I’ve seen it before but have not gotten around to trying it yet. With some adjustments, I could see this approach (i.e. what the author refers to as the “walk method”) work in principle for further sub-chunking and semantic clustering.
gpt-3.5-turbo-0125 on text stripped of linefeeds (495 tokens), “At least 3 split points are required.”:
The discussion thread on the OpenAI community forum is about developing a method for semantic document chunking using the GPT-4 API. This process constitutes breaking down large documents into manageable segments for better analysis and comprehension. Users @SomebodySysop, @jr.2509, and @sergeliatko are significantly contributing to the conversation. In the initial proposal, @SomebodySysop puts forth a concept to utilize the GPT-4 API for semantic document chunking. The basic idea involves sending a document to the API with instructions to generate a hierarchical outline and then use that to ‘chunk’ the document into a JSON array. However, this approach faces technical complexities, such as dealing with the 4k token context output limit and managing multiple API calls. [CHUNK] @jr.2509 suggested a nascent idea to return the boundaries of semantic chunks instead of whole chunks. This suggestion is echoed by @SomebodySysop and taken further. The proposal involved returning the first and last words of the segments of the text, providing detailed information about each segment, their hierarchy, relationships, and content previews. This solution, though functional, still required refined organization to fully utilize. [CHUNK] @sergeliatko shared their experiences and approach, describing how they developed a complex pipeline at LAWXER, including an API client, task processing server, models for comprehension tasks, and more, resulting in around 50k lines of code. The system could handle document analysis, including semantic chunking, generating hierarchical relations, and intermittent results processing all while overcoming the limitations of token window limit and parallel processing. [CHUNK] @jr.2509 then reported on their testing, sharing a sequence of steps based on @SomebodySysop’s approach. They refined the process and used it to create a detailed JSON schema breakdown of document segments and logical units. Utilizing OpenAI’s GPT-4-turbo model, the combined solution provided accurate and efficient semantic chunking of documents, with each logical unit acquired via extraction based on the unique line number data obtained. Continuing on their developments, @jr.2509 updated their process to add a category identification to the document content, a method for extracting footnotes, and a step to create embeddings for each logical unit. Despite the progress, the application still poses challenges when dealing with long documents and footnotes, which both users planned to address in their future work. [CHUNK] Overall, the discussion highlights an evolving methodology for semantic chunking of documents using the GPT-4 API.
…and because the input is 1/20th the cost of gpt-4-turbo, a bit of multi-shot doesn’t hurt.
$2 per 1M tokens processed. vs $0.13 / 1M tokens embeddings.
The semantic distance “This suggestion is echoed by @SomebodySysop and taken further.” to “The proposal involved returning the first and last words of the segments of the text, providing detailed information about each segment, their hierarchy, relationships, and content previews.” may have nothing to do with where a coherent thought is finished, despite that you can use 10 overlapping embeddings on the corpus to still come up with a technique at lower price.
For that last mile, catch-all semantic chunking, not a bad idea at all.
Agree that gpt 3.5 with few shot could work for sub-chunking.
On the embeddings-based approach, I am still a bit conservative - but again, it will only be possible to arrive at a meaningful conclusion through some testing.
I had a few more thoughts on this but have taken them temporarily off the post again - need to find a better way to articulate them after running some tests over the next week.
This is a fascinating conversation.
Now that 4o is out, how does that change how y’all are working with this conceptually? Or is the more efficient embedding and use of existing tokens just a bonus?
And while I have no idea, Imma creative not a programmer, I’ve been thinking a lot on long-term memory systems for AI—and I’ve been thinking in terms of systems that can pull left-brained, well structured data and combine it with more right-brained forms of information.
So, say you’re dealing with a long semantic chunk—you’d know what constitutes “long” better than I would—long enough to justify this method—could there be some way to convert the information into an image and store it like a visual, right-brained, memory versus a left-brained verbal one?
Well, menu things are possible, what I’m having hard times to define: what would be the “right-brained” representation of the long text?
When text describes some thing that would an image, I see that.
If the thing is a process, that would be a video?
What if the thing is an interaction between beings? Should it be emotion in this case?
Once you have a more detailed description of what is the “right-brained” representation of text, then we could start looking on ways to achieve that.
As of today, “vector” or “embedding” is more or less closer representation of a “concept” which might be considered something of the “right-brained” side.
For me, the bonus lies in the faster speed, greater comprehension and larger context.
