Welcome to the discussion thread for the “Foundational must read GPT/LLM papers” topic! This is your space to dissect, debate, and delve deeper into the papers mentioned in the main thread. Perhaps you’re grappling with some complex concepts in a paper, or you’ve stumbled upon an intriguing idea that you’d like to explore further. Maybe you have real-world experiences that confirm or contradict the theories proposed. Whatever your thoughts or questions, this is the place to share and learn together. As we navigate this rapidly-evolving field, remember, the goal isn’t just to keep up with the literature, but to enhance our collective understanding and further the discourse. All insights are welcome. Let’s engage, challenge, and inspire each other to push the boundaries of our knowledge on GPT and Large Language Models.
It’s an interesting paper, but it looks like an attempt to lay claim to a fairly simple idea. Interleaving requests to authoritative material and reasoning about them improves the accuracy of responses.
Did it really require a paper? I’m also deeply skeptical about results beyond - this seems to work better in some situations.
We have a discord where I’ve provided some extensive examples of this, but one technique I’d like to see is a ‘paper’ or at least a blog about is just having GPT4 provide alternative responses and then pick the best one. The advantage of this approach is that it can be applied to any q/a and evaluation would be straightforward.
It’s a fairly simple idea and hopefully a paper has been written on it. GPT4 wasn’t much help, so it’s probably been written since cutoff.
I feel like a lot of LLM papers suffer from this issue, but what may be obvious for us as developer’s who spent a long time playing with LLMs might not be well described in the litterature.
I could argue as a physicist and say that all of Einstein’s special theory of relativity is just common sense applied to the Michelson–Morley experiment. But this knowledge wouldn’t have been widely available to someone without a background in Physics.
There’s many, many requirements to writing a good scientific paper and only one of them is having an idea, the rest is a lot of hard work describing, testing and providing results. My biggest requirement is always “can the reader replicate the results?”
I liked the ReAct paper because they provided enough information and explanation for me to replicate their results, they have a GitHub if you want to play with it yourself:
If you want I can also post my own implementation using GPT-3.5 (the original paper used DaVinci)
I think the ReAct paper is a good place to start for people who want to know more about “agent’s” without throwing their API key at something like AutoGPT
Fair enough, and don’t get me wrong, it’s a great idea. Many great ideas are often quite simple in retrospect.
I suppose my biggest issue is I just don’t believe the paper.
Well, directionally I do, but it really feels like one of those papers ‘great, it seems to work, now let’s make up some math so people will think we understand why it works and will cite it and we can say it was our idea.’
I guess I’ve just read too many of those papers and have become overly cynical.
It’s fine to be sceptical even cynical when trying to “review” a paper, that’s what this thread is for
From my experience the methods shown in the react paper does improve the responses I get, it does really well at chained tasks like “find x information and do y calculation considering c” but it has a high failure rate on question that are loosely defined.
Here’s an example of what I’m talking about: I gave the agent the task “write about your own abilities”
In the first attempt it responded “I am an AI who can read Wikipedia and do calculations”
(This is true, I gave it access)
In the second attempt it found the wiki on psychic abilities, filled it’s context window with nonsense and responded “I have psychic abilities…”
Researchers have created a new kind of recurrent neural network (a type of artificial intelligence model) that operates continuously over time. Instead of using typical methods to define how these networks change and learn, they built them using a combination of simple linear systems and nonlinear gates. The special thing about these networks is that their behavior changes fluidly over time. When they run these networks, they use mathematical methods to calculate the results. These new neural networks show stable behavior, can represent complex patterns better than other similar networks, and are better at predicting sequences of data. The researchers have used both theory and practical tests to show that these “Liquid Time-Constant Networks” (or LTCs) perform better than other common types of neural networks, especially when predicting sequences.
In my opinion, this research offers immense potential for physical systems like walking robots and self-driving cars, but I doubt it will outcompete large language models when it comes to predicting text sequences.
