The “atomic idea” makes a lot of sense. I think the methodology I am working on is related, although it approaches the atomic idea from the outside in rather than the inside out (as yours does).
However, my approach is also based somewhat on the “layout aware” concept of chunking/embedding, which is discussed in this AWS Textract article: Amazon Textract’s new Layout feature introduces efficiencies in general purpose and generative AI document processing tasks | AWS Machine Learning Blog
Here are a couple of charts (you’ll find them towards the end of the article) representing the LLM results from layout-aware vs non layout-aware embeddings:
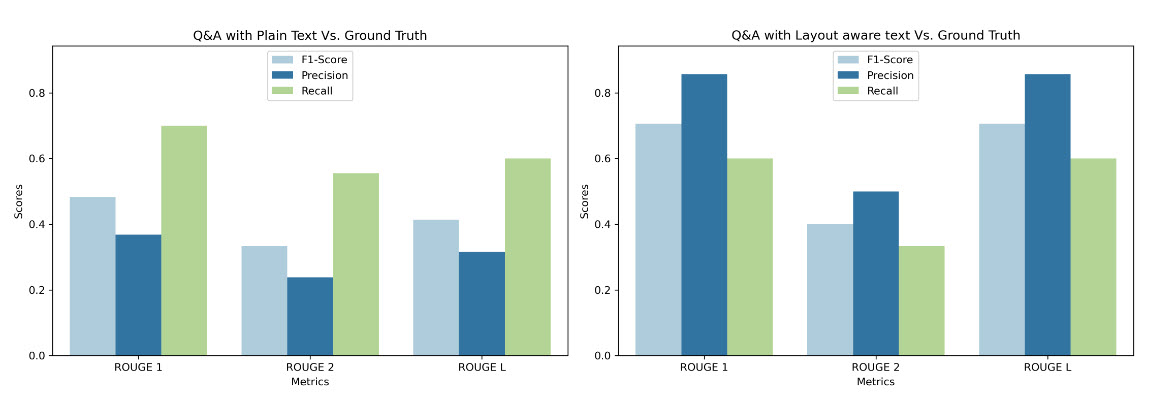

While your approach is more granular and may, in fact, be the best, I think mines shares in your core principal of getting a whole item within a chunk.
At any rate, thank you for your explanation. I struggled to find a way to characterize “numeric chunking”, and “sliding window” is a perfect term!