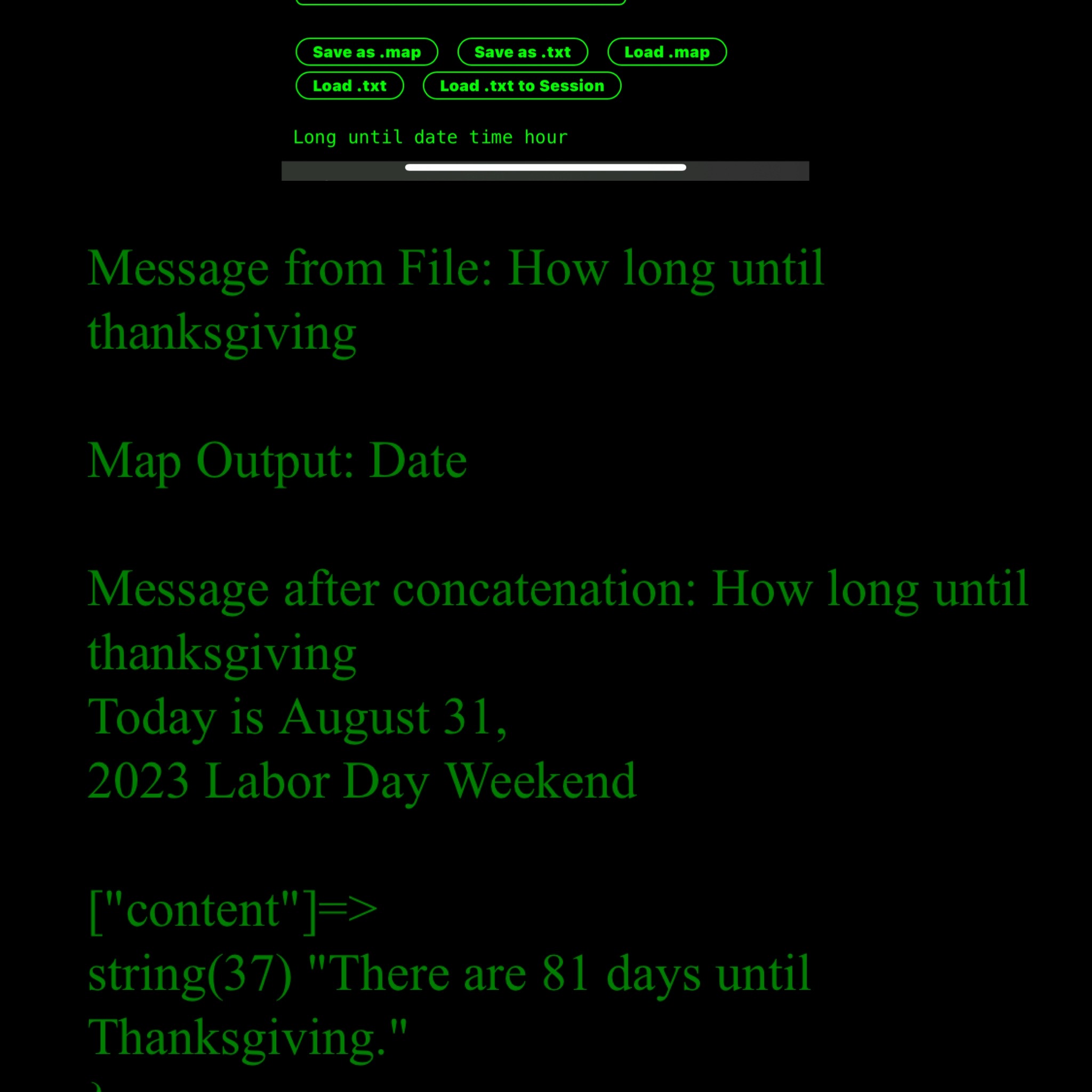
So I just had the bright idea of giving my bot an awareness of the time of day. Pretty simple, just get their timezone from the front end, pass it back, and pass that as a template string.
How could I do this same thing with maybe a summary of current events that happened that day?
Might be way too much as far as tokenage and the strings you have to interpolate.
I’d have to call an API, get that data, and than send it back in the same way, but maybe in a super summarized way? Does any API like this exist?
Inserting news with every question would be excessive token usage.
Instead, one can use the functions feature to create an API interface that the AI can use. It would call for the function when it feels the function is necessary for fulfilling the user’s request with more knowledge.
You could write code to return results from a web search or other news feed when a “get_todays_ news” function is used.
Bing AI chat itself, based on OpenAI, uses excessive web searches to answer just about any question.
It seems to me like OpenAI could do a daily embedding of all the news websites from around the world and update it’s knowledge. If it’s not being done for the public to access, it definitely makes me think some billionaire hedge-fund manager somewhere IS doing it, and capitalizing on the advantage in predicting markets.
