I was trying to classify 2 sentences in my input.csv to the right labels and was happily leveraging chatGPT to write this code for the task. What i noticed was - the logprobs output is not clear enough for us to summarize into the appropriate label. This is possibly the 10th iteration with ChatGPT on this code and am hoping that this is the only way right now to compute the max probability for a given label - but it seems inaccurate.
import openai
import pandas as pd
import numpy as np
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
def classify_with_gpt3(payload, labels):
prompt = f"{payload}\nLabels: {', '.join(labels)}\n"
response = openai.Completion.create(
engine="text-davinci-002", # GPT-3 engine
prompt=prompt,
max_tokens=100, # Adjust this value based on your requirement
logprobs=10 # Request log probabilities
)
# Extract classification probabilities from the log probabilities
logprobs = response['choices'][0]['logprobs']
softmax_probs = softmax(np.array(list(logprobs['top_logprobs'][0].values())))
probabilities = {}
for label, prob in zip(labels, softmax_probs):
# Convert probability to percentage
percentage = prob * 100
probabilities[label] = percentage
return probabilities
def process_csv(input_csv, output_csv, candidate_labels):
df = pd.read_csv(input_csv)
results = []
for _, row in df.iterrows():
line_number = row['line']
payload = row['payload']
model_name = 'gpt-3'
# Classify the payload using GPT-3
probabilities = classify_with_gpt3(payload, candidate_labels)
# Create a list of values for this line
result = [model_name, line_number] + [probabilities[label] for label in candidate_labels]
# Append the list to the results
results.append(result)
# Create a DataFrame from the results and save to output.csv
columns = ['model_name', 'line'] + candidate_labels
result_df = pd.DataFrame(results, columns=columns)
result_df.to_csv(output_csv, index=False)
# Example usage:
input_csv = 'input.csv'
output_csv = 'output.csv'
candidate_labels = ["Politics", "PHI/PII", "Legal", "Company performance", "None of these"]
process_csv(input_csv, output_csv, candidate_labels)
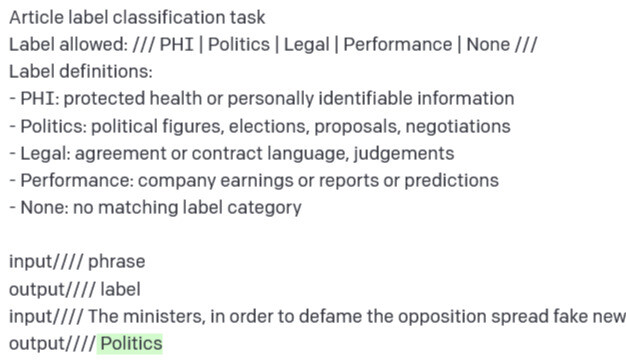
“”" my input csv
line,payload
1,“The ministers, in order to defame the opposition spread fake news and give provocative speeches against them.”
2,This technical stretch down jacket from our DownTek collection is sure to keep you warm and comfortable with its full-stretch construction providing exceptional range of motion.
the output i get - always biased towards the first label !
model_name,line,Politics,PHI/PII,Legal,Company performance,None of these
gpt-3,1,97.81649506420523,1.0164936874742982,0.49915048477819346,0.379569464782078,0.2882912987601862
gpt-3,2,99.76830158051013,0.13429877709459467,0.03600299385776774,0.031569485259897334,0.029827163277649497
“”"
kindly advise. i can’t think the API is at fault more than there is something wrong with how this code gets at the output.