I think it’s how brains work, so while it’s not suitable right now due to the increased computation required per neuron, it might be in the future. It’s fine to be running 19 neurons like this for a driving controller, running 150 billion for a full brain like structure is a decade or more away computationally.
Perhaps a hybrid?
I’m definitely more for the hybrid approach, doing stuff like this for a whole brain seems very inefficient, I think a lot of neurons would have no benefit from the flexibility this method provides
Yup, a lot of this is going to come to down neuromorphic study, it could well be that the brain just duplicates very complex neurons because that’s an easy evolutionary path but it carries no computational advantage.
One thing that I think might be super interesting to explore is the use of a liquid NN to set attention for a traditional transformer… maybe even dynamically allocating attention, not sure how you build the bridge from text to liquid NN’s though… If I were a 20 something again, I think I’d pick this area to go into.
I think the idea behind that paper is pretty interesting, but their testing methodology seems… Non standard, and I don’t really understand why it was chosen.
A good way to stay up to date on papers that are of interest to you. Find some papers that are very well cited that talk about your particular topic, and use reverse citation on google scholar and then sort by date.
Eg, I’m interested in RAG and this paper is one of a few is that is very well known and would likely get cited by something I’m interested in.
The latest reference architecture I have floating in my head is basically use a blend of embeddings and keywords, with extensive use of HyDE to steer the query.
Yeah, getting llm to generate keywords is hugely important. But hyde is just a very narrow start of that, imho. The topic around that I believe is much vaster.
Dense:
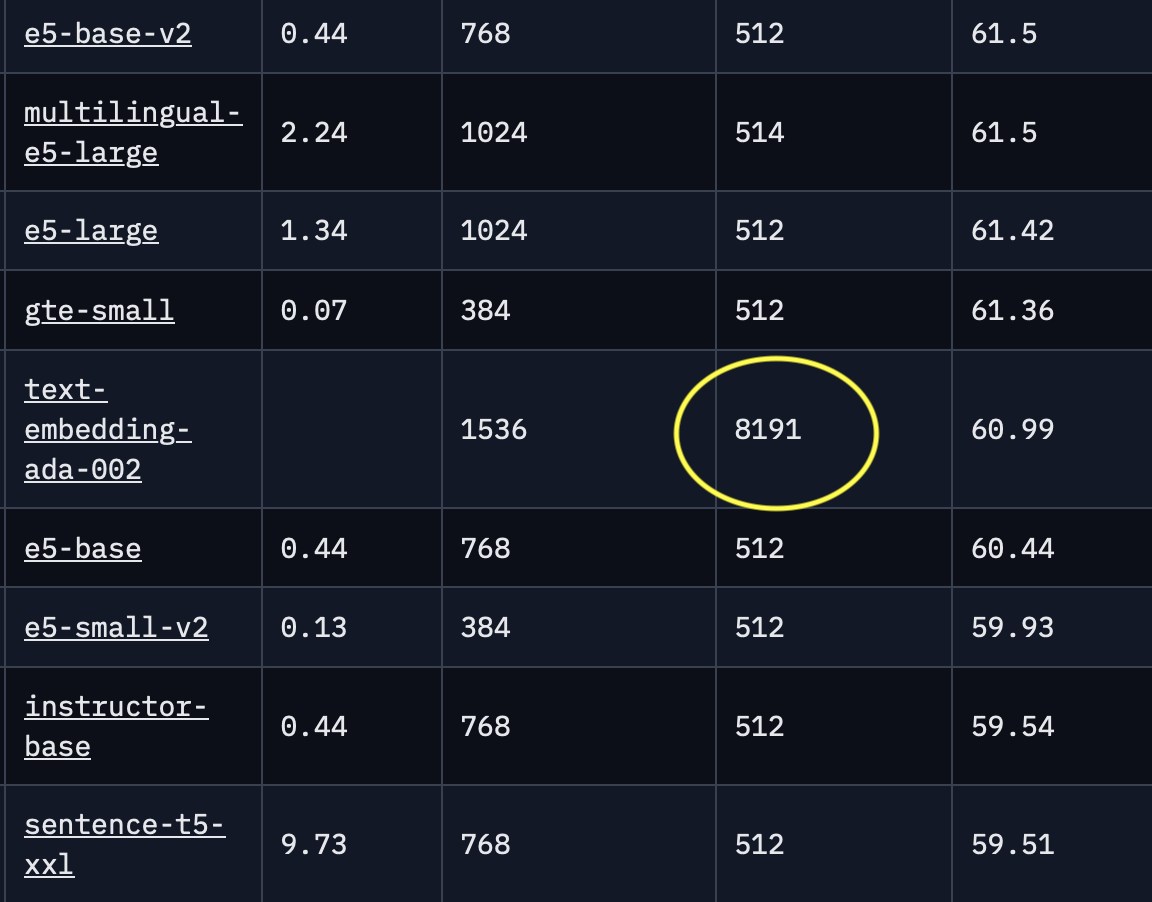
Embeddings, take your pick, I would just use ada-002
I used to think so to, until someone introduced me to MTEB Leaderboard - a Hugging Face Space by mteb and then everything changed dramatically overnight. In particular, smalller embedding models are very fast and surprisingly powerful.
