one of the key capabilities of my new AlphaWave client is it’s ability to not only validate a models response, but to also automatically get the model to repair it’s response. I thought I’d share an example of that in action.
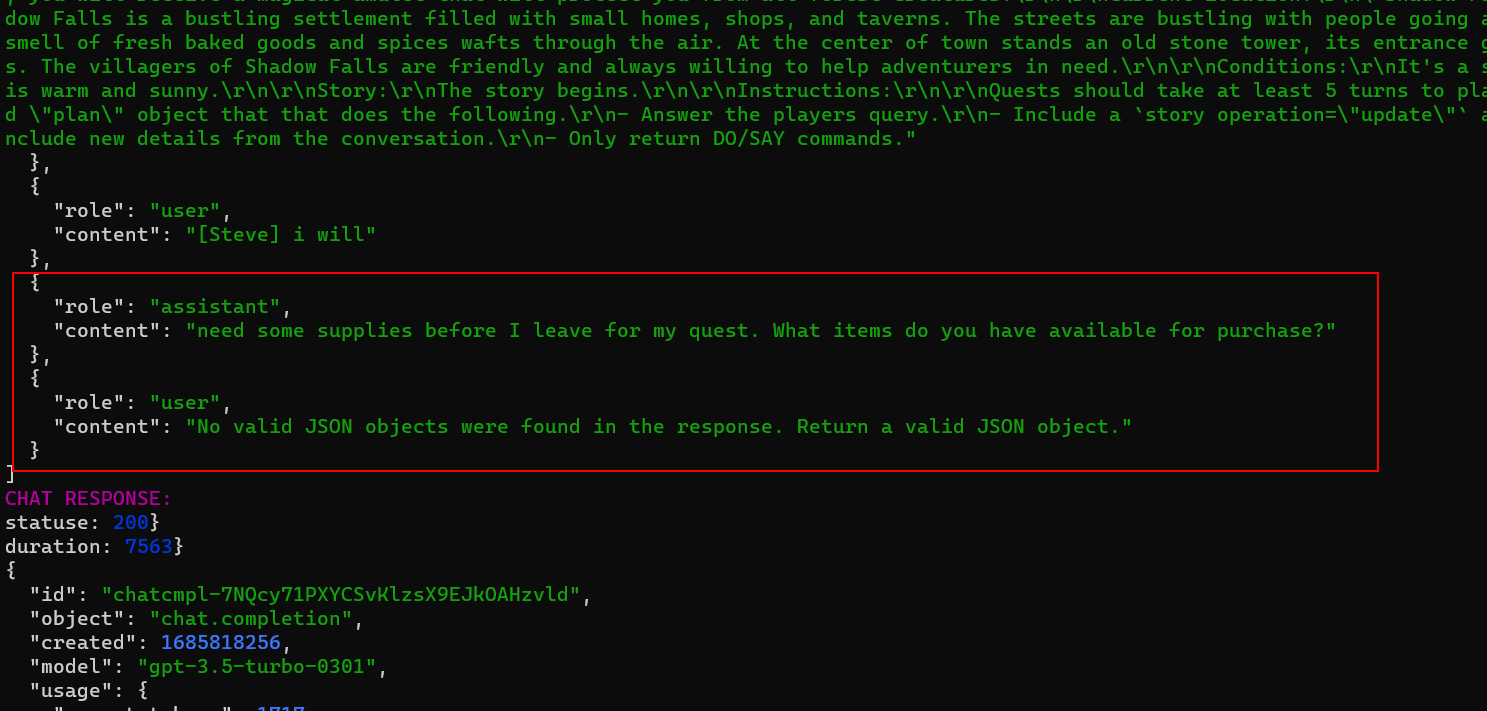
This is a QuestBot sample that I’m working to convert to use AlphaWave and QuestBot is currently using gpt-3.5-turbo. The main prompt for QuestBot is supposed to always return a JSON based plan but this is gpt-3.5-turbo and we all know how it is with following instructions. In the screen shot below you can see the model going off course and AlphaWaves feedback loop kicking in:
Instead of returning a plan, the model is attempting to complete my rather short reply but the validator catches this and puts AlphaWave into repair mode. To repair the response, AlphaWave installs a memory fork that isolates the bad response and lets it have a side conversation with the model. And even gpt-3.5-turbo immediately comes back with a valid response:
AlphaWave then un-forks the conversation and uses the new repaired response in place of the bad response. So on the next turn we can see that it’s as if the mistake never happened:
This all happens automatically and from a callers perspective the request can just sometimes take a little longer to resolve. The library comes with a built in JSONResponseValidator class that will just verify you’re getting a valid JSON object back, or you can give it a JSON Schema and it will validate the returned object against the schema, and feedback to the model any errors.
You can also easily create custom validators with added logic. My PlanValidator, for example, not only validates it’s getting a well formed plan back but it also guards against hallucinated actions/commands and parameters.
I’ve done some basic testing of all this against text-davinci-003, gpt-3.5-turbo, and gpt-4. They all seem more then willing to fix a bad response if you just ask them to.
@bruce.dambrosio and @bms-geodev have been helping to port both Promptrix and AlphaWave to Python so if anyone would like to collaborate on those efforts just DM me… I think Bruce has Promptrix basically working so AlphaWave should be next.
Yup, still testing Promptrix ConversationHistory (works on what I’ve tried so far), hope to get that finished today.
Basic strategy: chatGPT (4) knows typescript MUCH better than me, have it do all the hard work. One problem: it can do inconsistent camelCasing between files.
It also occasionally decided to create a dummy class file for an import. Wierd. That was pretty rare.
Snarky comments don’t bother me. If it works and people find it useful they’ll use it. This is the best technique I’ve found so far that fundamentally improves the models overall reliability. That seems useful…
Ok, finished testing promptrix for now, working (minimally, at least) with Guanco-33B and gpt-3.5. Moving on to Alphawave core (not Agent just yet), tired of having to put so many checkpoints and manual restart points in my code-gen pipeline.
I was telling Bruce that once the broader community gets their hands on the python version of AlphaWave, I’d really like to see the prompts+responses that AlphaWave wasn’t able to repair. I have a lot of techniques I can bring to bear, like INSTRUCT and such, but currently even my simple feedback statements are working well.
That probably isn’t a complete surprise as in my Self-INSTRUCT prototype, I’d only encounter a hallucination I couldn’t walk the model back from maybe once every 300 model calls. AlphaWaves isolation mechanism is better so it won’t surprise me if it takes 1000+ model calls to get AlphaWave to fail.
The one case I’ve seen AlphaWave fail to repair the response so far, was because I had the wrong validator wired up to a prompt. The validator kept asking for properties not provided in the sample JSON sketch and the model was completely confused as to how to fix it.
major missing item is installer. We’ll pbly upload to pypi eventually.
Meanwhile, the promptrix-py code on github seems to work, at least I’m using it in my pipeline. Just put the promptrix folder inside the folder containing the code that will call it. I’ll try to upload an example (example2.py is a place to start)
alphawave I’ll try to do an initial upload tomorrow or monday
Thanks for the info. After lurking for months, I created an account just so I can keep up with this py conversion. My python skills are mediocre at best but I can contribute to bug reporting?
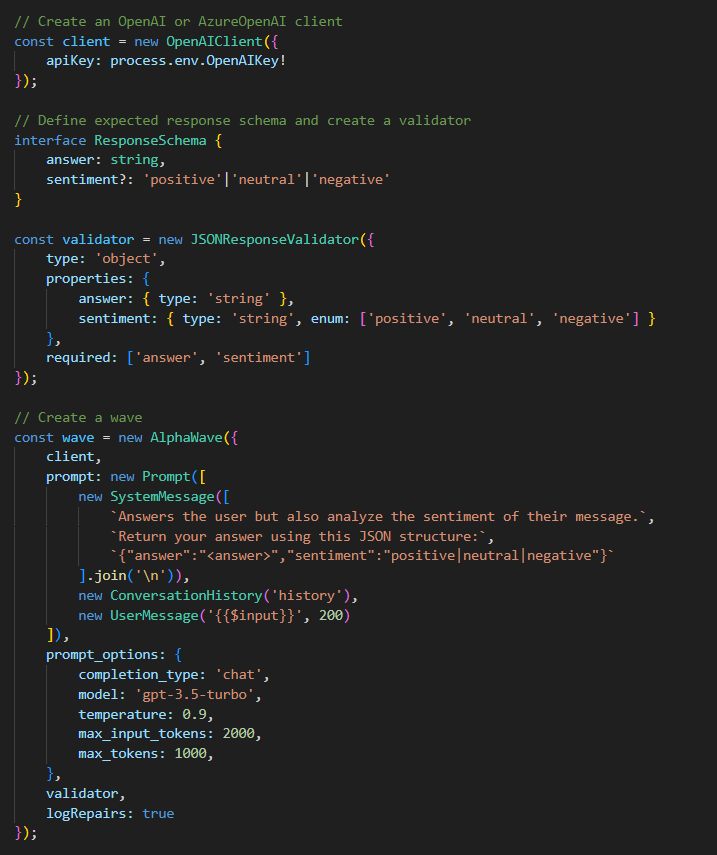
@bruce.dambrosio I just checked in a new Sentiment Analysis sample for the core library that has the model always return its answer via a JSON object that includes sentiment analysis for the users message. Looking at the sample run below you can see that GPT-3.5 pretty much immediately fails to return JSON which AlphaWave gets it to fix. It’s then fine from that point on and this is running a temp of 0.9:
You should be able to extend this example to perform other general purpose language tasks (translation, language detection, classification, etc.) and get rock solid output from even gpt-3.5-turbo.
Adding a note here in case someone wants to add a similar feedback mechanism to their project…
I finally ran into a case where AlphaWave wasn’t able to get gpt-3.5-turbo to fix bad JSON object but then I took it to playground and worked with it for an hour until I could get it to fix it. The issue was the passive nature of the feedback I was giving in certain cases. I was giving the model feedback that looked like this:
The JSON returned had the following errors:
"instance.thoughts.plan" is not of a type(s) string
Return a JSON object that fixes these errors.
The model was returning me an array of strings and even though I was telling it wasn’t of type string, it would basically say “yeah it changed to a string array” and then return me the same object back. Umm… No it didn’t. I finally got it to correct the issue by giving it this feedback:
The JSON returned had errors. Apply these fixes:
convert "instance.thoughts.plan" to a string
I just turned the passive error message into an instruction and it fixed the issue no problem. Then I had to go through the code for the JSON Schema Validator I’m using and generate more positive natured instructions for all the errors that made since. Some of them like, minimum, maximum, contains, etc. I just ignored because the model will do a horrible just correcting those mistakes anyway… So mental note, don’t give the model too complex of a schema to conform to.
Both promptrix and alphawave now in pypi. Little documentation yet, working on it.
Ask here, both @stevenic (original dev) and I ( @bruce.dambrosio) (python port) are pretty active here
That’s great to hear! Having your packages available on PyPI definitely makes them more accessible for other developers. Writing good documentation is an important step in making sure others can understand and effectively use your work.
The alphawave and promptrix python libraries alongside a locally trained model creates a fast performing and repeatable workflow. Your contributions are appreciated by many.