I’ve been trying to educate some of my colleagues on how vectors capture semantics. One question that always comes up are “what are some specific example of features?” E.g., to vectorize a word features would be noun, verb, etc. as well as many others. But where I get stuck are on specific examples not for just one word but for a paragraph or document. I’ve asked ChatGPT but it gives me very general answers and I want some real specifics. E.g., one feature represents the tone, one feature represents if the domain is healthcare. Just making those up. Is this documented anywhere? Or can someone just reply with say 5-10 specific examples? If this is proprietary to Open AI perhaps examples with an open source LLM such as BERT?
I think the diagrams here do a great job of explaining the underlying principals around embeddings.
1 Like
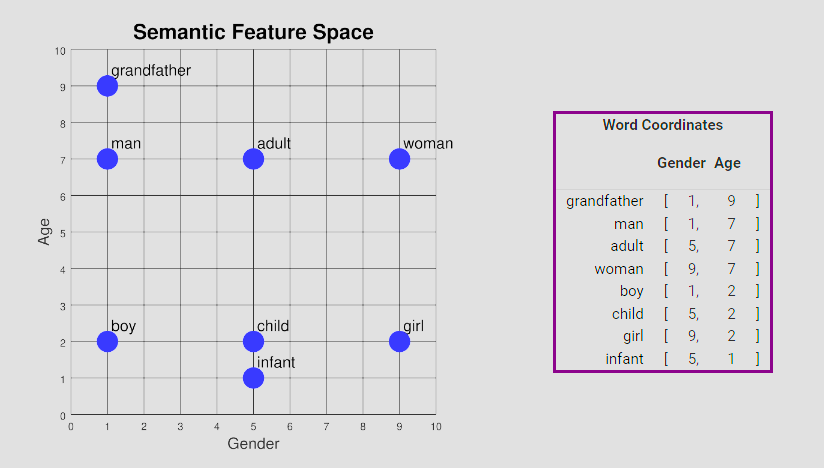
Thanks, that is very helpful. I’ve seen similar examples but I like this one a lot because it has more example points in the space than other examples I’ve seen. But this is just a 2D space whereas with real vectors we are talking about thousands of dimensions. Of course those can’t be visualized but I would like to just know some specific features in the much larger thousand of dimensions space. I know several categories such as: Semantic Similarity, Named Entities, Sentiment Polarity,… but developers like to get into the weeds and it would really help if I had the equivalent of some example features (like gender and age in this example) but showing some of the various options in an LLM like ChatGPT and how it represents specific representative features in those categories for an entire document rather than a word. So for example Named Entities is a category (btw, those examples came from MS Pilot, was just trying it out) but how would that be represented in a vector? I know what NER is but in a paragraph or document you are always going to have Named Entities. How is that specifically modeled in a vector. Are there features like Person so that if the document mentions a lot of people that number is high? If it mentions a lot of Organizations the organization feature is high? I hope my question is clear. I’ve worked in semantic AI for a long time and am just starting to get up to speed on LLMs and this is a question I’ve had for a while and now that I understand a bit about LLMs whenever I try to explain the idea to colleagues who are also new to it this question always comes up and all I can give are generalizations or examples like gender and age or queen - woman + man = king.
The individual dimensions don’t necessarily represent anything specific. We’re talking about a latent space representation of a chunk of text in some (polar, I think) space - this euclidean arithmetic is unlikely to work.
There is no named entity recognition per se. The dimensions don’t map to specific curated features. You can try to extract features from embeddings with matrix optimization (i can’t find the exact cookbook at the moment, but it’s a similar approach to this Customizing embeddings | OpenAI Cookbook, or use this to ask “how many people?” “how male?” “how royal?” Regression using the embeddings | OpenAI Cookbook)
You generally take some sort of pre-existing large language model that you either take some intermediate layer from, or that is just finetuned to generate embeddings a the last layer. What the dimensions are is irrelevant, the loss function just looks at cosine similarities. (example: e5 mistal https://arxiv.org/pdf/2401.00368.pdf)
So, what does that mean?
This is like a raw snapshot of your brain, firing, in a specific moment while you look at a specific subject. The idea is that if you look at something similar, you’re gonna have a similar activation, and we can compare the two. But what do the individual neurons mean? No one knows, but possibly nothing specific on their own.
2 Likes
Thanks very much. As usual it is more complex than I thought and this explains why I haven’t been able to get an answer to my question. If I’m understanding you, it seems I was asking the wrong question.
1 Like
Maybe! But never stop asking! ![]()