I’ve messed around a lot here, and I think there’s stuff to do, but I 've realized that my first step is to master the standards (straight bm25/tfidf/semantic embeddings) before engaging at the edges. we’re all at different stages in different parts.
Deepen the search with what I call “HyDE projections” (HyDRA-HyDE ??? )
Let’s say you have 5 different common views of a subject, ask the LLM to generate answers from these 5 perspectives (HyDE), so re-frame the question from these additional perspectives. This re-framing, is all you really need, I think, over a fine-tune, because you are reshaping the data to align to the query by this steering. So a lot of your papers mention fine-tuning as the answer. But I think re-framing from a fixed set of perspectives that you define can be just as powerful. If your subject domain is super rare and unknown by the model, then maybe in that case you need a fine-tune.
Yeah, the possibilities here are near infinite and much will be written about this topic I’m sure by many very smart people, though tricky to conclude because of lack of explainability and ‘prompt engineering’. I am guessing gemini will do a lot here, but that’s just a hunch.
I don’t think the papers i quoted stress fine tuning, except maybe a couple. There’s a lot to be done around training / i guess fine tuning the retriever (eg, contrastive learning), but imho that’s more pre training / transfer learning than ‘fine tuning’ which is frequently used in the context of LLMs. Even then, training retrievers is tricky and I have yet to discern the mysteries.
So in this scenario, you take the original query, and generate the 5 other queries (5+1), and so you have 6 different pulls
6 embedding (dense) pulls
6 keyword (sparse) pulls
So you have 12 streams to reconcile, and you just use RRF to do this.
Yes, we are as one on this part. Diverse retrievers together are greater than the sum of the parts
Each stream can be weighted differently by increasing the K factor in the denominator of RRF.
I’m looking for papers talking about the different things to be done here in particular if you run across any.
Just spent the last 30 minutes getting lost while browsing the leaderboard, very interesting! they even have one for Danish bitex mining! (that includes weird dialects that GPT doesn’t understand)
Could you explain the MTEB leaderboard for the uninitiated?
The latest reference architecture I have floating in my head is basically use a blend of embeddings and keywords, with extensive use of HyDE to steer the query.
Dense:
Embeddings, take your pick, I would just use ada-002
Deepen the search with what I call “HyDE projections” (HyDRA-HyDE ??? )
Let’s say you have 5 different common views of a subject, ask the LLM to generate answers from these 5 perspectives (HyDE), so re-frame the question from these additional perspectives. This re-framing, is all you really need, I think, over a fine-tune, because you are reshaping the data to align to the query by this steering. So a lot of your papers mention fine-tuning as the answer. But I think re-framing from a fixed set of perspectives that you define can be just as powerful. If your subject domain is super rare and unknown by the model, then maybe in that case you need a fine-tune.
