That’s just the coolest sentence I’ve read all day. What happens if there’s a contradictory statement, or the idea itself is contradicts the whole? Like in the case of a lie in a document or a conversation? A piece of deliberatey contradictory information.
I think your observation of “reliable data patterns” in data is farsighted.
I also think it’s difficult to discover the any atomic idea of a document, but that, the more the document is thought out, and the more structured it’s layout, the easier it is to identify the atomic idea.
In Contracts, there’s usually a clear hierarchy. Long-winded but perfectly understandable sections. Websites structure with html. Financial Statements follow a pre-defined form. Not to say that there aren’t anomalies, just that, by and large, at a glance, these documents have a clear structure that is, and has been, standardized for decades and/or millennia.
Then maybe you have something like an Epic Poem, Shakespeare, or a television show. They have reliable structures, but to understand them you have to read more carefully. There might be obvious semantic clues, like incremental repetition. “When young dawn with her rose red fingers rose once more” is a frequently repeated phrase in the Odyssey, for example, that can usually be found at the beginning of a chapter.
Then you have conversation, like this:
Blockquote
"… but her words, every body’s words, were soon lost under the incessant flow of Miss Bates, who came in talking, and had not finished her speech under many minutes after her being admitted into the circle at the fire. As the door opened she was heard,—
“So very obliging of you!—No rain at all. Nothing to signify. I do not care for myself. Quite thick shoes. And Jane declares—Well! (as soon as she was within the door), well! This is brilliant indeed! This is admirable! Excellently contrived, upon my word. Nothing wanting. Could not have imagined it. So well lighted up! Jane, Jane, look! Did you ever see any thing? Oh! Mr. Weston, you must really have Aladdin’s lamp. Good Mrs. Stokes would not know her own room again. I saw her as I came in; she was standing in the entrance. ‘Oh! Mrs. Stokes,’ said I—but, I had not the time for more.” She was now met by Mrs. Weston. “Very well, I thank you, ma’am. I hope you are quite well. Very happy to hear it. So afraid you might have a headache! seeing you pass by so often, and knowing how much trouble you must have. Delighted to hear it indeed—Ah! dear Mrs. Elton, so obliged to you for the carriage; excellent time; Jane and I quite ready. Did not keep the horses a moment. Most comfortable carriage. Oh! and I am sure our thanks are due to you, Mrs. Weston, on that score. Mrs. Elton had most kindly sent Jane a note, or we should have been. But two such offers in one day! Never were such neighbours. I said to my mother, ‘Upon my word, ma’am.’ Thank you, my mother is remarkably well. Gone to Mr. Woodhouse’s. I made her take her shawl,— Mrs. Dixon’s wedding present you know; Mr. Dixon’s choice. There were three others, Jane says, which they hesitated about some time. Colonel Campell rather preferred an olive.—My dear Jane, are you sure you did not wet your feet? My dear Jane, are you sure you did not wet your feet? It was but a drop or two, but I am so afraid: but Mr. Frank Churchill was so extremely—and there was a mat to step upon. I shall never forget his extreme politeness. Oh! Mr. Frank Churchill, I must tell you my mother’s spectacles have never been in fault since; the rivet never came out again. My mother often talks of your good-nature: does not she Jane?..” — “Emma,” Volume 3, Chapter II, Jane Austen
This goes on like this for another page.
Where is the central idea in that? It just depends how you look at the passage. On one level, the atomic idea here is “Miss Bates gets sat at the fireplace during the Weston’s ball.”  But on another level, it’s a brilliant recording of human conversation, very true-to-how-people-actually-talk, which is hard to do as a writer. (Try reading it aloud. It’s brilliant. I think this is one of the best written passages in all of Western Literature.) On yet another level, there are some interesting clues to the overall plot which are so casually dropped in the middle of all that delightful nonsense that its easy to miss…unless you pay attention to what she actually says… and know the whole story. This latter gets at the Purpose of the writer, “What did Jane Austen intend by including this section.” The central idea changes with each perspective.
But on another level, it’s a brilliant recording of human conversation, very true-to-how-people-actually-talk, which is hard to do as a writer. (Try reading it aloud. It’s brilliant. I think this is one of the best written passages in all of Western Literature.) On yet another level, there are some interesting clues to the overall plot which are so casually dropped in the middle of all that delightful nonsense that its easy to miss…unless you pay attention to what she actually says… and know the whole story. This latter gets at the Purpose of the writer, “What did Jane Austen intend by including this section.” The central idea changes with each perspective.
So I think it’s an excellent idea to keep underlying data patterns separate from layout, but could you use document layout to give an intelligence layer a clue on how to analyze the document? Could there be a step that adds the “layout” as meta data.