When I say, “store as an image” and as I try to visualize this myself.
Imagine you have a gigantic document. Thousands of pages. More. And every day the document gets longer.
For the first thousand pages or so, this semantic chunking you folks are working on seems like the right idea. But say you start needing to store documents long term for “ready” retrieval (versus instantaneous retrieval).
So, every x number of tokens, where this number is expected to grow exponentially, you need to store those tokens in a way that can be retrieved quickly—but it’s old enough information to be compressed and archived in this way, without being forgotten.
Instead of storing embeddings within embeddings within embeddings, could you have the AI create a picture for itself?
I don’t think the “picture” is something a human being that wasn’t a math wiz could visualize, strictly speaking. Something in n dimensions where it “semantically chunks” that are like blobs of color—I visualize Monet—where each blob of color represents some type of semantic concept, which is related to an embedding, which can call forth the actual information stored in the structured data.
So, instead of looking for keywords for a million token picture, it can just identify some visual aspect and hone in on it in this more unstructured way.
**
And when I think about video—I think video is readily stored in some structured, left-brained way.
But you might store “impressions from the video” in this image way. Say we’re talking about basket weaving, and that nudges something in the way that the AI stores this multi-dimensional image, that it explores. It discovers (“recalls”) some ancient video of basket weaving that’s relevant from the 1970s because of impressions it related in a similar way to the current conversation.
Instead of having to keep a bunch of distantly summarized text, (which it still has access to) it has a more “immediate” way of visualizing complex information.
That’s neat!
And I’ve been meaning to ask:
Instead of pulling information from the first few words of a chunk, could you pull weighted keywords from the chunk and append them to meta data for the chunk instead?
The first few words of a thought don’t usually contain that much information, and perhaps grabbing keywords might help to create tighter links between data.
When we have mentioned using “the first few words” of a chunk in this discussion, it has been in reference to identifying the location of the chunk within the document and NOT in describing the semantic meaning of the chunk. The purpose of this thread is the discussion of how to get the model to identify the semantic meaning of the chunk.
I’m not sure why anyone would want to do that. For human beings, it might make some sense, but large language models aren’t human. They are machines. Specifically, they are computers. And computers store information, and compute, using 1s and 0s (if I remember my basic computer books from the 1980s). So, whatever “pictures” or “visualizations” you imagine will always have to be broken down to their essence of 1s and 0s for a computer to recognize them. And, since we’re talking about computers, they can’t actually “see” them anyway. They’ll have to be broken down into their numerical representations. Why add that extra step?
The whole science of vector storage and embeddings is based upon the principal that the semantic meaning of words in a language can be broken down into numbers – or vectors – for semantic retrieval.
What we have been seeking to do in this discussion is find a way to make these embeddings as concise and efficient as possible so that queries (cosine similarity or other searches) against them return the absolute best responses possible.
Your ideas are interesting, but I don’t see how they work in the real world today.
Personally I store indexed vectors, with appropriate data columns (also indexed where needed) in multi clustered cloud vector database. So for me the instantaneous retrieval is something normal.
I wanted to share some real-life implications of the choice between the “sliding window” and “atomic idea” chunking during the raw text processing. Let me know what you think.
Background: @ LAWXER (where I am), we developed the “atomic idea” (see my previous posts) approach, where the raw text goes through a complex workflow to identify pieces containing one idea at a time only, and then a hierarchical tree is built with parent-child relationships established between pieces. Then, depending on the application (in our case, it is legal document analysis), the tree is transformed into “embeddable objects” that are vectorized and stored in a database (we use weaviate for the performance).
This approach is much “heavier” in development and API costs compared to the “sliding window” chunking approach, where the text is cut into overlapping pieces of a specific length (often variable) before being embedded into a vector database.
Both approaches aim to create pieces of context retrievable by vector similarity search to select a context for LLM to use during the result generation (RAG).
So, one of our competitors, https://www.termscout.com/, offers a similar solution to contract analysis that we are about to put on the market. I went to see their demos and analyze the RAG engine performance (based on the videos they shared, I know they use a “sliding window” approach).
I know a lot of things will depend on the “embeddable object” structure you use for RAG, but still, some trends can be spotted right upfront:
-
Sliding window does not guarantee the “top” match is actually the sufficient context to produce the desired result, because it cannot guarantee the totality of the “idea” is present in the selected window, nor does it guarantee the selected chunk does not contain “the noise” (text, located close to the searched piece, but not being part of the searched piece).