So in this scenario, you take the original query, and generate the 5 other queries (5+1), and so you have 6 different pulls
6 embedding (dense) pulls
6 keyword (sparse) pulls
So you have 12 streams to reconcile, and you just use RRF to do this.
Each stream can be weighted differently by increasing the K factor in the denominator of RRF.
I recommend using a chrome extension called “Sprint Reader” to read papers like this.
Its an RSVP tool.
And no its not my extension, but it is useful.
When you get good at using it, you can read entire books in 10 minutes.
So mentioned because I think its an interesting read.
#Edit: Be careful how high you set the WPM.
If it exceeds your monitors refresh sync, it will skip words.
So it might seem like 3,600 Wpm is stable, but- /shrug
Could you explain the MTEB leaderboard for the uninitiated?
I always defaulted to ada by openai, but then I discovered that there was this competition (the mteb leaderboard) to make more and better embeddings. Some of the top scoring ones on that LB are hyper powerful and will probably get even more so.
Embeddings themselves are very very powerful and are probably revolutionizing things faster than the mega GPTs. Anyone can use them, just encode some query text and sklearn.metrics.pairwise.cosine_similarity(matrix,encoded_query) where matrix is a stack of vectors representing encoded bits of text of your knowledge base. Highest cosine distance wins.
What’s particularly intriguing about embeddings is their uncanny ability to find semantic similarity. That is, to almost reason that two things are talking about the same thing.
Really wild stuff.
Facebook released faiss which facilitates a lot of this. commoditizing their compliments I suspect.
But you make a good point in that the dimensions these models produce is much smaller, and even at 1024 dimensions, you still see significant search speedup compared to ada’s 1536 dimensions.
The reason why I like the larger amount of tokens, is that I want to embed large chunks, say 2k-4k tokens each. This helps with keyword search too because the rarity index you end up creating on the chunk, winds up being stats on the words inside that chunk. So the bigger the chunk, the more significant the stats.
Plus, with smaller chunks, your RAG gets scatterbrained and non-coherent. So GO BIG OR GO HOME
The goal is push big coherent chunks through the model, and the model essentially acts as a filter to produce the output. So BIG → small in this filtering operation.
I agree the topic is vast, but HyDE is so damn easy and powerful as a keyword generator. So I’m looking at the low hanging fruit.
The higher hanging stuff, is completely get rid of vector databases, and all these search algorithms, and have your own personal, continuously adjusted, AI model that essentially generates your content on the fly from each query. That’s probably where a lot of folks will want to go.
My only concern with that approach is that the AI weights are compressing your information, so unless you run massive models, you will likely notice compression loss artifacts. But this is for larger data sets.
If you have a small business, or small collection of facts, the 100% AI based retriever might be the way to go. So it’s a Moores Law waiting game, I suppose, for the larger data set to be widely available. But lots of folks could probably get by with the small version right now … would be curious to see how these systems perform.
I’ve found smaller chunks mean greater precision, and allows me to blend my various retrievers with finer granularity. bm25/tfidf (which aren’t limited, token wise) I find compete with dpr can when the text gets longer. Semantic meaning gets flattened and there are more opportunities for alignment along lexical lines.
Perhaps if my query was particularly long, but I haven’t run into a situation yet where it needs to be longer than at most a couple of 100 tokens. I’m sure there are use cases, but it’s never been an issue that I’ve encountered or familiar with.
The higher hanging stuff, is completely get rid of vector databases, and all these search algorithms, and have your own personal, continuously adjusted, AI model that essentially generates your content on the fly from each query. That’s probably where a lot of folks will want to go.
Or they want to go in the other direction I think there is something to be said for human generated content, after all - that’s why all of this works, right?
Tools like GPT4 which can synthesize it are extremely useful, but it’s my feeling they need to start citing their sources. There is a moral obligation that people do it, I’m not sure that AI should get a free pass. I suspect when gemini is released it will move fairly hard in this direction.
Personally I find ada’s long token length better for overlapping chunks on large documents, legal texts, company reports etc, I’m able to include more of each chunk as overlap and catch more semantic relevance for that normally lost at the chunk boundaries.