We’ve improved image generation in the API. Editing with faces, logos, and fine-grained details is now much higher fidelity with features preserved. Edit specific objects, create marketing assets with your logo, or adjust facial expressions, poses, and outfits on people. A guide on getting started: Generate images with high input fidelity.


Fantastic!
Would we expect this to improve “mask editing” performance? (e.g., more like a ‘hard mask’ than ‘soft’?)
No changes to masking today (although we’re working on overall improvements)!
I have no doubt you are ![]() Sounds good, thanks for the response and keep up the great work over there.
Sounds good, thanks for the response and keep up the great work over there.
This is only regarding the edits endpoint, and concerns the vision input.
It costs more for the “vision” part of the image input used for replication, as now described:
For GPT Image 1, we calculate the cost of an image input the same way as described above, except that we scale down the image so that the shortest side is 512px instead of 768px. The price depends on the dimensions of the image and the input fidelity.
Conventional input image charges, then:

When input fidelity is set to low, the base cost is 65 image tokens, and each tile costs 129 image tokens. When using high input fidelity, we add a set number of tokens based on the image’s aspect ratio in addition to the image tokens described above.
- If your image is square, we add 4096 extra input image tokens.
- If it is closer to portrait or landscape, we add 6144 extra tokens.
More precisely, the additional cost per image is then:
- exactly square: $0.041
- non-square: $0.062
(“closer to portrait” is very fishy language when it comes to billing expectations)
Thus doubling the cost of a single image input, medium quality generation at 1024x1024 in/out. Or tripling cost with two input images.
Incredible.
If someone asked me if this was going to be possible 2 years ago, I would say “absolutely not”.
Props to the OpenAI team.
@edwinarbus Well done - already using it…
There does appear to be a relationship between input_fidelity and mask editing, as follows:
If you set input_fidelity to ‘high’ and use a mask, the mask seems to allow the model to deviate more from the original input image within the area of the mask.
See the examples in the uploaded collage (which you may want to view and enlarge in a separate tab).

The images on the right were generated with high input_fidelity. Without a mask, the model apparently tries to change the wife into a Southeast Asian woman whose face resembles that of the original wife. With an editing mask, the model seems to be freer to generate various examples of Southeast Asian women’s faces.
I’ve seen a similar pattern in analogous cases, including one with image quality set to ‘high’.
It’s unclear how general this pattern is, and the behavior of the model is likely to evolve during the next few weeks and months. But some developers may already find it worthwhile to take this possible pattern into account.
With DALL-E 2, there are these mask options, where a transparency mask is the ONLY place an image can be edited.
- RGBA 32 bit PNG, where the alpha channel has pixels of pure opaque or pure transparent (0 or 255)
- A separate mask file that is RGBA, but only the alpha channel is considered, as if it was included in the input image as 32 bit.
Without a mask, it should have been impossible to alter the image, but that is not the way it works.
gpt-image-1 completely disobeys mask hinting and cannot provide anything unedited and not a re-creation. It also disobeys that an image should only be changed where there is a mask. OpenAI has not been forthcoming about the internal prompting and presentation of inputs and mask to the model (especially the context input of the Responses tool) so that one can target the actual way the image model is used.
The gpt-image-1 model should have been put on a new edit endpoint without any of the previous nomenclature or parameters.
You should try this with a mask that does not affect the RGB. It seems you also have deleted the original face, and replaced it with white. If so, the AI has no choice but to come up with a new face. Perhaps you’d get the equivalent by merely painting over the face with white and not using mask at all…
What I want to know: since you get only billed 4k or 6k tokens additional regardless of the input size, with that token count indicating “patches” of 1024x1024 or 1024x1536 → what is the actual resizing being done, is there also upscaling to fit, and how is it padded out so that “closer to square” works on an image that is still rectangular? What is the optimum and maximum useful image that can be sent? (without “high fidelity”, it is pointless to send a lossless wide image taller than 512px, for example).
For clarity, I reaffirm that the editing mask mentioned in my previous post is transparent in the places that look white in the collage; and that it was submitted alongside the input image as the value of the “mask” parameter (the original image being the value of the “image” parameter).
But it’s true that you can get a similar result by painting over the parts that you want changed instead of providing a mask for them. In the collage below, the editing mask from the previous examples was submitted as the value of the “image” parameter, without any editing mask; and the same prompt was used as before. The results look similar to those achieved with the image + editing mask combination in the sense that, in both cases, the model appears not to have tried to imitate the facial features of the original wife (which would have been impossible in this latest case, since the original image was not supplied via the API).

