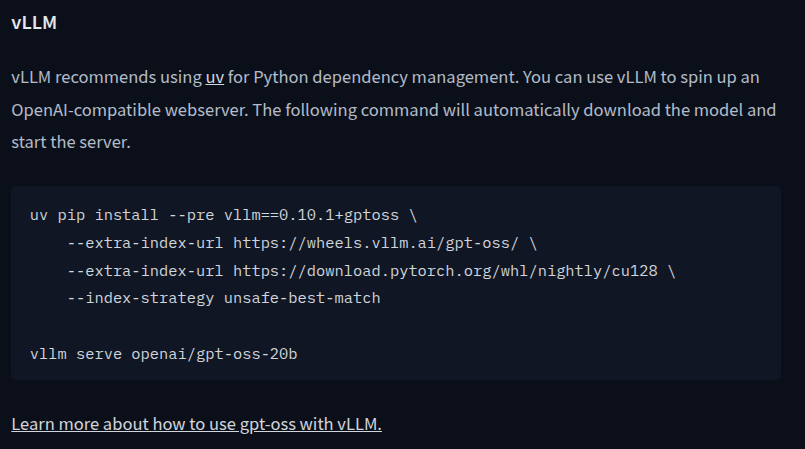
The thing is that it needs FlashAttention3 - you can try without but that would require some deeper modifications and more VRAM.
Well, I didn’t know that. I just tried and then went into a debugging loophole where ChatGPT insisted on the ability of RTX4090 being capable of using that.
To defend myself and ChatGPT a little here, it has to be said that Flash Attention 3 just came out and is currently in beta.
vllm with these oss models is…an interesting beat to say the least.
Posting this here mainly for documentation, but I’m currently in the middle of trying to get these oss models to work on strix halo hardware with vllm.
Spoiler alert: it’s not fun.
Unless you have / use nvidia GPUs, it’s a nightmare to setup because of the god awful mess that is rocm. Although as of today rocm 6.4.4 might actually support a lot of the consumer hardware now??
Anyways expect docs/tutorials for setting up vllm with gpt-oss models with Strix Halo (gfx1151) hardware here soon. Assuming I can get a janky hack working to fix things soon lol.
For the record, the reason this is/will become very important is because this is directly about those AMD Ryzen AI Max+ APUs with that 32-128GB unified RAM. These critters are perfect for AI inferencing if it wasn’t bogged down by bad software / drivers. Plus I think folks should be aware that if you want/buy one of those chips expecting to install linux and run vllm without friction, you’re gonna have a bad time.