Trying the new o3-deep-research model through the Responses API.
1m tokens spent (see screen shot) - no output. If anyone at OpenAI wants to take a look: resp_685fdd88e168819ab808c4f49f7b112102dea5e6d8d627d0
There is no actual ‘response’
No tools other than websearch (which according to the log it was doing plenty)

5 Likes
And it seems to have overrided the max_output_tokens parameter too…
It actually did not technically output anything. Like literally,
![]()
Technically, shouldn’t reasoning tokens count?
I mean, at least you seem to have tried to prevent a large usage of tokens… and the API ignored that too.
Maybe that is part of the problem? Clearly I would expect a these modes to use way more tokens. But I set the limit automatically (Here at 16k but I guess I should try actually setting it to the o3 limit which would be 100k)
I can confirm that was indeed the problem!
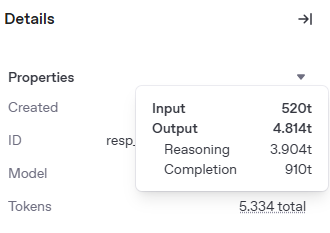
Not sure if it makes sense - but setting max output tokens to 100k (instead of the 16k) and re-running it DID create the report. It still has 1.2m tokens as its counter (usage?) - but the actual report out measures only about 7k tokens.
But the output window in logs talks about yet another number: 31k

1 Like

Thanks for sharing it. It explains a lot.
It seems it considers the huge amount as inputs, that’s probably why it reached that amount in the first request even with a max output of 16k.
In the docs it warns that if a low amount is set, reasoning models may end up with no results.
If the generated tokens reach the context window limit or the
max_output_tokensvalue you’ve set, you’ll receive a response with astatusofincompleteandincomplete_detailswithreasonset tomax_output_tokens. This might occur before any visible output tokens are produced, meaning you could incur costs for input and reasoning tokens without receiving a visible response.
To prevent this, ensure there’s sufficient space in the context window or adjust the
max_output_tokensvalue to a higher number. OpenAI recommends reserving at least 25,000 tokens for reasoning and outputs when you start experimenting with these models. As you become familiar with the number of reasoning tokens your prompts require, you can adjust this buffer accordingly.
In the docs quote it was meant for other models, so for deep research 25k is probably too low.
but setting max output tokens to 100k (instead of the 16k) and re-running it DID create the report
hi @jlvanhulst ![]()
How did you change max_output_tokens values?
- did you try your deep research attempt via
https://platform.openai.com/playground/prompts?models=o3-deep-research-2025-06-26? - were you able to change
max_output_tokensinplatform.openai.com/playground? or - did you change it on SDK or API call?
I was reading https://platform.openai.com/docs/guides/reasoning?api-mode=responses#allocating-space-for-reasoning but is not clear for me if, setting the value on that parameter is only possible via SDK or direct API call or if is able to set / change on platform.openai.com, or if is not possible.
Not sure if I need to click on Web Search to configure the tool and set Search context size to High maybe ![]() ?
?