A couple of photos I took at my brother’s wedding around 20 years ago:


Prompt to combine the above photos: “Use the figures in both images to create a new image such that each of the eight figures are sitting at a wedding banquet table enjoying lunch.”

Not bad, but the image was a bit too dark, so prompt: “Increase the brightness of the image”

Been getting distorted images lately…but that’s another subject.
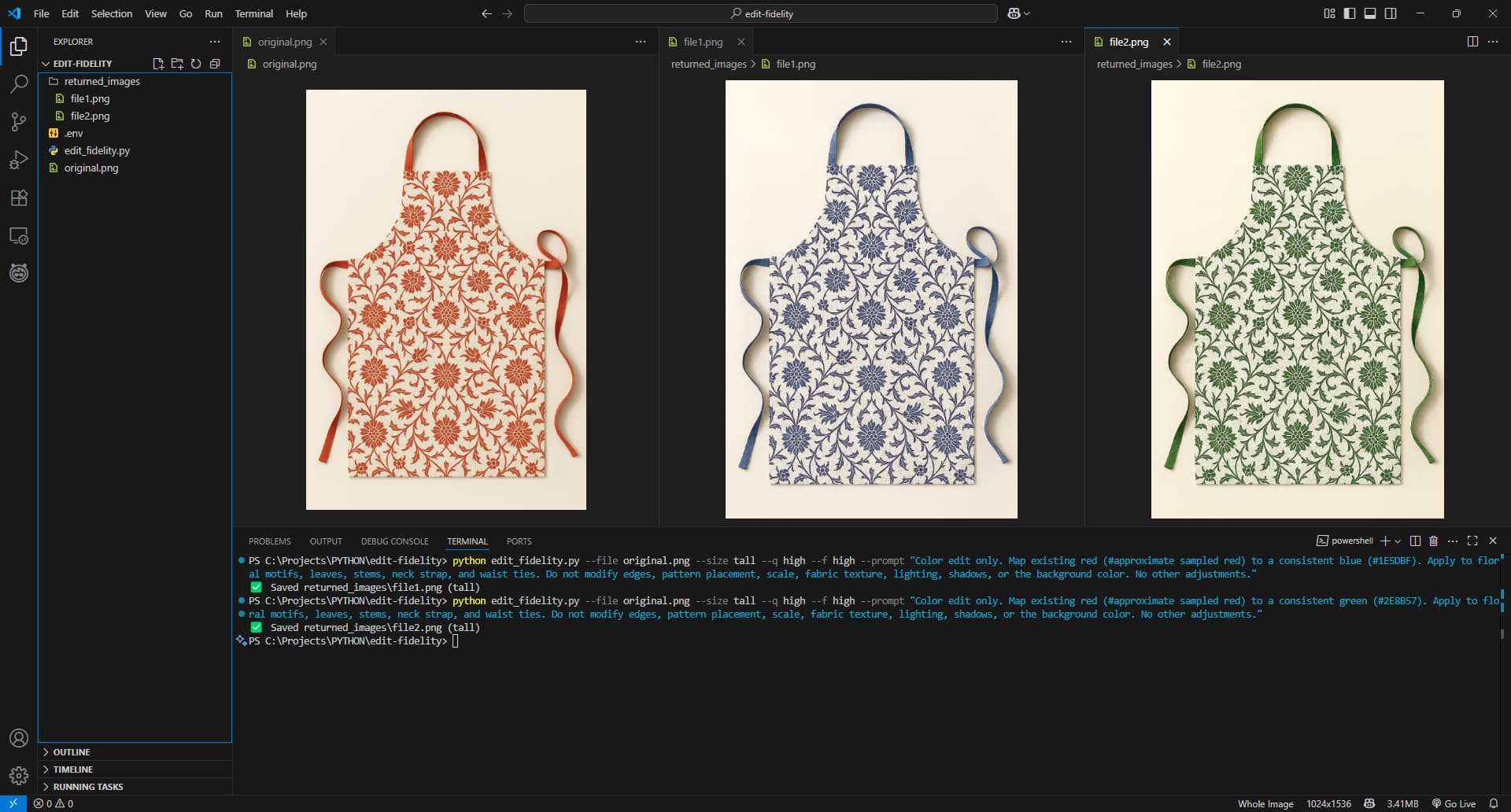
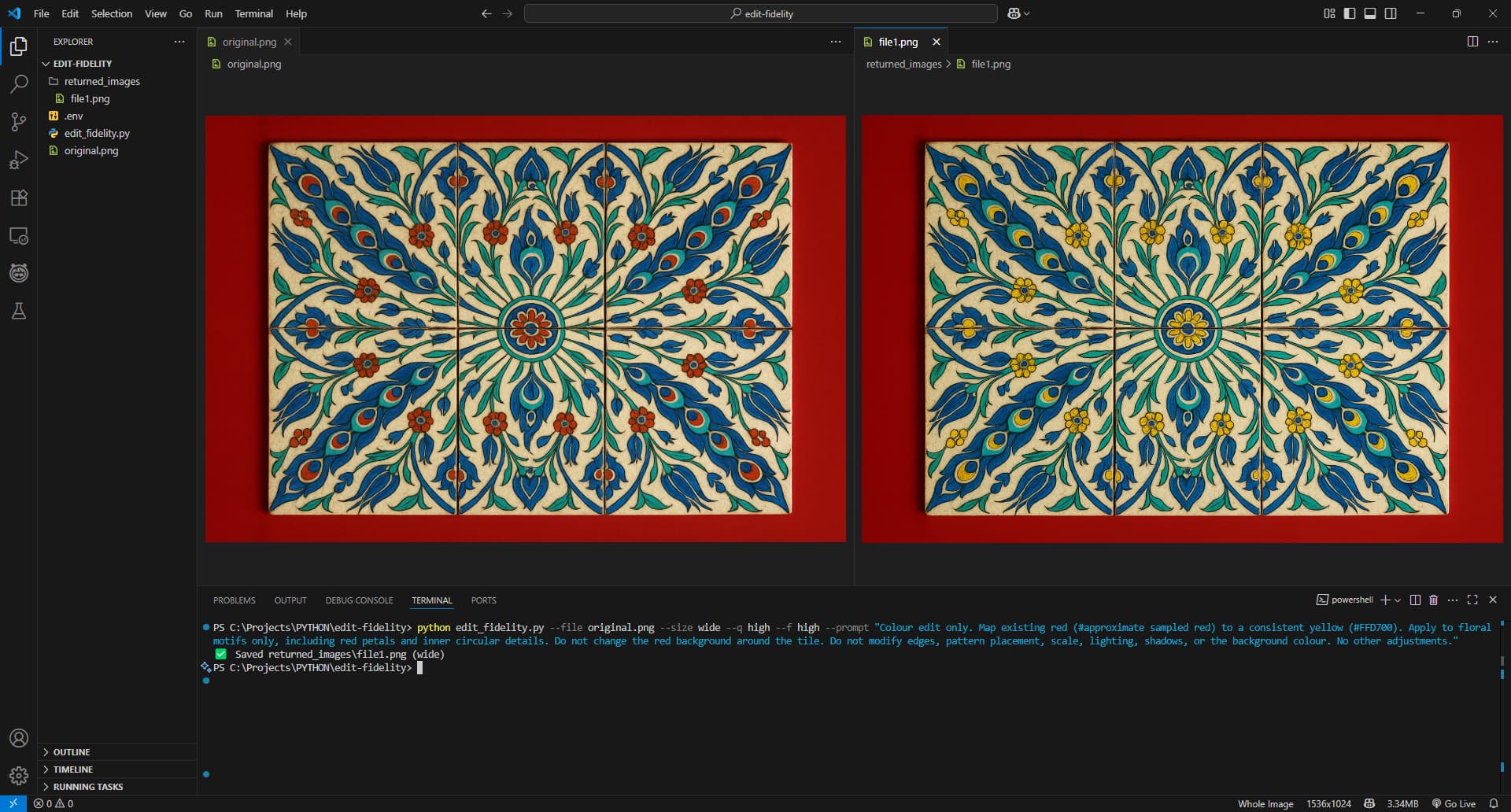
Color Change Results with input_fidelity="high"
Changing only one color tends to work best, even on complex patterns.





