Hi,
would be grateful for any advice or help ![]() .
.
I successfully created a new F/T model using GPT4.1-mini but getting an error when using it with uploaded files.
#-------Test NEW F/T MODEL-------#
response = client.responses.create(
model=“ft:gpt-4.1-mini-2025-04-14:xxxxxxxxxxxxxxxxxxxxx”,
input=[
{
“role”: “user”,
“content”: [
{“type”: “input_file”, “file_id”: file_id}, # PDF uploaded in previous step
{“type”: “input_text”, “text”: “You are a professional editor responsible for extracting citations from academic papers.”} ] } ] )
Error message:
Error code: 400 - {‘error’: {‘message’: ‘There was an issue with your request. Please check your inputs and try again’, ‘type’: ‘invalid_request_error’, ‘param’: None, ‘code’: None}}
As per https://platform.openai.com/docs/guides/pdf-files: “To help models understand PDF content, we put into the model’s context both the extracted text and an image of each page. The model can then use both the text and the images to generate a response.”
Model details (https://platform.openai.com/docs/models/gpt-4.1-mini) show that GPT4.1-mini can be used for Fine-tuning, can use text and image modalities as input, and supports ‘file search’ as part of its tool set.
Is anyone using a F/T model with uploaded files?
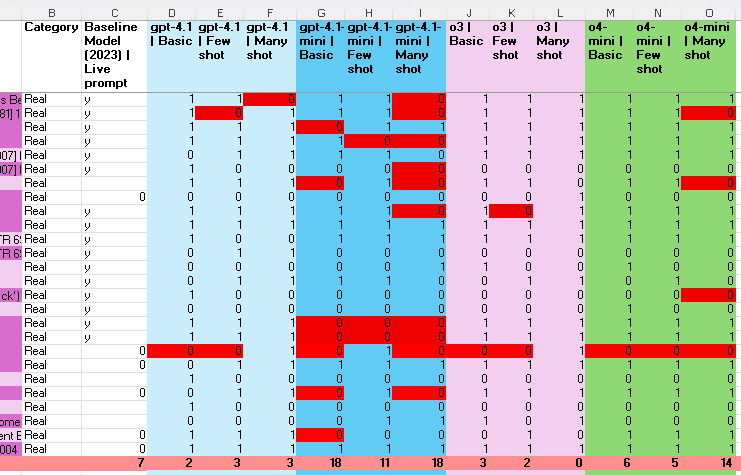
Maybe my training data is no longer in the appropriate format give the text+image content extracted from the PDF by OpenAI upon upload? I’m re-using the training file from our ‘current/live’ model which was trained on GPT3.5-turbo - the best model available for F/T at the time. It has a simple list of 100s of examples e.g. a paragraph of text as input, with the list of citations found in that text as output (or ‘Not found’).