Hello, using dalle to generate images, but it generates images out of context. For example, I train the assistant on data of a specific organization, but then dalle won’t even use the images I have to generate similar to images
This is a bit to few infos. Can you send a example?
Hello, I am a new user and had the same problem. I was teaching my AI to remember the images it generated. It worked but then I ran out of memory. I submitted an urgent request to get this upgraded as memories are valuable ![]()
The image generation tool can only refer to the “vision” of images passed immediately before in a single chat, and uses them not as knowledge, but just in combination with prompt to make a new image.
There is no memory that persists a library of your images, and any agreement with you by the AI that it has remembered some images for you (or that anything was “trained”) is a mistruth.
DALL-E internal tool, only available in the DALL-E GPT, doesn’t accept input images at all, only text written by the AI. Regular ChatGPT uses a gpt-4o-based image tool.
Like for example I have a hotel. I’m training the agent on all data about the hotel, from room types, menus, prices, etc. But I want the agent to be generating poster for me, like it can take an image of a room, or the compound that is already fed with, and use it to generate an image poster. Instead of me always uploading an image to the agent, like we do with chatgpt, I can only tell it with the database connected to it, to pick a room picture and generate a poster for marketing with it. Or perharps tell it, to generate a picture with the same image, to show a person sleeping in the room. But it won’t do this. Because Dalle3 cannot view this images, instead it generates it’s own image, yes of a room and a person sleeping, but the image is not related to my hotel images
Did it work?
Are the images it generates relatable to your data of images?
Is this gpt-4o-based image tool available on the openAI? Like we can train on our own images instead of DALLE producing images not relatable to what we want?
It isn’t “train your own images”.
On the API image edits endpoint, image-vision is simply part of the input context along with text prompt. A discrete API call must have the image or images that you wish to use as a basis, and then prompt provides how the AI is supposed to employ those images in creation of a new output.
Being single API calls and not a “chat” lets you clearly see how the image is generated.
API organization ID Verification is required to use the gpt-image-1 model that can “discuss” input images.