Object Removal Tests
Removing multiple objects at once works fairly well, but results aren’t always perfect.

Multi-Step Edits
Doing changes in multiple steps gives good results for the first and second edits, but quality drops after the second step.

Do you guys think it’s worth competing with Adobe Photoshop for “selection and masking tools”? Everything this conversation can be more simply accomplished if ChatGPT is pulled into Adobe rather than trying to reproduce their selection tools (and I think their “firefly” now uses OpenAI anyway).
It’s just a thought, either way you’ll end up with an Adobe-like suite of tools.
**
@edwinarbus High fidelity imaging is amazing! It’s most excellent that y’all are addressing logo consistency, I’m excited to try it.
I don’t yet see a more precise way of controlling fonts?
A brand is basically a set of logos and two major font families. To be effective for marketing, a designer will need exact control over the logo positions and the fonts—which I (at least) usually get through a combination of Adobe and Google at the moment.
It would be amazing if we could enable a Agent or a flow with a specific, custom, font—rather like one might attach a vector store. That way, we could use the same font whether building a web page in html or a branded image.
And what about anything on the horizon for vector graphic / .svg output?
right, that’s what I’ve experienced too. I’m wondering if anyone has found a way to make two-pass prompt work? The first pass is great! I just need the second pass to not be “pointillized” (like all statics-y). Anyone found any method to successfully do that? The process is using pass 1 image to generate pass 2 image. I tried generating a transparent mask (or a face transparent mask but the rest surrounding is opaque) for it, but no luck.
Also, I tried the " Fashion & Product Retouching" but I’ve noticed that it’s all backwards. Meaning, you cannot upload the target user and the image of the item of clothes that you want the target user to wear. Instead, you describe the item of clothes to prompt and it generates it so it can be worn on your target user. But isn’t that all wrong for the user journey of ANY EC vendor? Don’t they have the clothes and accessories that they want the user to try on already? Shouldn’t the process be upload the target user + target tryon item, then use prompt to generate the exact piece of item on the exact user? Has anyone cracked that code yet?
Let’s try that assertion you make, where we DO have to do the work of describing each element and the new composition.
# user inputs
PROMPT = """
The first image is me (asian woman) in a pink dress.
The second image is another model wearing a light paisley dress and top.
The third image is a satin cover-up top.
Produce a new image where I am wearing the dress from the second image and the top from the third image.
"""
INPUT_PATHS = [
"input-woman.jpg",
"input-dress.webp",
"input-top.jpg",
] # add more paths as needed
OUTPUT_FILE = "me-in-dress.png"
Additional parameters to the API:
params = {
"model": "gpt-image-1",
"prompt": PROMPT.strip(), # text prompt
"quality": "high", # "high" | "medium" | "low"
"size": "1024x1536", # "1536x1024" | "1024x1536" | "auto"
"output_format": "png", # "png" | "jpg" | "webp"
# "output_compression": 95, # lossy jpg/webp only (0‑100)
"background": "opaque", # "opaque" | "transparent"
"input_fidelity": "high", # extra cost for better copying
"stream": "false", # "true" streams chunks
#"user": "myCustomer",
}
url = "https://api.openai.com/v1/images/edits"
I’ll pay the extra $0.18 for these three input images at high fidelity, which might as well be accompanied by $0.25 for the high quality output option.
Input Images



Result
Paid once, with a request taking over the 60 second timeout, not getting the result. Increased that significantly higher.
Result 2

Looks like the trick is to describe each Image and how to coordinate each image - makes total sense.
But the blouse you are wearing (Result 2) is not light pink.
“Me” in this case is only the highest usage right and consent you can offer to the AI to fulfill the image and not press its “400 server error” button on your prompt.
It could be a case of the AI vision having a “blue or gold dress” moment, based on the context of the input image, as there could be unknown color balance or lighting temperature issues.
The error is a growth opportunity, for your application’s “edit this prompt” feature.
And the demonstrated application: perhaps the first real version of the movie trope “what shall I wear today” computer app.