For example, the layer reads a document—you can usually determine from the first few pages what type of document it has, and whether it has some predefined structure. Say you’re working with a single law firm, and they have a type of standardized form they always use. In this case, in recognizing the pre-defined structure, the model can identify the layout and spend less time looking for Purpose.
But what if it comes across conversation, like the above? Perhaps a long, wandering and rambling deposition where—accidentally on-purpose the person let’s slip some juicy tidbit that seems irrelevant at first glance. Perhaps in this case, the model identifies that this is indeed “long-rambling conversation” and pays more attention to underlying meanings where Purpose might be harder to identify, or even intentionally obfuscated by the speaker.
As you say, Order is the first thing you look at. What if there is something that is input later that would only make a conversation that was input earlier make sense with the later input in mind? So, since the conversation was added to your database before the next piece of information, would the model think to check something that seemed completely non-sensical the first time it looked it over?
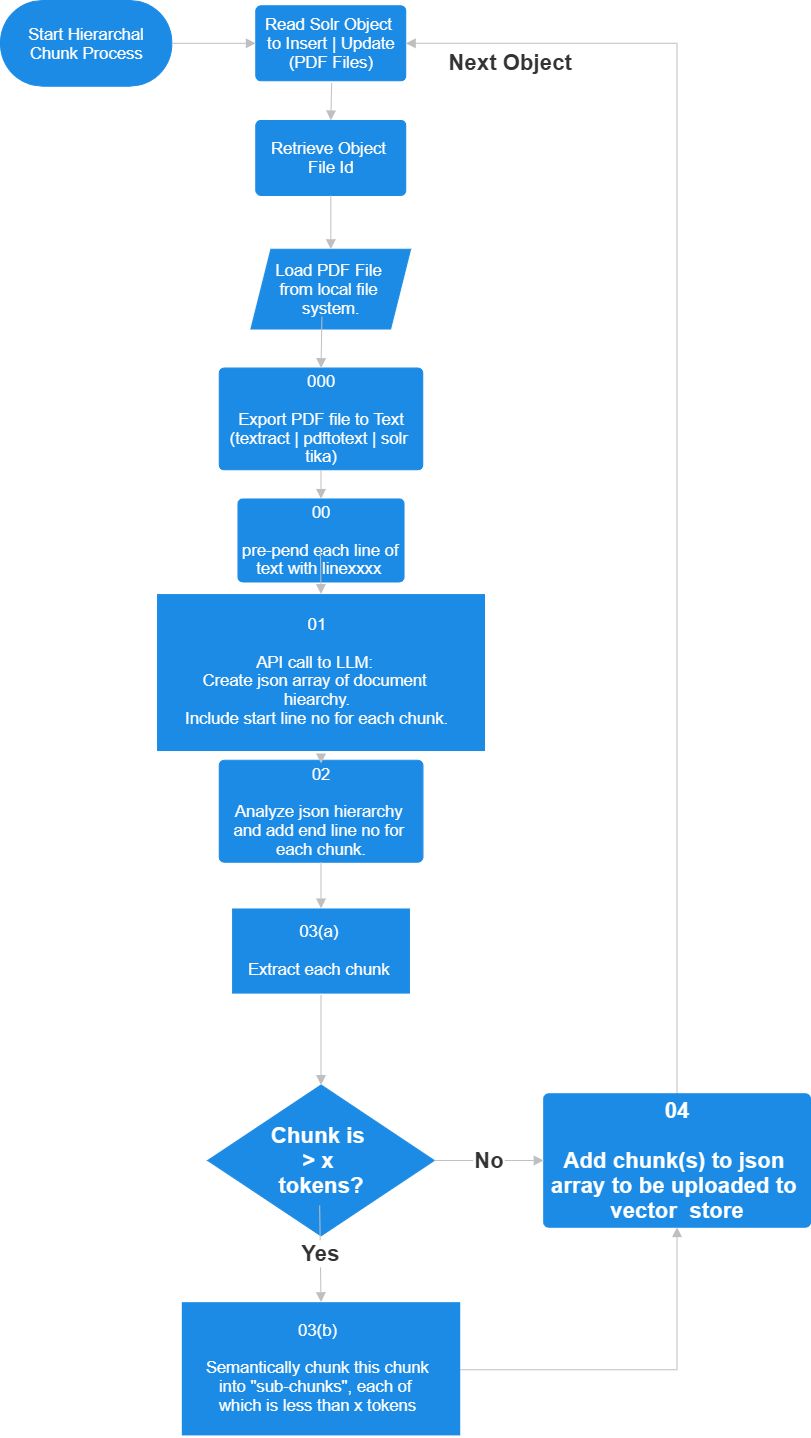

{kind=link}