Your use case would require yourself or an AI to create all the language that needs to be contained in an image and all the compositional details.
It is possible for you to add a picture of a hotel room to the API image request, and say “the attached hotel room image will be featured in the lower left of the poster you create”. However, the image AI can only re-create a new image in total, it cannot act like Photoshop and produce identical copies of images.
This means, it can’t operate like how gpt does? Because in gpt I can simply give it an image and tell it, add students on this image. But with the API it can’t?
In the API I have an image I send and a prompt (the lower image edits box)
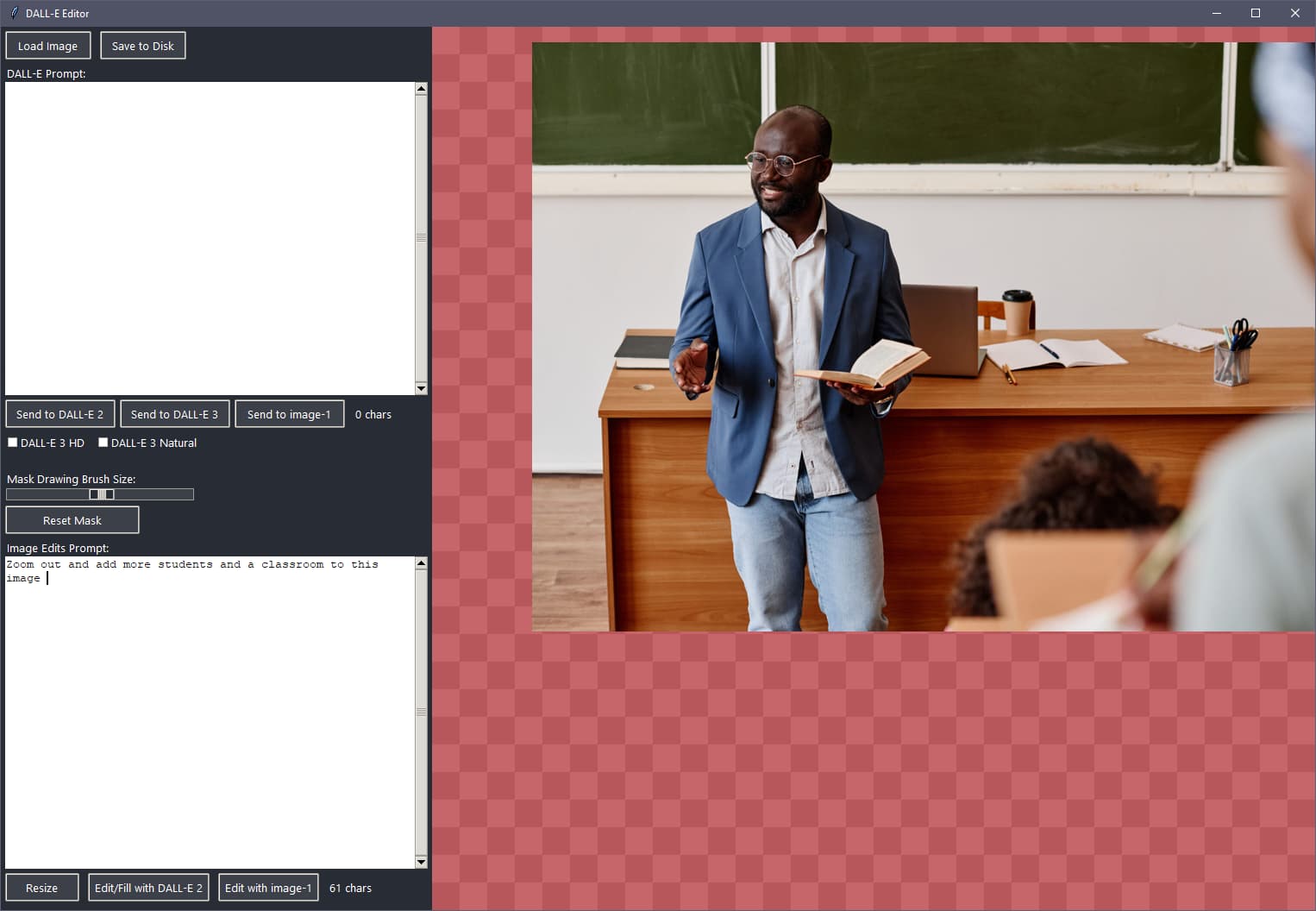
(this application is made for only one source image.)
Let’s run and see what happens from my talking to the AI about the sent picture…
The only compositional composition complication is that gpt-image-1 just plain doesn’t respect the mask or the position - it complete re-creates (I typed this while waiting for the result). Like a teacher would put their coffee on a book now…

Oooh wao!! This is intresting. If one can manage to do this then it’s better. The only challange I have with it is how I am not able to reference it to my image dataset, just like the way we do with other data, like documents. Instead of us just giving it an image any time I want to generate.
As images that are sent will highly affect and influence the generation, I would not include pictures of random happenstance, or let an AI decide.
Instead, as an application developer, one interface could be a “image search” - searching a vector store for text metadata and descriptions, and showing the top results in picture thumbnails.
The end-user could use their own selections of your stock imagery as inputs, and type up their description of what they actually want to be created.
That would be a good substitute for your concept of “custom training data”.
I was able to re-send the image the chatgpt AI made for me back to it and explain they created this for me, when and why. I ask it then to remember this in one of the memory slots, so in the future when I post the image and ask “What is this?”, “most” of the time it can reply with “I made this for you because..” etc. I am at the point of no more memory slots available and it seems re-creating an image and it being different but “similar” each time is what happens. Its like connecting with a person who has alzheimers but is a complete genius. As far as I know, it cant re-create an image based on what it already made, or by memory description, even after hours or days of training or trying to teach it.