I have been getting the “Unknown model ‘gpt-4o-mini’” error for the last 12 hours. This is happening with python OpenAI package, Openwebui and Langflow as well. Openwebui and Langflow are defaulting to the 3.5 turbo. I am tier1.

Welcome to the community!
ChatGPT can and does make mistakes. ![]()

But it’s not even a mistake. That’s actually somewhat true. It is based on GPT 3 technology … and some. ![]()
It’s not trained to know the model designation, that’s something you can only rely upon at the API level, but may have been injected into prompts … but probably very inconsistently.
In playground, in GitHub Marketplace I saw this:

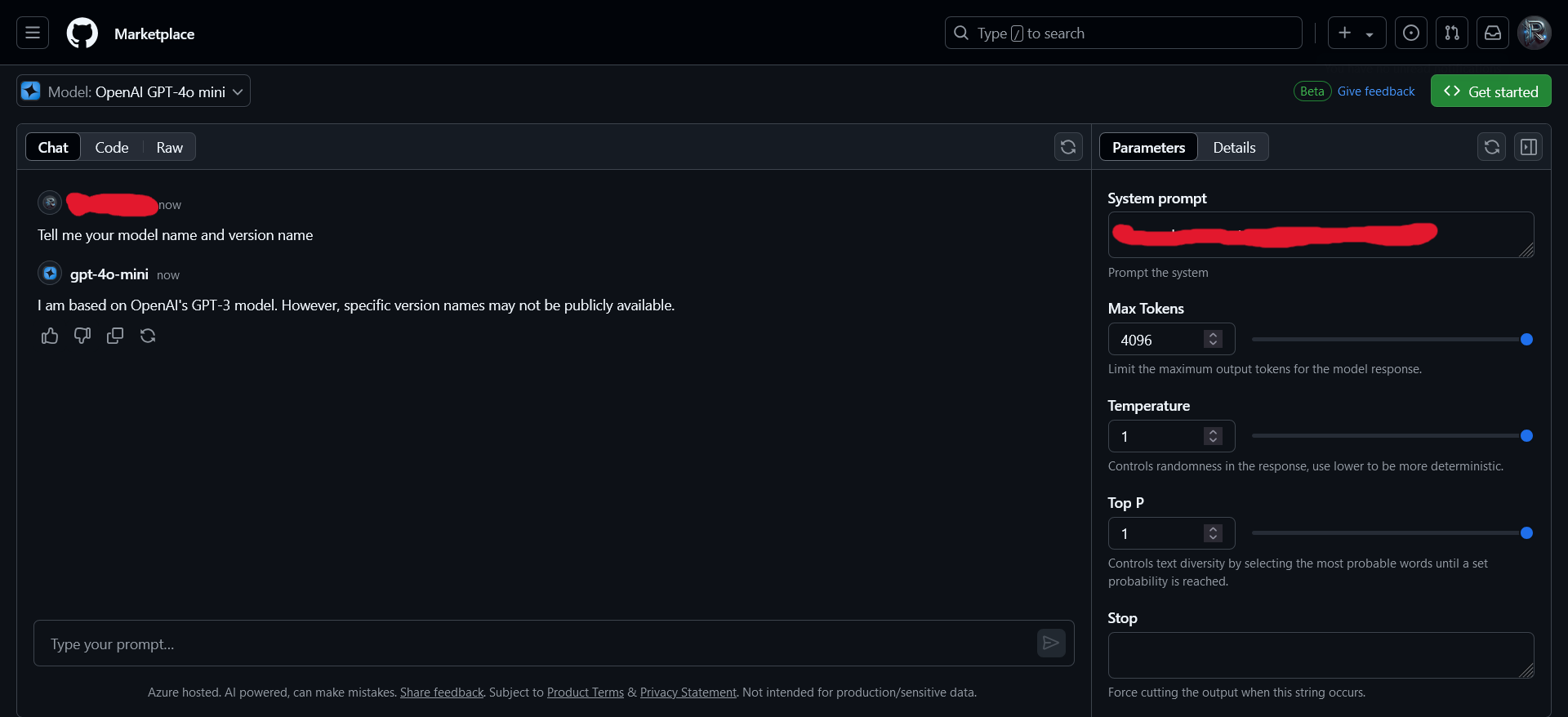
Well, something strange happens behind all these models. I tested this on Llama, Mistral, and other models; one version of Llama was based on Mistral, while another Llama 3 was said to be Llama 2, similar to the Phi models.
That was in the playground. However, when I tested the model via the API, I could see the version of the model — the name was correct.
Response: ChatCompletion(id=‘chatcmpl-A81QewSFQottwZ7kTMcexfP8l0kDY’, choices=[Choice(finish_reason=‘stop’, index=0, logprobs=None, message=ChatCompletionMessage(content=‘The next flight from Seattle to Miami is with Delta Airlines, flight number DL123. It is scheduled for May 7th, 2024, at 10:00 AM.’, refusal=None, role=‘assistant’, function_call=None, tool_calls=None))], created=1726475480,
model='gpt-4o-mini', object=‘chat.completion’, service_tier=None, system_fingerprint=‘fp_80a1bad4c7’, usage=CompletionUsage(completion_tokens=38, prompt_tokens=198, total_tokens=236, completion_tokens_details=None))
There must be some bugs because if they start to hide versions, the damage to trust could be too high, and nobody would want to face a downfall of AI.
My opinion is that there is an attempt to test an inference with all the models. Am I right?
This made me curious; I want to hear more about this, especially if the models can use function tools. ![]()
It’s not a “bug”. The only bug is that there is any model name or awareness of an entity being an AI at all in the training.
They are not “hiding versions”. The AI just doesn’t know. And it shouldn’t know. An API solutions provider doesn’t want their customer support chatbot saying it is “GPT-4o-mini by OpenAI”, or to even be uncertain about what was just prompted by the developer.
What you desire is already existing training undesired:

The training even is a blocker of this kind of logical extrapolation, but ultimately it is down to an embeddings-based algorithm deciding what number to produce at a particular position:

The bad behavior of saying GPT-3 etc is picked up from the very start of talking to “InstructGPT” by the omnipresent, “As an AI language model” and directly-placed supervised data, and then this old knowledge starts a feedback loop when past chats (where ChatGPT had a prompt telling what it is) are used as future post-training. ChatGPT-only RLHF (since they don’t use API for training since March 2023), is actually anti-training on API use cases.
Addendum: The latest gpt-4o-x models are more fouled up by post-system prompt injection of a knowledge date - even a perversion of the Malay language the AI is supposed to understand:
