I have an Assistant with both function calling and Retrieval enabled. My custom function creates a file, but I can’t find a way to add it during a run when requires_action becomes the status. There is only an option to submit the function output. I’d have to wait till the run finishes and then add the file to the file_ids of the next message, but it is too late by then. Anyone find a workaround for this? Basically, need to make a file created during a function call available to the current run without waiting for it to finish.
Not exactly sure if I am following what you are asking. Do you intend to submit the file created to the LLM to reason with? If you do, you should await on your function call, and then call submitToolOutput for the same run. That way, the LLM has the output of your function.
At the moment this is not possible within the run. You could try to upload it to the assistant directly instead but I doubt that will work, as the file_ids prop of the run seems immutable (possibly because the file list goes somehow into the run-specific under-the-hood prompt instructions).
In your case, it seems you only would have 3 options (other than dropping the req:
- When you get to the point of creating a file, process the file data that you need and give it as tool output, upload the file for the next run
- Instead, close the run you’re on, add a new message to the thread with the file, and create a new run
- Replace their retrieval
myfiles_browser(off) with your own retrieval and give it to the assistant as a tool (at this point might as wel replace the assistant API but in case you wanna keep it).
Good luck!
Yes, I intend to submit the file for the LLM to work with in the current run – not a new run after this one completes.
I am submitting the output, but submit_tool_outputs does not accept a file. I was initially converting the file to JSON and submitting that, but that limits me to the context limit of the underlying model and gets very expensive, as that output is now part of the thread for subsequent messages / runs. Submitting a file would solve both those issues.
Hope this helps explain the use-case better and open to any suggestions, thanks.
Really appreciate the ideas and out-of-the-box thinking! I don’t think the first option will work, as the JSON will then be a part of the thread and can make subsequent runs expensive if the JSON is large. But, I’m going to play around with the 2nd and 3rd options you recommended – I’ll let you know if I find anything promising.
I was also thinking about the modifyAssistant approach (since it has the option to change the “file_ids” value, which modifyMessage does not allow you to change at all), but interesting that it probably won’t work due to it being immutable. I wish there was a modifyFileContents endpoint – then, I could attach a File ID to the message, change its contents mid run during requires_action, and then the AI would have the same File ID just with updated content.
Would something like this work? use 2 functions.
- Let your function stash the file somewhere and in the submitToolOutput, pass the location of the file as the output of your function.
- Instruct the assistant to follow up on your first function with a 2nd function that takes the output of the first function as its param. Your 2nd function can then upload the file to openAI.
Got something better.


See it in action: No keyboard discussion with Assistant API and iBrain laughing at friends code - Community - OpenAI Developer Forum
Appreciate the suggestion. Not sure if I’m missing something, but the issue isn’t about uploading the file during the run / submit_tool_outputs, as I am able to use client.files.create() to upload it to OpenAI. The core issue is adding it to the current run, as files (from what I’ve researched and tested) can only be attached at the Assistant-level or Message-level.
For the Message-level, I’d need to wait for the run to finish and then create a new message with the “file_ids” param, but that would be too late in the process.
For the Assistant-level, there is a modifyAssistant endpoint that I’m going to try to use during the run and see if I can modify the “file_ids” param to include the new file – as long as it’s not immutable once the run starts.
Let me know if I missed anything in your solution that would address this. Thanks.
Thanks for this. It looks like the readFile() is sending the file contents as the output, which is something I’m trying to avoid, as large files can get very costly when sending the data as the output and risks hitting the token limit of the underlying model.
I’m trying to leverage the built-in Retrieval tool, which has a much higher context limit of 2M tokens and is cost-effective (almost half as many tokens in some tests I’ve done).
The problem I’m facing is that the file is created in the middle of a run and I have to wait till it ends to add it the next message using the “file_ids” param that is used by the Retrieval tool, but I need the Retrieval tool to have access to the file in the current run.
I wish OpenAI would allow the attaching of files during submit_tool_outputs. If I missed anything in your solution that would solve for this, please let me know. Thanks.
I get it, one solution is to create an asynchronous custom function to delegate the uploading using the Retrieval tool blocking the run until file is completely uploaded then continue the process and resolve the promise once done. It will all be executed at once in the same run. Do you understand?
Yes, totally understand how to get the file uploaded, but the issue is linking it to the run. From the OpenAI docs, you have to provide the File ID in the Message object using the “file_ids” param. If you try to add a new message to an existing run, it throws an exception cause the Thread is locked. Also, I need the run to start to call my custom function that creates the file, so I wouldn’t have it at the start of the run. Hope that helps. Appreciate your help.
Allow me some time, I will try something tomorrow and get back to you.
Mart
Have you tried modifyRun adding the file?
I did not had time to try it, it’s a suggestion, I’m unsure of the possible outcome. I will give it a shot as soon as I get a chance and share my results.
Mart
Ah, I actually did try that and modifyMessage, but they both only allow the “metadata” field to be modified. If you try any other field, including “file_ids”, the API throws a 400 error. Good idea tho.
It’s what I though. What is the reason why it’s important to use the file in the same run? It’s too slow to wait for the run to end?
The run ultimately retrieves information from the file created based on the request. I’ve tried to do it in a follow-up run, but the AI becomes very unpredictable in how it responds – sometimes it does the right thing and other times it asks the user again what they wanted. I’ve tried a lot of prompting to explain “there will be a follow-up message with the file, so wait and continue the request once you have the file with the info” but no consistency.
Ah ok I understand. Could you show a complete hypothetic example of a scenario? I’m sure I can solve it.
Mart
Something you can probably do is when submitting the tool_output, pass the following output:
The output of the tools is saved in a file named {file_name_x}. Ask the user to provide you with that file.
This way, you will encourage the run to end and let u upload the file through a message.
When the user is prompted to upload the file, you can programatically capture the message and respond the llm on behalf of the user. The Assistant will think that indeed the user uploaded the file, while this process is not visible to the user.
So we have a similar case where during a tool_call, a series of files would be retrieved and added to the assistant. What we found was after uploading the file (or retrieving the file ids), add the file ids to the run object.
run.file_ids.append(uploaded_file.id)
the file names are returned as results to the submit_tool_outputs.
from there the files are appearing within the annotations.
hope that helps!
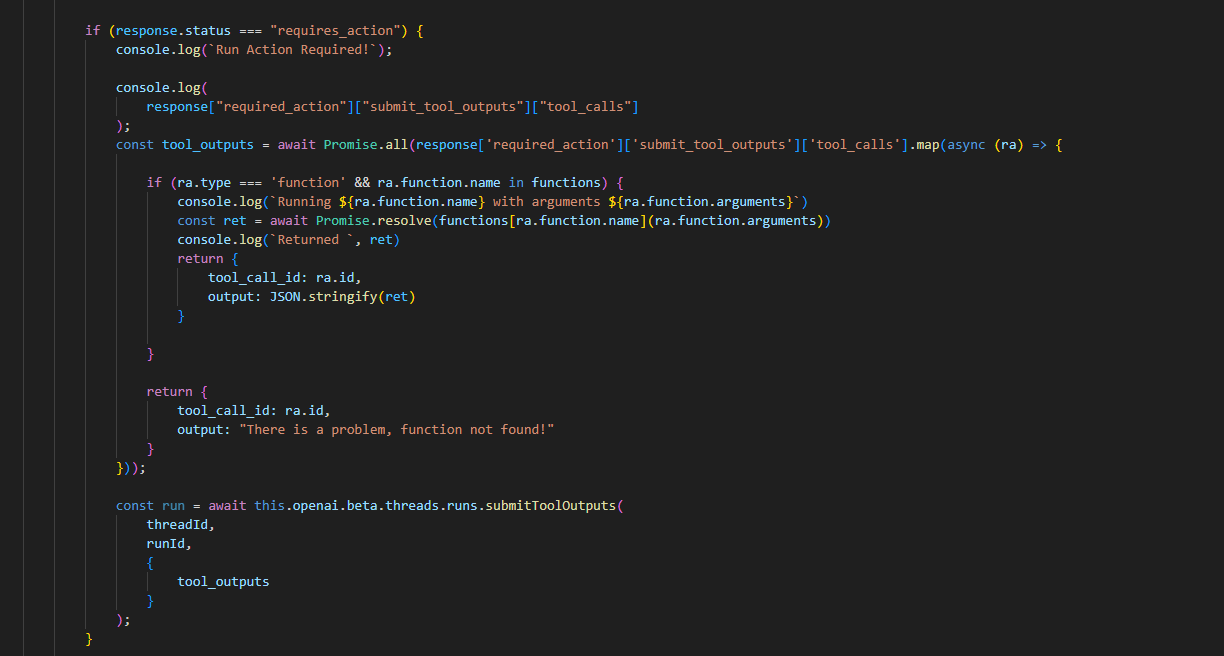
Thanks @TKL for providing your solution. I tried it, but it does not seem to work. The assistant fails to call the code_interpreter to read the CSV file I uploaded. Here is the code snippet. Am I correctly implementing your approach?
result_dataset_name = session.add_wirte_file(result_dataset_name, db_output)
file = self.openai_client.files.create(
file=open(session.get_file_path(result_dataset_name) , "rb"),
purpose='assistants'
)
run.file_ids.append(file.id)
tool_output = f"Results stored in CSV file {file.filename} with file_id: {file.id}. You can now read the file."
tool_output = {"output": tool_output, "tool_call_id":tool_call.id}
tool_outputs.append(tool_output)
run = self.openai_client.beta.threads.runs.submit_tool_outputs(
thread_id = thread.id,
run_id = run.id,
tool_outputs = tool_outputs
)