I’d appreciate any help in advance ![]() .
.
Thanks.
1 Like
I do this from the API, using out of the box Python OpenAI library. So its really the ‘overall’ max_output_tokens that you see in the sidebar as well
I do not configure the web_search tool, so that uses the standard settings.
2 Likes
Thanks for your answer @jlvanhulst ! ![]()
Regarding the web_search tool, I found your clarification interesting. I was under the impression that o3-deep-research and o4-mini-deep-research had the web_search tool enabled by default, without needing to explicitly pass it as a parameter in the API call.
My reasoning was that when I accessed https://platform.openai.com/playground/prompts?models=o3-deep-research, the web search tool appeared to be added by default.
Furthermore, the model’s documentation page (e.g., https://platform.openai.com/docs/models/o3-deep-research) doesn’t have a dedicated tools section (yet?) explicitly stating its support (or lack thereof) for web_search, unlike pages for models like https://platform.openai.com/docs/models/gpt-4.1 or https://platform.openai.com/docs/models/o3-mini .
Perhaps I misunderstood, so thanks for helping me clarify this point! ![]()
I also have another question: In what timeframe (in sec.) were your API call was able to consume over 1.2 million tokens with o3-deep-research?
I attempted something similar and received the following error in my logs:
Rate limit reached for o3-deep-research in organization org-… on tokens per min (TPM): Limit 200000, Used 162866, Requested 55476. Please try again in 5.502s. Visit https://platform.openai.com/account/rate-limits to learn more.
What tier are you currently on? I’m considering upgrading to Tier 2 or Tier 3 if I plan to use o3-deep-research frequently.
A curious observation I made is that the alias version (o3-deep-research) seems to have a lower rate limit than its canonical counterpart (o3-deep-research-2025-06-26), at least according to what’s displayed in my https://platform.openai.com/settings/organization/limits .
| Model | Token limits | Request and other limits | Batch queue limits |
|---|---|---|---|
| o3-deep-research | 200,000 TPM | 500 RPM | 200,000 TPD |
| o3-deep-research-2025-06-26 | 250,000 TPM | 3,000 RPM | 250,000 TPD |
| o4-mini-deep-research | 200,000 TPM | 500 RPM | 200,000 TPD |
| o4-mini-deep-research-2025-06-26 | 250,000 TPM | 3,000 RPM | 250,000 TPD |
This also doesn’t seem to align with the rate limit information provided at the end of the model’s documentation page, such as https://platform.openai.com/docs/models/o3-deep-research .
| Tier | RPM | TPM | Batch queue limit |
|---|---|---|---|
| Tier 1 | 500 | 200,000 | 200,000 |
| Tier 2 | 5,000 | 450,000 | 300,000 |
| Tier 3 | 5,000 | 800,000 | 500,000 |
| Tier 4 | 10,000 | 2,000,000 | 2,000,000 |
| Tier 5 | 10,000 | 30,000,000 | 10,000,000 |
2 Likes
I am tier 5 so that explains that. It takes between 5 and 15 minutes it seems and with the same prompt I have seen between 900k and 1.5m tokens ![]()
1 Like
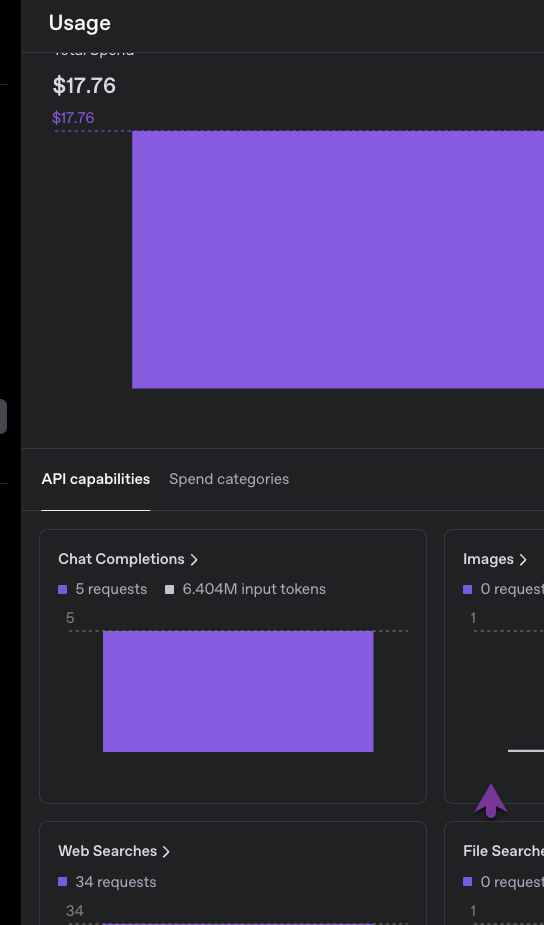
I will need to be able to limit the input token ingestion because clearly this becomes very expensive quickly. 5 requests cost $17 ![]() and 6 MILLION tokens
and 6 MILLION tokens
2 Likes
reminds me of the day I spent $67 on only about 5 test GPT 4.5 chatbot conversations that included images … ![]()
![]()
1 Like
It seems that in case of deep research, the way to control input would be by setting max_tool_calls.
You can also use the
max_tool_callsparameter when creating a deep research request to control the total number of tool calls (like to web search or an MCP server) that the model will make before returning a result. This is the primary tool available to you to constrain cost and latency when using these models.
But after seeing how much it consumes, I can’t help but appreciate how substantial the included deep research quota is in a ChatGPT plus plan.
3 Likes
Jeez, that is probably more than my all time spend… Gotta ask smarter questions ![]()
I have had a long term issue with this…
I mean how does Elon Musk account for his wealth?
It’s like these crazy guys with weird Philosophical ideas that don’t seem to account for it ![]()
Does this thread symbolise the world we live in?
No offense meant to anybody, I respect you all from your posts just love the context.
(I do have some Philosophical threads that warn on this (just as a technical fix))
3 Likes
It’s tiny compared to my overall spend.
1 Like
I love you guys so much, I work for cheap
Its mainly because all development and production apps using the API are metered, unlike ChatGPT
1 Like