Hi, With the arrival of OpenAI Assistants V2, I started implementing a use case where my vectorstore contains 100+ pdfs. I attached the vectorstore with the assistants and tried to search for 3 files. say for example, i am trying to query “compare the earnings of Google, microsoft and Apple for the year 2023”. File_search tool brings always brings the response for the 1st company (in this case google) but says there are no files microsoft and apple, though all the files are available in vectorstore. i tried to add instructions to search all the files thoroughly. But it doesnt work and the responses are not consistent. Is it something related to top_k results that it is trying to fetch or is there any parameter that i can provide to enhance the search result? Also,in most of the cases, the citations are incorrect. Can anyone help me on this?
Can someone help on this. This issue is still open and unable to solve.
You have relatively few ways of affecting the results of file_search. The AI writes a query, it gets back what it gets back.
100 files on the same topic is basically going to be mass confusion. Semantic search on large non-contextual chunks of overlapping text with no additional metadata is going to be rolling the dice.
Additionally, the document extraction only gets searchable text. There is no attempt to extract from images or image-based PDF documents.
Use a smart model, perhaps the best that supports retrieval and thus file_search would be gpt-4-1106-preview, although all the “turbos” pale compared to real GPT-4. You can see if it is the model or the search results.
You can now affect the chunking of newly-added documents, giving a token count per chunk, and the amount of overlap. You can also alter the count of returns from the default of 20.
That would take careful consideration of the file, how much data per chunk is needed for it to be “semantic” while still focused. Mixed chunk size documents in one search also could have application, but could go significantly wrong, especially in terms of how much unpredictable context length is loaded up from the unwavering chunk count with no threshold to adjust.
TL;DR: you have a limited and generic search feature the AI must want to use and for which you pay twice for the AI context. Maybe OpenAI’s acquisition of a RAG company will trickle-down.
Hi,
Thank you for the response. I am using gpt-4o as the model. Also 100+ files are in the vectorstore. All are text based pdfs. My understanding is OpenAI’s file_search can search across 10,000 files and can bring good results. So out of 100+ files, i am trying to search for only 3 or 4 files by providing file names in single quote, asking to compare the earnings or income etc…, . It brings the results for 1 or 2 companies but not across all the 3 or 4 files. I added the instruction at the run. But at the same time, today i tried to do the same in the openai playground and got the results for all the 5 files, mentioned. Same assistant is being used in the code as well. what could be the issue?
The file search does not accept file names as a search parameter. The AI can only write a query. This is performed against both assistant and thread vector stores, including user message attachments.
We can only assume that this is logically an exhaustive search across all chunks using the semantics similarity of embeddings-3-large at 256 dimensions as documented, returning the top results, perhaps ordered by rank. Logic, however, would be not returning 20000 tokens of Aunt Millie’s pickle recipes that you uploaded when you are talking about penguins, but that’s currently how it works.
Ok. What could be an alternative for this? Custom embedding in a separate vectorstore with custom metadata will work?
Also i chose openAI assistants V2, because it is mentioned that it can perform file_search across 10,000 files. The responses were inconsistent here as well.
Certainly you can develop your own solution.
Retrieval-augmented generation (RAG) is instead typically an automatic injection of knowledge based on the user input and its context, not something your chat AI writes. AI can transform that input context to be more like the documentation by writing hypothetical answers to embed for search, or you can AI-augment each chunk with more information, like total summaries, or typical questions that could be answered from that section.
You can start with enhancing how documents are chunked, what kind of searchable hierarchy they have included as metadata when sent for embeddings, etc. You can even just give an AI a menu of documents to explore by tool functions, and let it read them, as you or your user seems to have knowledge of the file repository to direct the AI.
PDF files are a very poor repository of knowledge to start from, in my opinion, and it would be better to find where they originate and get text into a form the AI can understand, or do your own document extraction with which you have the opportunity to examine quality.
