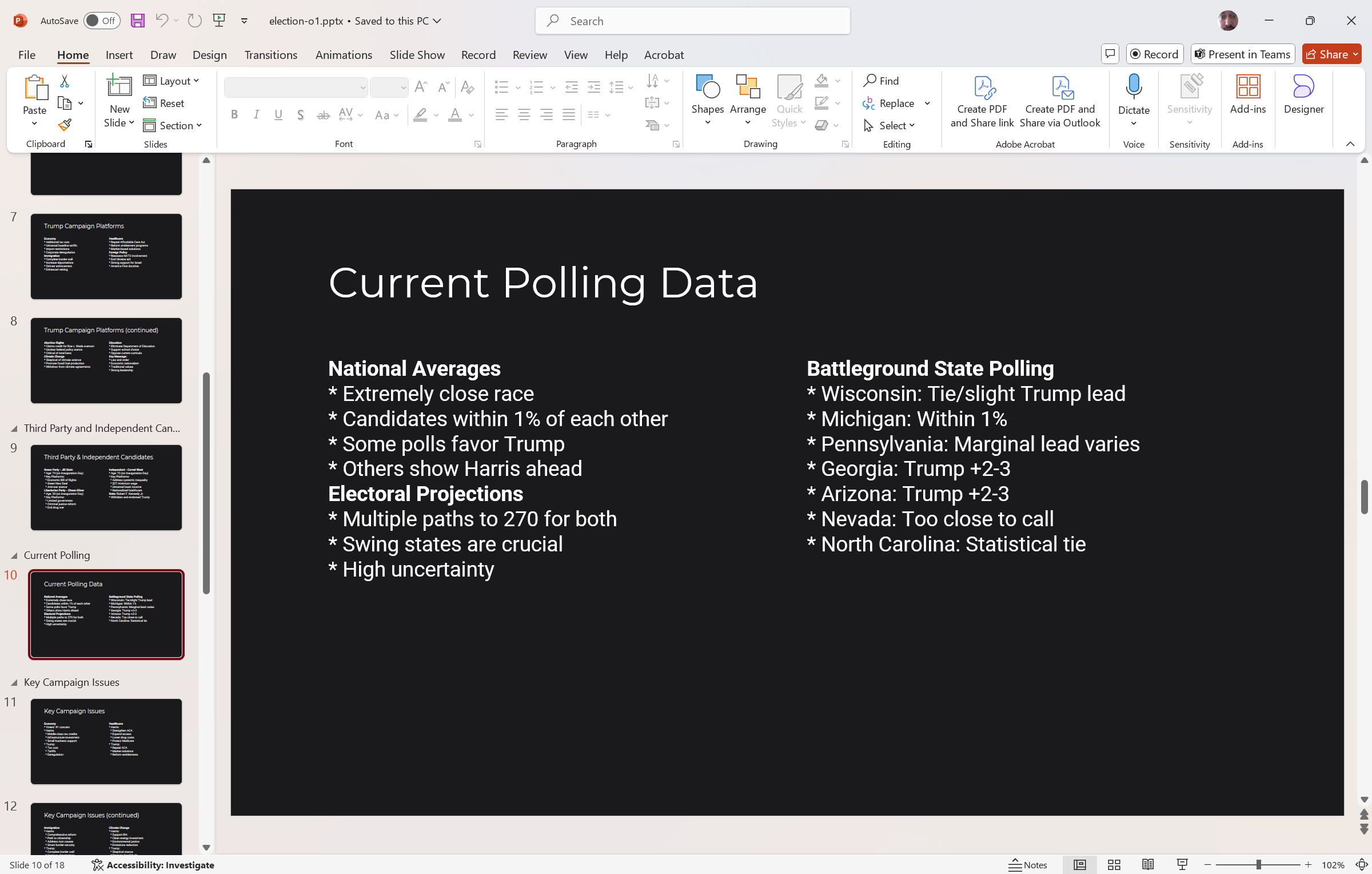

I just simply asked for a presentation to update me on the elections. ** The data comes from my reasoning engine, Awareness. This is just a new artifact projection for that data.
Thank you for the complement, I sincerely appreciate it.
After looking more at what you have been working on I think the two version of Convo could work really well together. I have been more focused on the plumbing of working with LLMs and less on the actual content of the messages being sent, where you have been more focused on guiding the actual response of an LLM in a very interesting multi-step transformation workflow.
I would be very open to collaboration if you’re interested.
Looks very interesting. Any reason why the licensing is GNU?
I’m assuming that’s targeted at @convo-lang . The license for Convo is Creative Commons.
@icdev2dev, I kinda just picked one at random when I started the project last year. What would you guys suggest?
@convo-lang a more permissive, MIT /Apache ?
@stevenic yes, that was directed to convo-lang.
I think that both of the approaches can work very well in practice
@icdev2dev I think I’ll switch to the Apache license
@stevenic and @icdev2dev, I put together a YouTube video of using Convo-Lang in a NextJS app. Let me know what you think.

3 Likes
Your setup reminds me of Gaia online. Back in the day it was a anime fan forum with collectible avatars and accessories.

There is something about isometric pixel art that just makes me happy inside ![]()
1 Like
It brought back found memories for me. I dabbled in Gaia, second life and IMVU doing mesh work really back in the day though used 3DMax back then for my polygon frames and paint. Net for my art.
There is another project with the same idea of using a pseudo code GitHub - paralleldrive/sudolang-llm-support: SudoLang LLM Support for VSCode
1 Like
Hi, I need an AI tool that can:
(1) accept uploaded content (like PDFs or Word files),
(2) summarise key points into clear bullet points,
(3) structure slides that work with the TAPPLE method (Teach, Ask, Pause, Pick, Listen, Effective Feedback), and
(4) include animations to engage students better. E.G. Question, followed by the answer faded in, or in a table - Key Words with their definitions and an image that reflects the meaning.
Are you aware of an AI tool or workflow that automates this process effectively?
Any suggestions or advice?
1 Like