We’ve just shipped a couple new capabilities in the OpenAI API: two deep research models, webhooks, and web search with reasoning models—including updated pricing—all designed to help you build more capable, scalable AI workflows.
Deep research in the API: You can now use the same deep research models available in ChatGPT—o3-deep-research and o4-mini-deep-research—directly in the API. With these models in the API, you can now programmatically trigger deep research from your own internal tools or as part of your AI workflows. In addition to internal knowledge, these models can pull external context through web search and MCP server support. Deep research is priced at $10/1M input tokens and $40/1M output tokens for o3 and $2/1M input tokens and $8/1M output tokens for o4-mini.
Webhooks: Instead of polling, you can now listen for events to get notified when tasks finish—useful for async batch jobs and long-running tasks like deep research or o3-pro. We recommend using the new deep research models with background mode and webhooks, to improve reliability and avoid any timeouts or network errors.
Web search in o3, o3-pro, and o4-mini: We originally launched web search in the API supported by the GPT-4o and GPT-4.1 model series. Now, our o-series models can call web search while reasoning, pulling relevant context directly into their chain-of-thought and resulting in more helpful responses. We’re also simplifying the price of web search in the API—$25/1K tool calls in our GPT-4o and GPT-4.1 series and only $10/1K tool calls in our o-series reasoning models. If you’re looking for better web search performance, I’d recommend trying it on the o-series of models. However, if latency is top of mind, web search with GPT-4o and GPT-4.1 will be the fastest options.
Excellent update @nikunj and the OpenAI team! Deep research in the API is something we’ve been waiting for, and I’m excited that it’s here now!
Web search in o3, o3-pro and o4-mini is also a really neat addition. I was previously using the search_context_size parameter to control cost, quality and latency. Since the search context size configuration is not supported for the o3, o3-pro, o4-mini (and the deep research models), could you confirm what the default value on these models maps to between low, medium, and high? This would help in deciding which models to use for our specific use cases.
Trying out the o3 deep research and web search this afternoon on some conjectures Im exploring. Ive asked it to help me with 3 separate conjectures. Ive used about 1 million input and 1 million output tokens for each question for a total of roughly 6 million tokens.
going to explore the outputs and see the value compared to costs
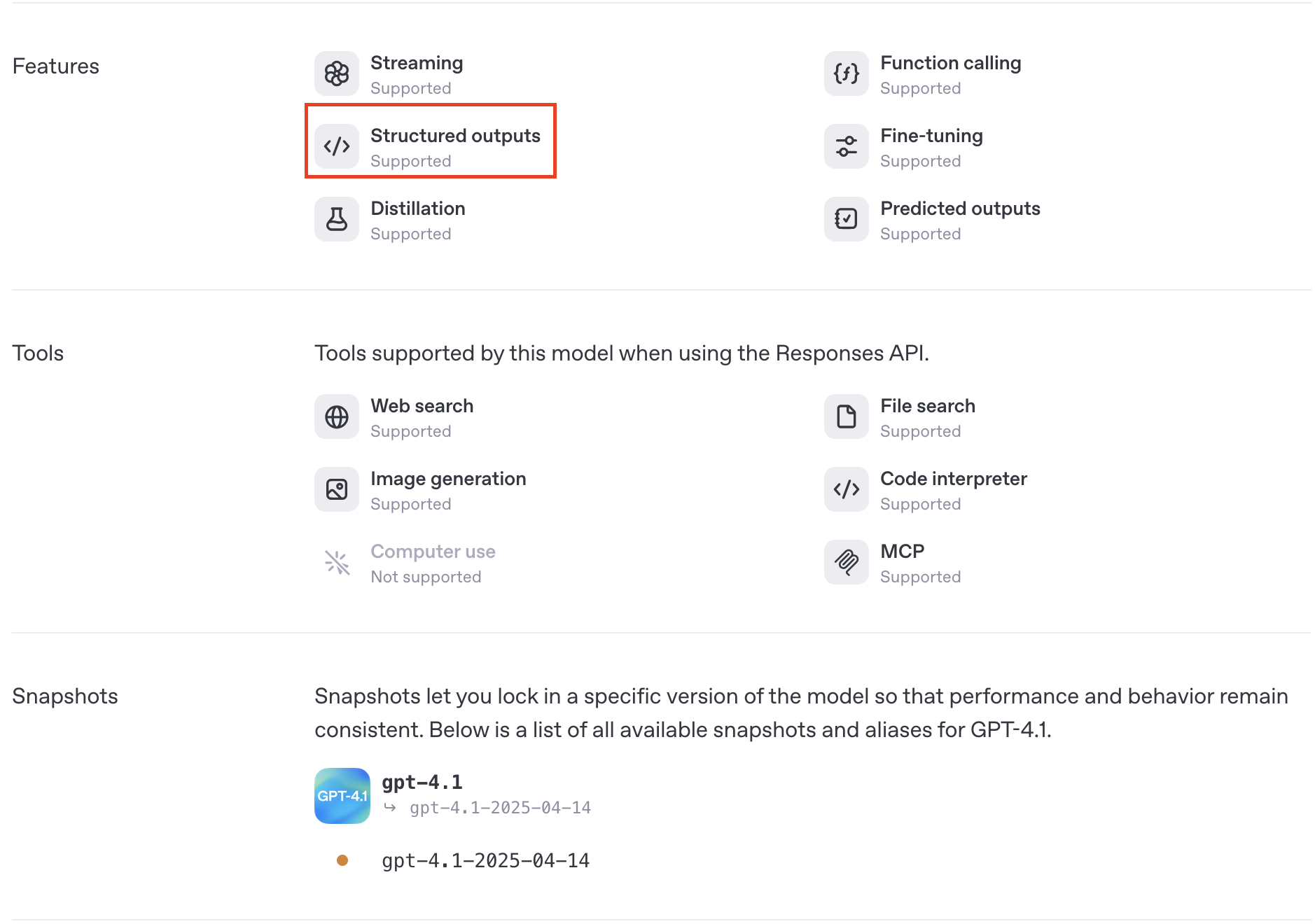
I’m inclined to say no, as the model pages for the o3-deep-research and o4-mini-deep-research models do not list structured output as one of the features that other models like o3 and GPT-4.1 support.
Today I started using the websearch function in o3; until yesterday, I was using gpt-4.1 for that task. The only thing I did was change the model. Indeed, the results are better quality than with gpt-4.1 and there are fewer problems with the output format, but my spending has completely skyrocketed. I’ve had to stop the search until I see what’s happening. Why is the consumption with o3 MUCH higher than with gpt-4.1? It doesn’t seem to match the published pricing scheme.
Whilst the input and output token prices for the GPT-4.1 and o3 models are the same (as of writing), there are at least two other factors affecting how much you pay for the web search query.
Second, web search pricing for o3, o3-pro, o4-mini, and deep research models is different when compared to GPT-4o and 4.1 models. In particular, the search results retrieved (search content) are billed at the model rate for the o3, o3-pro, o4-mini, and deep research models, but is free for the GPT-4o and 4.1 models. Furthermore, it costs $25/1k web search calls for the GPT-4o and 4.1 models, while it costs a lower amount of $10/1k web calls for the o3, o3-pro, o4-mini, and deep research models. Even though this web search calls pricing is lower, the fact that search content is billed at model rate can more than offset it, potentially resulting in much higher cost per query when used with the o3, o3-pro, o4-mini, and deep research models.