How do I know that? TermScout solution, often referred to chunks as “base for the answer,” where only partial context was present at either the beginning of the chunk or its end. But as the context was cut in a wrong spot by chunking mechanism, the produced result was wrong because of the lack of the entire context, necessary to produce the correct result.
Why does it happen? The vector match is less precise when several ideas are present in the chunk, and depending on the surrounding text and the place where the text was cut, the match may simply fail to find the necessary parts of the context because they have a larger distance to the query than some other parts of that context present in different chunks. Like if you search the elements by a query describing the element (naturally close to the title vector), the selected chunks are likely to be short and contain the title without the stable guarantee to contain the body entirely. -
Slider window approach precision is not as good as “atomic idea” because several chunks are likely to contain the same parts of text mixed to other parts of the document, and there are too many factors that can affect the vectors (what I call noise). While in “atomic idea” approach, you get the whole item per chunk (and if the searched item is a “container” of chunks–say an article containing several subsections–, with the current approach to the “embeddable object” you will get the parent item + closest matches among its children on the first run, and if that’s not enough, you can select all children for the parent either on the first run or in a subsequent query).
So, what do you guys think?
Interesting stuff. I am in favor of the atomic idea approach. Of course, much depends also on the type of question one would expect and the embedding and retrieval approach must reflect that. But as a principal idea, ensuring that one chunk presents a complete idea makes a lot of sense to me.
However, I wonder: in practice, isn’t it possible that multiple different sections within a legal document relate to the same or a similar “atomic idea”. If so, do you currently account for that in your embedding and retrieval process?
On a separate note, I am also currently working on another proof-of-concept that builds on the semantic chunking approach and involves creating an automated workflow for a regulatory benchmarking. Will share a bit more details once I have concluded the PoC.
The “atomic idea” makes a lot of sense. I think the methodology I am working on is related, although it approaches the atomic idea from the outside in rather than the inside out (as yours does).
However, my approach is also based somewhat on the “layout aware” concept of chunking/embedding, which is discussed in this AWS Textract article: Amazon Textract’s new Layout feature introduces efficiencies in general purpose and generative AI document processing tasks | AWS Machine Learning Blog
Here are a couple of charts (you’ll find them towards the end of the article) representing the LLM results from layout-aware vs non layout-aware embeddings:
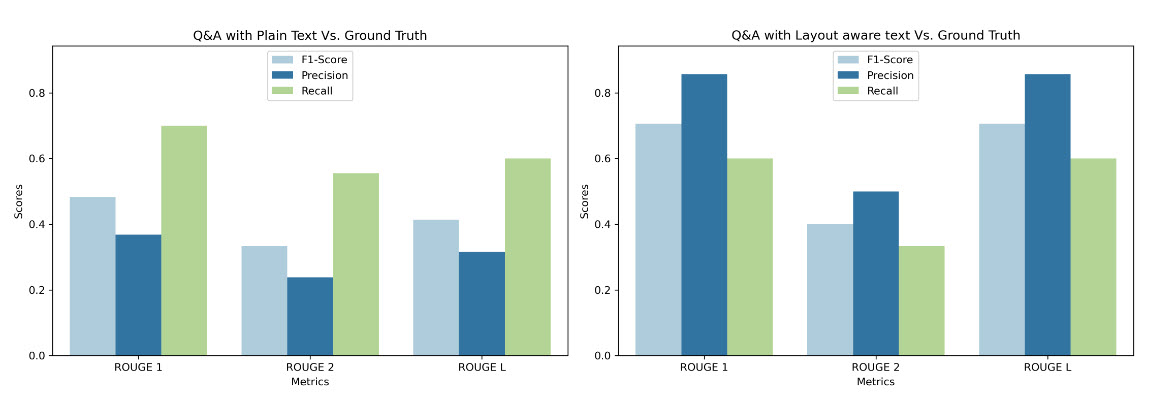

While your approach is more granular and may, in fact, be the best, I think mines shares in your core principal of getting a whole item within a chunk.
At any rate, thank you for your explanation. I struggled to find a way to characterize “numeric chunking”, and “sliding window” is a perfect term!
I know in my case, this is exactly what I want. The biggest problem I’ve run into with my labor agreements knowledgebase is failure to retrieve comprehensive answers. If someone asks about the rules for “holiday pay” for all categories of workers, that’s exactly what I want returned – every chunk where this is discussed.
