That forum topic is about the edits endpoint.
This discusses generation itself.
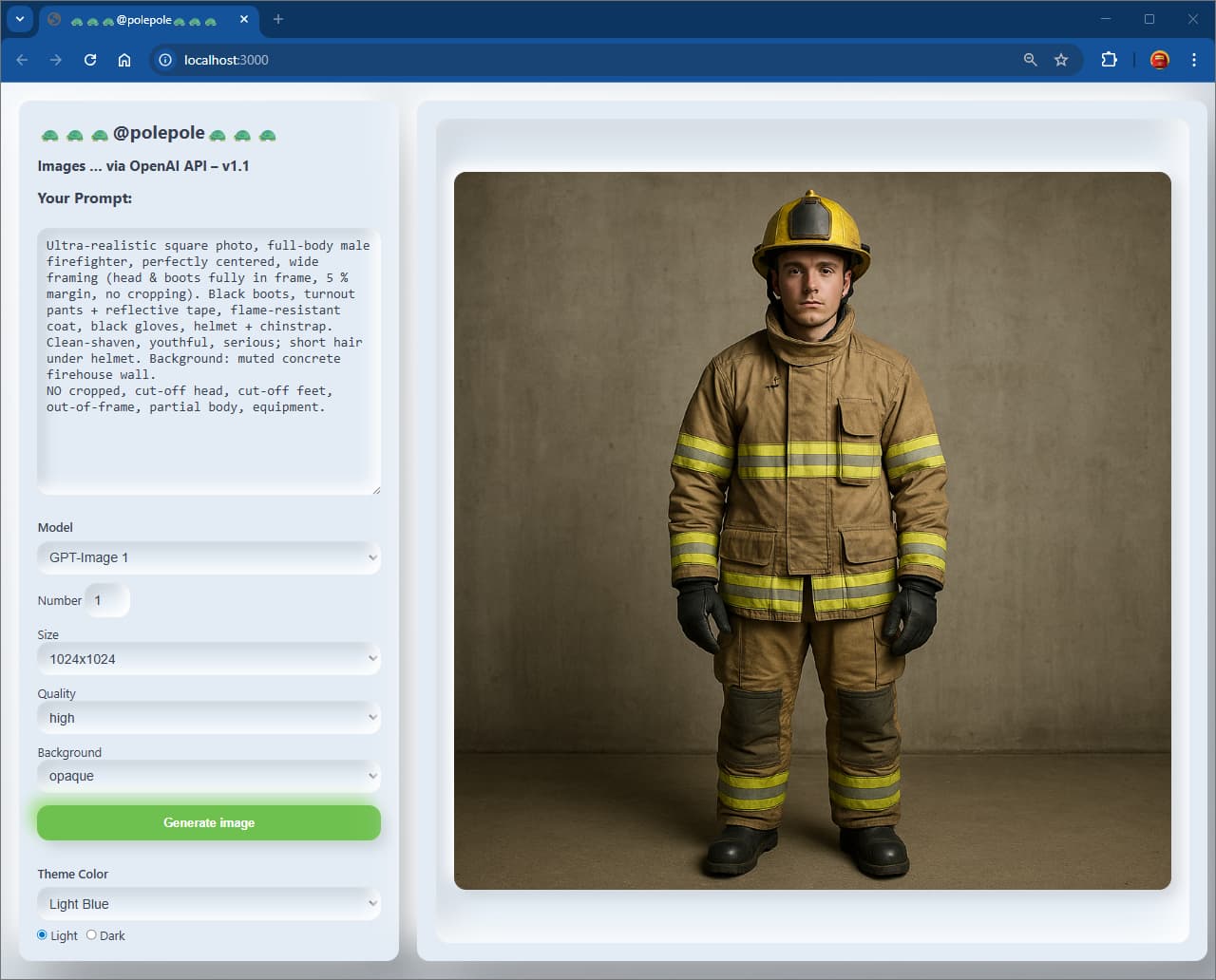
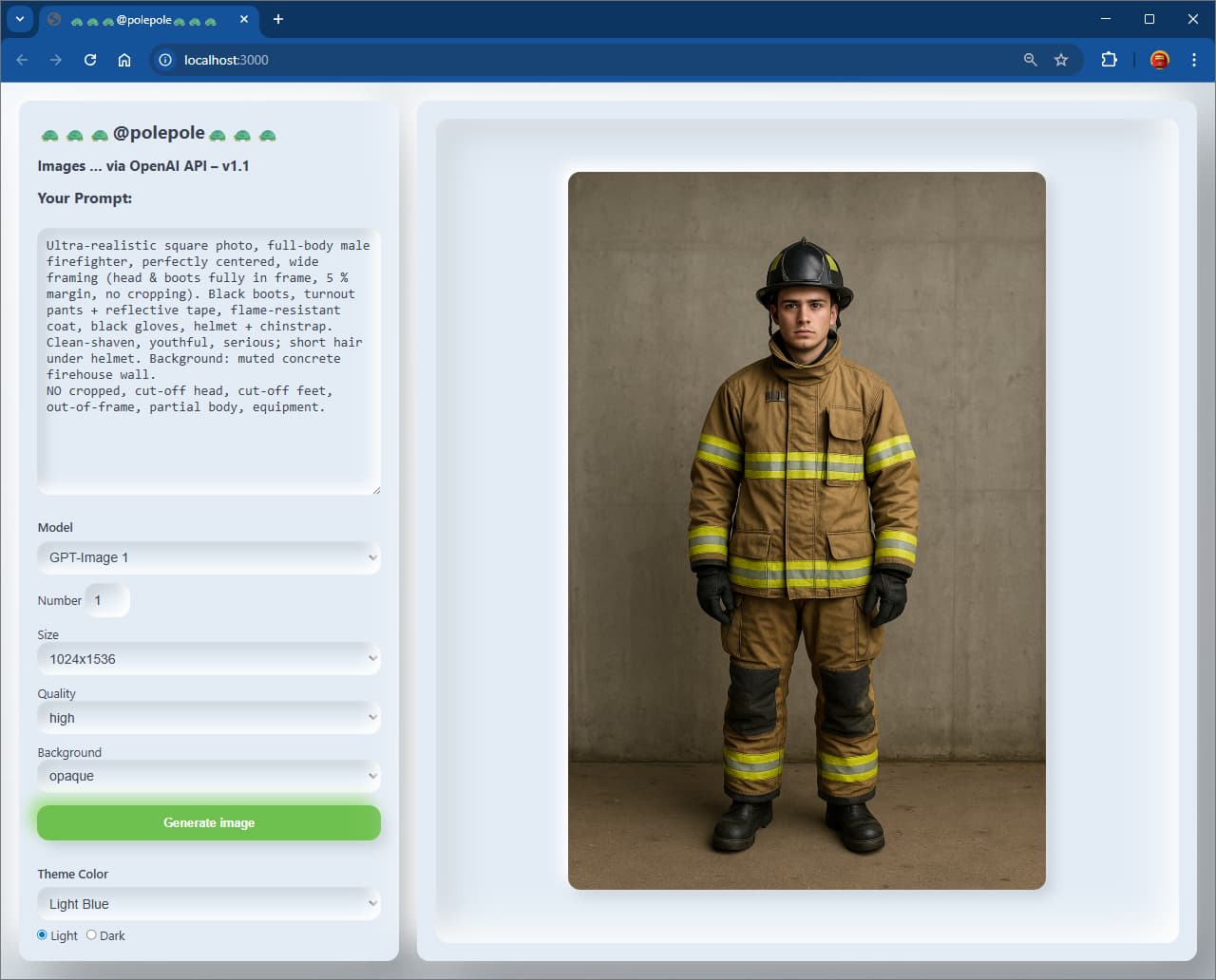
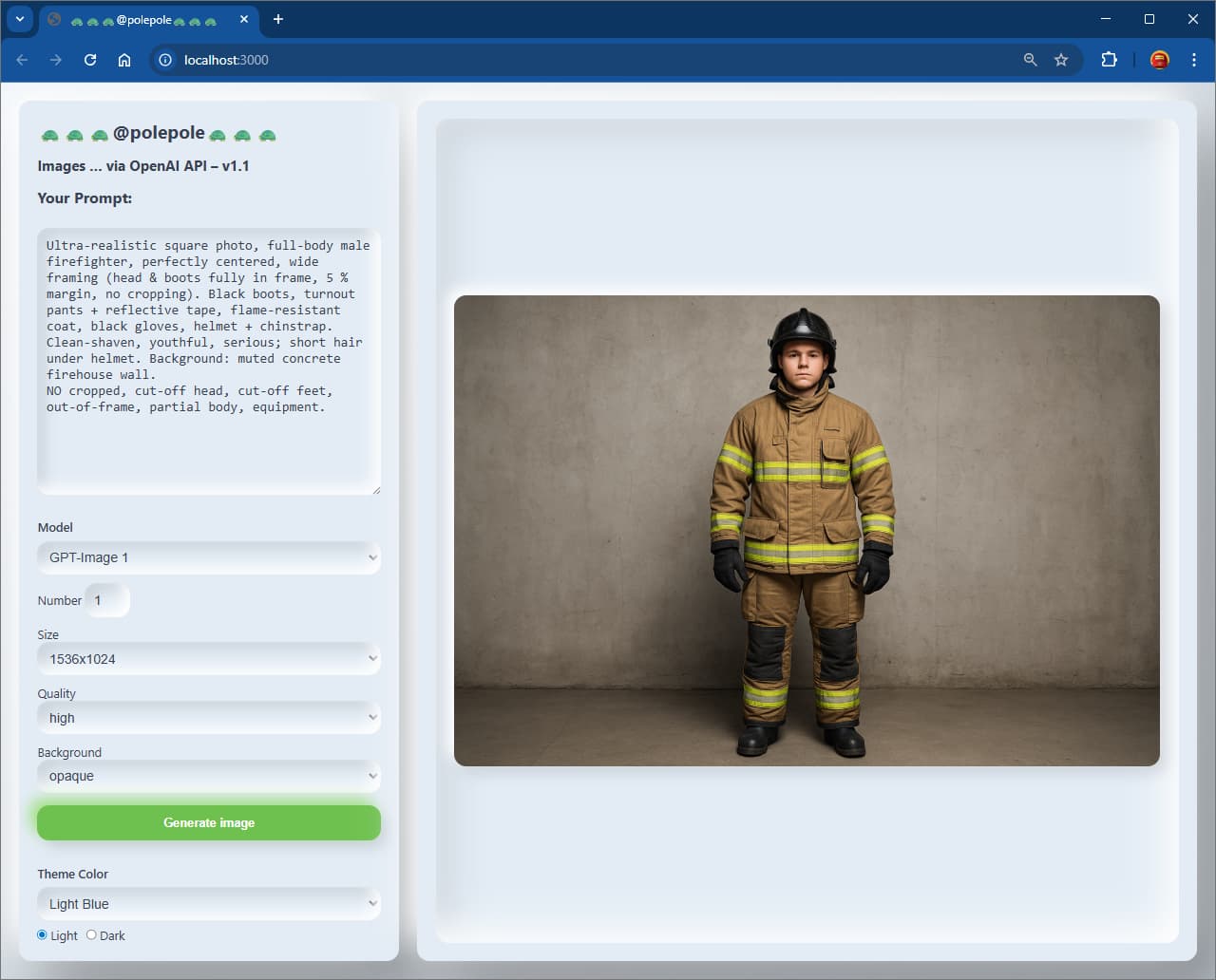
The release notes written by OpenAI do indicate this “issue” of being too zoomed in when generating images, still there since release.
This is likely because there wasn’t separate post-training on each aspect ratio. The AI anticipates and predicts the length of the image, but then goes wrong when constrained. DALL-E 3 also has a similar issue, where you often get square images with truncation that anticipate expanding on either side that never comes when you use 1024x1024.
The strongest way to overcome this is to imagine that when you make an API request for a 1024x1024 image, that the AI has in mind a tall or wide image that it will create for you depending on the subject, for tall, at 1024x1536, where you then only get the center of it.