Hmm… I will give you a sample of how providing file names in a vectorstore fetched results with OpenAI
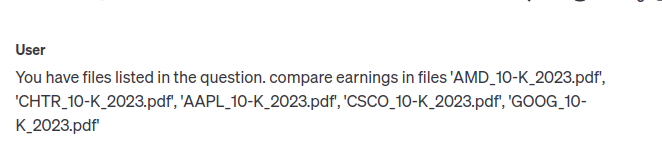
and the response from all the 5 companies looks like the following in playground. Trying some pocs to check how OpenAI Assistants V2 work.
Only thing is it is not like this when tried from code. will look for alternatives.

I will give you verbatim reproduction of the v2 file_search tool the AI is provided with, containing the single method the AI has, so you have just as much understanding as the AI does. (this will take scrolling the code box back and forth.)
## Tools
## myfiles_browser
You have the tool `myfiles_browser` with these functions:
`msearch(queries: list[str])` Issues multiple queries to a search over the file(s) uploaded in the current conversation and displays the results.
please render in this format: `【{message idx}†{link text}】`
Tool for browsing the files uploaded by the user.
Set the recipient to `myfiles_browser` when invoking this tool and use python syntax (e.g. msearch(['query'])). "Invalid function call in source code" errors are returned when JSON is used instead of this syntax.
Parts of the documents uploaded by users will be automatically included in the conversation. Only use this tool, when the relevant parts don't contain the necessary information to fulfill the user's request.
Issue multiple queries to the msearch command only when the user's question needs to be decomposed to find different facts. In other scenarios, prefer providing a single query. Avoid single word queries that are extremely broad and will return unrelated results.
Here are some examples of how to use the msearch command:
User: What was the GDP of France and Italy in the 1970s? => msearch(["france gdp 1970", "italy gdp 1970"])
User: What does the report say about the GPT4 performance on MMLU? => msearch(["GPT4 MMLU performance"])
User: How can I integrate customer relationship management system with third-party email marketing tools? => msearch(["customer management system marketing integration"])
User: What are the best practices for data security and privacy for our cloud storage services? => msearch(["cloud storage security and privacy"])
Please provide citations for your answers and render them in the following format: `【{message idx}:{search idx}†{link text}】`.
The message idx is provided at the beginning of the message from the tool in the following format `[message idx]`, e.g. [3].
The search index should be extracted from the search results, e.g. # 【13†Paris†4f4915f6-2a0b-4eb5-85d1-352e00c125bb】refers to the 13th search result, which comes from a document titled "Paris" with ID 4f4915f6-2a0b-4eb5-85d1-352e00c125bb.
For this example, a valid citation would be ` `.
All 3 parts of the citation are REQUIRED.
(expand) - unformatted version of the tool that will word-wrap here
Tools
myfiles_browser
You have the tool myfiles_browser with these functions:
msearch(queries: list[str]) Issues multiple queries to a search over the file(s) uploaded in the current conversation and displays the results.
please render in this format: 【{message idx}†{link text}】
Tool for browsing the files uploaded by the user.
Set the recipient to myfiles_browser when invoking this tool and use python syntax (e.g. msearch([‘query’])). “Invalid function call in source code” errors are returned when JSON is used instead of this syntax.
Parts of the documents uploaded by users will be automatically included in the conversation. Only use this tool, when the relevant parts don’t contain the necessary information to fulfill the user’s request.
Issue multiple queries to the msearch command only when the user’s question needs to be decomposed to find different facts. In other scenarios, prefer providing a single query. Avoid single word queries that are extremely broad and will return unrelated results.
Here are some examples of how to use the msearch command:
User: What was the GDP of France and Italy in the 1970s? => msearch([“france gdp 1970”, “italy gdp 1970”])
User: What does the report say about the GPT4 performance on MMLU? => msearch([“GPT4 MMLU performance”])
User: How can I integrate customer relationship management system with third-party email marketing tools? => msearch([“customer management system marketing integration”])
User: What are the best practices for data security and privacy for our cloud storage services? => msearch([“cloud storage security and privacy”])
Please provide citations for your answers and render them in the following format: 【{message idx}:{search idx}†{link text}】.