So, it seems to me that the most comprehensive cosine similarity search for “holiday pay” would be the one that brings back every chunk where this “idea” is expressed. Chunks that only contain this idea will have the highest results (what we want) as opposed to chunks that contain this idea and other text (noise).
In my hierarchal / semantic chunking process, I identify in the chunk (via the title or some other metadata) where in the document hierarchy each chunk belongs.
That’s always the case because a given subject has multiple “atomic” ideas within it. So when your query is about a bigger subject, multiple “ideas” are returned by the engine. Another case is when the same idea is presented several times in the document (repetitions) in slightly different wording.
Usually, the engine returns many results, but they can be more or less grouped together in clusters (when they have distances to the query similar to each other). So, for example, you’ll get 50 results, where the first 3 will be around 89% match, then 5 around 75, then 10 around 68, etc.
In practice, only the 3-4 first “clusters” are needed to form the reply. So we use weaviate, which has a built-in mechanism to limit the results by the number of clusters.
To top that, we also use a set of “results pre-processing,” where a set of models goes through the results and evaluates their “completeness” first. Then, they check if items contain references to other elements not present in the results set and grab that to go with. Finally, they remove the items that do not contain the searched answer to form the “final set of results” to be posted to the answering model.
Once the answering model produces the answer, another set of models reviews it and checks whether the answer is not contradictory to the totality of the context (kill hallucinations) and which pieces were used as the base for the final answer.
Then, the whole set of data (query, answer, selected context pieces, answer-forming pieces) is returned to the application to be used in the app logic.
@ LAWXER, we killed the “layout” chunking approach from the very beginning because our goal was to build something that is capable of understanding the semantics/data independently from its form. So, all application workflows were aimed at repeating the human understanding and analysis workflows, where only raw data was available in the form of a flat text string (totally unformatted). We took this approach to be able to use the same engine to use speech as input (no formatting in speech) in future development.
Relying on data format to analyze its composition will block you in the future because the engine will be built around the format (or to require format) and not the pure data (in any format).
Do you have the “parent” element (tree branches) embedded as well as the child-only (tree leaves) in your RAG engine? Because your query is more aimed to elements containing rules about “holiday pay” (higher level) that supposes you get back the parent elements?
Also, do you chunks contain “purpose” field in the vectors, describing the purpose of the chunk / summary of the subject in the chunk? If not, you end up with too many types of data and it is hard to find the related pieces if there is no “grouping” them by subjects.
Personally, I think you’re facing this issue because of the poorly thought structure of “embeddable objects”. But I might be wrong. Do you have any examples of how your chunks are presented to the embedding model or database tables used for them?
Your approach sounds very solid. I would not entirely undermine the layout approach though. Consider the fact that a human will have likely put in some thought into the structure of a adocument. So maintaining some form of alignment / link to the original structure also ensures that the original thought process is not lost.
Agree, layout is something our brain uses as a shortcut to group/separate elements in the document. But that’s not the only mean available to us.
The only reliable “patterns” which will be always present in raw data and can be used to structure it are (to my opinion):
- Order of data pieces, because we are not capable to perceive all data at once, so we focus on elements at various levels of abstraction.
- Separation of data pieces (in text we use subjects change as a separator between data elements, in visual data it is edges and colors), because we are not capable of understanding the data as a whole and indivisible item but rather as a system of elements.
- Relationship between data pieces, because in order to “understand” data, we need to rebuild a “mental representation” of data, which is a system of elements in our minds, so relationships between the elements allow us to have multiple levels of abstraction (zoom into details or zoom out to see the system).
So what I’m building is the workflow that separates the elements of text on slightest subject change (#2), then uses order of elements (#1) to build the relationships (#3).
And yes, the structure in database correctly reflects all levels with ability to zoom in/out or walk by order, to allow comprehensive “understanding” and retrieval of needed elements/structures.
In reality is even simpler than it sounds on paper.
Look, again I think in general I tend to agree with you.
I look at this from a very practical point of view - under consideration of the types of documents I am dealing with, which are not legal contracts. Often you have the case that a title has an important informational value and serves as context to interpret the information in the section body.
For example, you may have situations where a similar topic is discussed at different points in a document body. However, the context within which it is discussed my differ and you may only be able to discern the difference with an understanding of the section titles where the information are located.
So this is for me where I see the value of having an understanding of the layout and its role in the logical structure and interpretation of information.