Hi, community.
I’ve been experimenting with Ada002 for STS (semantic textual similarity). I used the MTEB dataset from 2016 to compare Ada 002 against three BERT models: MS Marco, MiniLM and MPNet. All three BERT models outperformed Ada002 on STS (using cosine similarity) between the dataset sentence pairs. Ada only outperforms BERT on cross-language similarity because these models are English-only.
I am surprised by these results because I would expect the vastly larger Ada to be outperform the much smaller BERT.
Does anyone have any experiments or research to show that Ada 002 is superior to BERT?
— From my paired t-tests —
I used MTEB 2016’s sentence pairs and ran them Ada 002 and the three BERT models to generate their cosine similarities. I then paired those similarities against the ‘ground truth’ MTEB’s similarity score.
According to the t-statistic, MPNet’s similarity score most closely matches MTEB’s human-determined score, but there is still a statistical difference between them.
Model: Ada02_Cos_Sim (not normalized, so cosine sim range from 0.7 - 1)
t-statistic: 49.52204858828296
p-value: 7.202349242150549e-291
The differences are statistically significant.
Model: Ada002_Normalized (range is 0.0 to 1.0)
t-statistic: 28.99078943085248
p-value: 4.145519385937961e-140
The differences are statistically significant.
Model: BERT_MSMarco (range effectively 0 - 1)
t-statistic: 22.560656918692175
p-value: 4.728459634918976e-94
The differences are statistically significant.
Model: BERT_MiniLM (range effectively 0 - 1)
t-statistic: 22.856838512450626
p-value: 4.320214756628714e-96
The differences are statistically significant.
Model: BERT_MPNet (range effectively 0 - 1)
t-statistic: 20.526835851905595
p-value: 2.3562601811713193e-80
The differences are statistically significant.
But, looking at the graphs of the outputs, the clear advantage of Ada seems to be that the groupings of the similarities seem to be much tighter (though not at all as tight as we would help).
BERT_MPNet model vs MTEB 2016 comparing BERT MPNet to MTEB’s ‘Ground Truth’ (0 to 5)

Ada 002 scores normalized to a range of 0 to 1 to match MTEB and BERT. Normalization formula is:
= (Ada002_Output - 0.7) x (1 - 0.7), where 0.7 is supposed to be Ada’s lowest sem sim value.
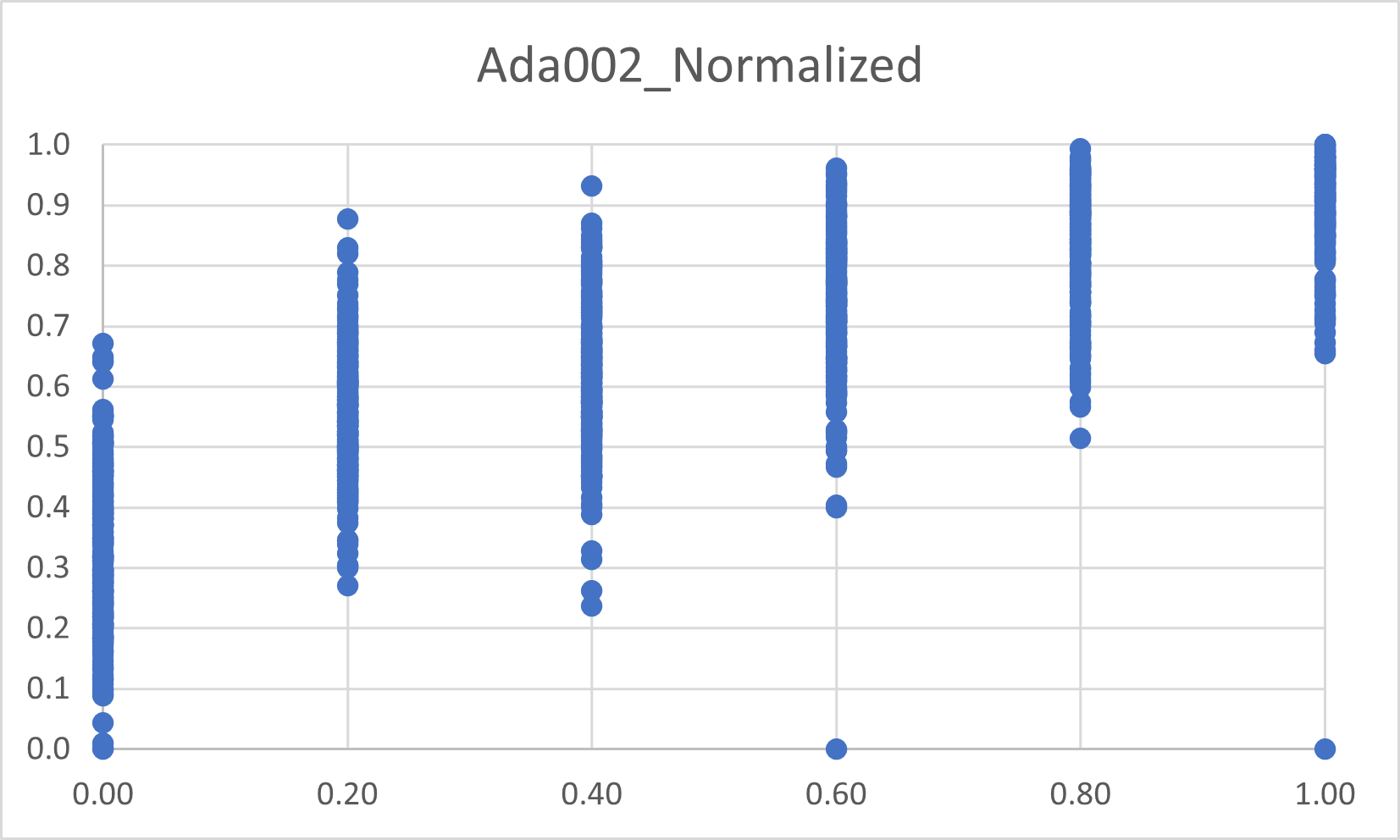
Not-normalized Ada002 values per MTEB score, where 5 = completely related and 0 = chaos!

Would it be fair to say that BERT is more accurate in the aggregate and Ada 002 statistically more accurate individually? (Sorry. I’m new to stats).
Finally, if you wanted to use one statistic or metric to show that one embedding model is better than another, what would you use?