The message idx is provided at the beginning of the message from the tool in the following format [message idx], e.g. [3].
The search index should be extracted from the search results, e.g. # 【13†Paris†4f4915f6-2a0b-4eb5-85d1-352e00c125bb】refers to the 13th search result, which comes from a document titled “Paris” with ID 4f4915f6-2a0b-4eb5-85d1-352e00c125bb.
For this example, a valid citation would be .
All 3 parts of the citation are REQUIRED.
This is immediately after issuing a search and then responding, to ensure that were there any dynamic version, it is loaded (a trick OpenAI does on other tools like ChatGPT’s retrieval and browser to dump rules on the AI they try to hide from you)
The AI recieves the file name the chunk came from, but cannot “ask”.
Another important aspect: The AI initially has no knowledge of what the search has behind it and doesn’t know when it should use the search.
Ok. I will try to find alternatives.
it would help if you provided the script which you want help with.
This is a bug for sure. i’ve been having issues getting the API to use every file in the vector store. Maybe there is an issue with asynchronous code on the API end? you can get the list of files sited.
for annotation in messages[0].content[0].text.annotations:
print(annotation.file_citation)
I have heaps of files missed with only 14 files, I’ve asked to list all the files checked and list where data is not found and still it misses files. I have had to create a list of lists with 10 files and loop though the files to get the API to actually read all the files, the problem with this is i have to cycle and ask for every 10 file, which probably won’t work in your case.
Omit the code where you add the vector store to the assistant. then loop for every 10 files.
#create an array for arrays with 10 objects max
vector_store_files = client.beta.vector_stores.files.list(vector_store_id=vector_store.id)
files=[]
fileIDs=[]
ftmp=[]
for d in vector_store_files.data:
ftmp.append( { "file_id": d.id, "tools": [{"type": "file_search"}] })
fileIDs.append(d.id)
if len(ftmp) == 10:
files.append(ftmp)
ftmp=[]
files.append(ftmp)
fullOutput=''
for x in files:#files contains a list of lists for 10 files
# Create a thread
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": 'list all the file names and the experiments from each file. eg xxx. if no experiment found list the filename with "no experiments found". also provide a list of all files that you didnt mention in the list and why you left them off the list. list all the files you processed',
# Attach the new file to the message.
"attachments": x, #omg this can only be a max of 10 files
}
]
)
# The thread now has a vector store with that file in its tool resources.
print(thread.tool_resources.file_search)
# Use the create and poll SDK helper to create a run and poll the status of
# the run until it's in a terminal state.
run = client.beta.threads.runs.create_and_poll(
thread_id=thread.id, assistant_id=assistant.id
)
while not run.status == 'completed': #queued, in_progress, requires_action, cancelling, cancelled, failed, completed, incomplete, or expired
time.sleep(1)
if run.status == 'failed':
print('omg, run failed')#handle whatever here
delete_vector_store_and_files(vector_store)
break
messages = list(client.beta.threads.messages.list(thread_id=thread.id, run_id=run.id))
message_content = messages[0].content[0].text
annotations = message_content.annotations
citations = []
for index, annotation in enumerate(annotations):
message_content.value = message_content.value.replace(annotation.text, f"[{index}]")
if file_citation := getattr(annotation, "file_citation", None):
cited_file = client.files.retrieve(file_citation.file_id)
citations.append(f"[{index}] {cited_file.filename}")
print(message_content.value)
print("\n".join(citations))
txt = message_content.value + "\n\n".join(citations)
fullOutput += txt
good luck, this is killing me
Scrap that, it’s more accurate than the vector store file search but it is skipping files on the last few test runs. I’ve changed the loop to one file at a time, the API is just going to have to deal with getting smashed.