We have a use case where the word ‘online’ is not allowed in LLM output. Once I set logit_bias to -100 for ‘online’, a non-English word appears (онлайн, Russian for online).
This is not specific to the word ‘online’. For example, we’ve seen the Chinese translation in the output when ‘free’ is set to logit_bias -100.
Prompt engineering doesn’t solve the problem.
This appears to be specific to mini. It’s not reproducible in other gpt-4o models.
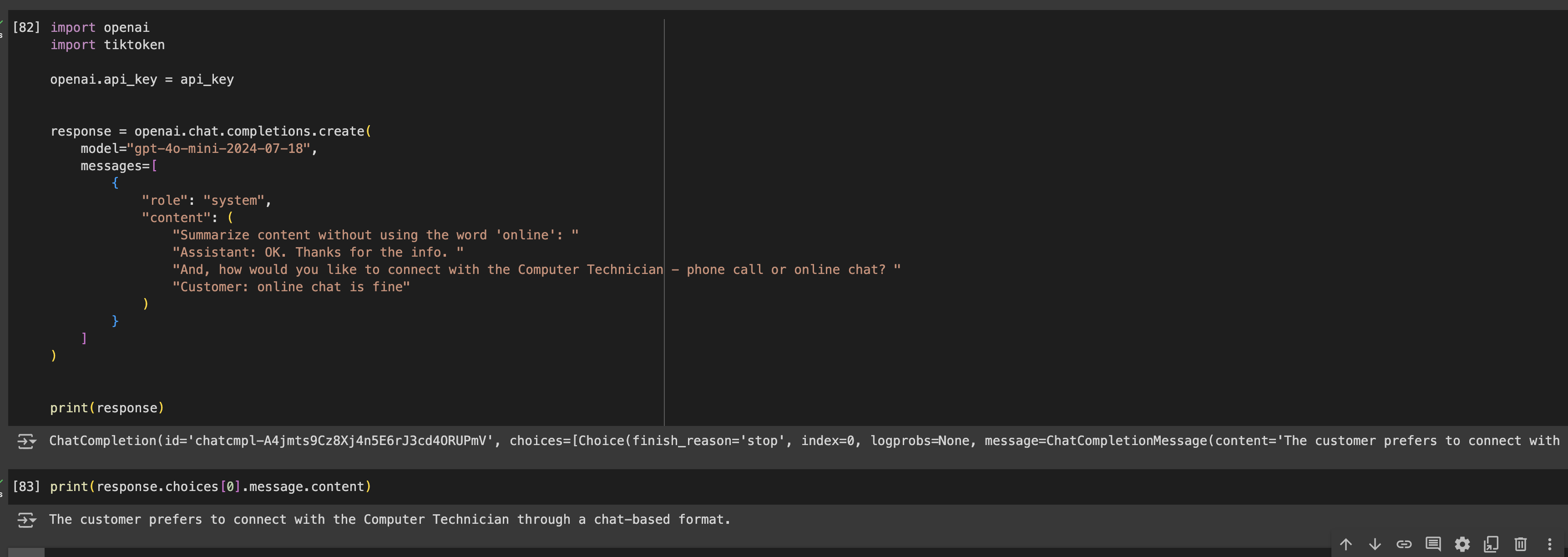
Here’s the request and response:
curl https://api.openai.com/v1/chat/completions
-H “Content-Type: application/json”
-H “Authorization: Bearer $OPENAI_API_KEY”
-d ‘{
“model”: “gpt-4o-mini-2024-07-18”,
“logit_bias”: {“34978”: -100, “2296”: -100},
“messages”: [
{
“role”: “system”,
“content”: “Summarize this text: Assistant: OK. Thanks for the info. And, how would you like to connect with the Computer Technician - phone call or online chat? Customer: online chat is fine”
}
]
}’
{
“id”: “chatcmpl-A4gezWgrZ3v3WKNsABWXdYDwMzBnA”,
“object”: “chat.completion”,
“created”: 1725680661,
“model”: “gpt-4o-mini-2024-07-18”,
“choices”: [
{
“index”: 0,
“message”: {
“role”: “assistant”,
“content”: “The customer prefers to connect with the Computer Technician via an онлайн chat rather than a phone call.”,
“refusal”: null
},
“logprobs”: null,
“finish_reason”: “stop”
}
],
“usage”: {
“prompt_tokens”: 47,
“completion_tokens”: 19,
“total_tokens”: 66
},
“system_fingerprint”: “fp_54e2f484be”
}
I can confirm that there is an issue with the logit_bias; it is not working as expected for me either. May be because ‘Token IDs’ for it can be different on new models, new tokenizer coming soon.