You have to prompt your way into having more space above and below the subject described in your prompt, more background field that needs to be displayed on either side with contents, or actual object in the “virtual” extra space above and below the person, to receive a final square that is even beyond requesting “zoomed out” or “from a distance” to obtain the goal.
I find the user input technique of requesting side-by-side duplicates works best for tall things.
Image size and framing:
A square image that is split into two halves side-by-side. One half on the left shows the person or character facing us in front profile as the primary image, and on the right half, the person is shown viewed in side profile.
Image contents of each pane:
A photorealistic studio fashion portrait of a tall, slender young woman with fair skin and long, straight platinum blonde hair, parted neatly and flowing smoothly down her back. She has soft, symmetrical facial features, bright eyes, and a warm, natural smile. Her makeup is subtle but polished—light foundation, soft pink lip gloss, gentle eye shadow, and well-defined brows. She wears a fitted, sleeveless mini dress made of rich burgundy satin that reflects light with a smooth sheen. The dress has a clean, elegant cut with a modest V-neckline and tailored waist, flaring slightly at the hem to flatter her silhouette.
She stands confidently on high-heeled black ankle-strap sandals that complement the outfit’s elegance. Accessories are minimal and tasteful: small gold stud earrings and a delicate gold bracelet. The lighting is bright, diffuse, and shadow-free, typical of a high-end fashion catalog shoot. The background is a seamless, clean white sweep with no distractions, ensuring the subject and outfit remain the visual focus. The overall aesthetic is stylish, modern, and professional—ideal for a luxury lookbook or seasonal fashion editorial.
At least she’s not beheaded by the API, but the AI ran out of token output space:
Adding:
Caution: you must zoom out in each image, as if viewed from a distance, and predict the extended height and space needed to show people head-to-toe.