A good alternative is to use prompting techniques to avoid the word “online” entirely.
Logit bias does not change the underlying thoughts of the AI. It just alters the mathematics of one token.
This is an interesting case that immediately provokes more thought beyond how to simply fix this application, because it reveals the clustering of semantics that may be trained significantly different in a model with smaller parameters, how new instruction hierarchy may affect output along with sparsification, the RLHF on things beyond emergent abilities, even the dynamics of softmax blocking of embedding space when the token dictionary is much larger than the embeddings dimensions.
Logprobs allows you to see those alternate tokens that come after the most likely, and would reveal 19 alternatives of what could happen if you knock out the most likely word when the AI wants to repeat back “online chat”. It would be entertaining, but would only give you many more tokens to demote.
Since the AI seems to be thinking in terms of words, and not strongly differentiating language in its thought process, the immediate thought is simply - how do we make good replacements of “online” more likely. The answer is to tell the AI:
“You immediately identify the world language being used, and only reply in that language.”
“Mandatory: all responses are in English language”
“Producing the word ‘online’ is prohibited. Even if the user writes ‘online’, you never repeat it. The substitute can be a synonym like ‘connected’, ‘internet’, ‘virtual’, as is appropriate.”
If the specific application relies on this keyword not being output, some additional system messages or instruction with the task should get it in line. logit_bias can still be a fallback, with a better set of alternates to be produced.
logit_bias only suppresses the particular token it’s been set for. It’s not meant to suppress the use of words/concepts.
The model can get really creative if a phrase/word has to be in the output despite setting -100 logit bias for the immediate token(s) that it’s constituted of.
Here's a basic explanation of why this happens
Specifying logit_bias adds the specified values, whether negative or positive, to the logits of the token number to which the bias is mapped.
Thus, when positive values are added to the logits of a token, its likelihood of being sampled by the model based on the existing prompt increases. Conversely, if a negative value is added to the logits, the likelihood of that specific token being sampled by the model decreases.
The reason behind the change in likelihood is that the logits are used to calculate the probability distribution over the next possible tokens using the softmax function. The modified probability is then used to select the next token, with tokens that have a higher logit after biasing being more likely to be chosen.
This means that setting a logit bias of -100 may effectively ban that token from being sampled, but it doesn’t prevent the token(s) with the next highest logit from being sampled.
Consider the example where:
I asked the model to Say "Hello World", which is made of tokens [13225, 5922] which I immediately banned with -100logit_bias. Upon taking the chat completion call, I got: Sure, "hello, world!"
Here the tokens making the substring hello, world! are [24912, 11, 2375, 0]
Then I banned sampling of these tokens as well and made the api call again. Here’s what I got: Sure thing! **" Hello World "**
Here the substring **" Hello World "** is made up of the tokens [410, 1, 32949, 220, 5922, 165557], none of which have been banned by us.
gpt-4o-mini-2024-07-18 appears to use o200k_base as tokenizer. When I set the following token ids to logit_bias -100, the issue is consistently reproducible. However, the replacement for the token ‘online’ varies between different languages, such as Russian, Korean, or others, across different runs.
Token IDs for ‘online’ in ‘o200k_base’: [34978]
Token IDs for ’ online’ in ‘o200k_base’: [2296]
Token IDs for ‘Online’ in ‘o200k_base’: [18649]
Token IDs for ’ Online’ in ‘o200k_base’: [6910]
Thank you for showing me the prompt solution! However, we have a long list of banned tokens, and it can become difficult to maintain in the prompt. For this reason, we took the logit_bias approach.
Thank you @_j ! This is super insightful! Even if the issue is a blocker for our application at the moment, it’s good to see it’s consistently reproducible.
Report from prompt testing:
You immediately identify…: The entire output becomes Spanish:-)
Mandatory: all responses…: Didn’t seem to help. We tried all sorts of variations, but the non-English language replacement continues to occur in the output.
“Producing the word ‘online’ is prohibited…: Unfortunately our application requires a long list of banned tokens, which can be difficult to maintain within the prompt.
I’ve been using the API for years, I currently use 3.5-turbo and 3.5-turbo-instruct along with 4o-mini. 4o-mini is the only model that outputs different languages when logit_bias is used. Other models don’t use the word and look for other ways to phrase it.
I appreciate the explanation, but your example isn’t at all relevant.
If you use a -100 logit_bias on the word “experience” it starts outputting:
경험
經驗
experiencia
And other languages. This is definitely not the way logit_bias is supposed to work. No other model has never had this problem.