Why do I say that? Because it’s too easy to do, and too obvious, and too valuable to miss. Just like how OpenAI became “closed AI” the minute they realized the market value, I’m sure the same thing is happening in secret regarding current news. It’s a no brainer.
Of course the competition to those hedge fund managers are the ones who are using Llama2 to do the same thing, and doing their own embeddings onto that open source system
News aggregation is a thing that happens daily, most large information companies have such feeds, Microsoft, google, Associated Press, etc. etc. The two areas that you may not be aware of the difficulty in are data sanitisation/quality control and updating the model.
The first here is data sanitisation and quality checking, there is a great deal of “news” that is not factual, accurate or of sufficient quality as to improve the model if it were added, so that problem needs to be solved.
The second part is that “updating” the model to include this is not a simple process, it’s expensive and it takes time to do. If you want high quality results from a model then you need high quality input that is integrated into the model, that is still a challenge to automate.
You might be able to stay under the token limits if you split the processes a little bit.
For example, first scrape and store just the text from your news websites. Next, have GPT “read” and summarize what you scraped into much shorter versions, and save those summaries as variables. (You can split this read/summarize step into multiple processes if you’re hitting limits).
When all the news for the day is summarized/shortened in string variables, send those variables to another process that reads all the summaries and returns a top level summary of news for the day.
It would take a while and burn through tokens, but it’s possible if you break it into smaller steps
Ideally the model would have a way to have knowledge about which news websites published which content, without actually incorporating that news article content as statements of fact that it will actually consider as true.
However this may be an “unsolved problem” in LLM currently, because ultimately all text it’s trained on has ‘come from somewhere’ or another, and it cannot offer attribution, nor “truthfulness” in that deep a way.
I think the key to this will probably involve keeping news articles in a totally separate database or neural net, and then allow the “main net” to submit sub-queries (i.e. prompts) to the “news net”, extract the info, and then present links to those articles, without even storing the articles. Probably even storing entire articles might be considered a copyright issue.
Possibly something like IPFS could be used to offload the article storage to other storage providers who are more willing to store (in a decentralized or untraceable way) to archive it for the future, and get rid of the “broken links” problem.
This is what embeddings and knowledge graph databases are for. This is why I prefer to call GPT a “reasoning” engine. We can augment it with information that reflects a query using embeddings, and then GPT can “reason” / filter out the necessary bits to return a succinct response which can then be explored.
Because okay if chatgpt is sending the message object each time right,
so lets say you’re on your twentieth message, its then sending back that messages object with the entire conversation to the bot.
So that gives you the opportunity to either pre process which is take that api call with the long message object and manipulate it somehow or post process.
You could use your own sort of weighted system or graph idk. Im honestly not the best coder on my team im just having this idea, i have someone much better at data science than me.
But I’m not talking about embeddings im talking about like inventing a type of processing that would just completely confuse your competition as to how youre achieiving what you’re achieving.
Another rudimentary way with basic tasks you can do it is the change the system prompted based on different array of cached strings. So instead of saying “good morning” the same way every time. It decides what time of day it is, randomly selects a string from an array of morning greetings and pushes that to the prompt. (but this doesnt work 100% of the time.)
but the idea is you manipulate the strings with pre or post.
My actual idea i want is to be able to create like an array of strings that exist as “thoughts” and than when a certain keyword happens, it than looks at that array and forms an opinion based on that array of strings, or at least incorporates it into its decision. (but did i just describe embedding?)
This surprised me OpenAI got the article his own self the payload has only a headline and a link to npr text news this is new
Breaking news
Message from File: Breaking news
Map Output: Breaking
Message after concatenation: Breaking news Tell user Trump pleads not guilty to Georgia election interference charges Trump pleads not guilty to Georgia election interference charges By NPR’s Washington Desk Updated Thursday, August 31, 2023 • 11:45 AM EDT
[“content”]=> string(1344) “This is KL3GPT with breaking news. Former U.S. President Donald Trump has pleaded not guilty to charges of election interference in Georgia. The charges stem from allegations that Trump pressured election officials to overturn the results of the 2020 presidential election in the state. Trump appeared in court earlier today and entered his plea. His legal team argued that his actions were within his rights as a private citizen and did not constitute interference in the election process. The defense also claimed that Trump’s statements were protected by his First Amendment rights to free speech. However, prosecutors countered that Trump’s actions amounted to an abuse of power and an attempt to undermine the democratic process. They presented evidence of phone calls and conversations in which Trump allegedly pressured election officials to “find” enough votes to overturn his defeat. The judge presiding over the case set a trial date for next month. If convicted, Trump could face significant legal consequences, including fines and potential imprisonment. This is a developing story, and we will continue to provide updates as more information becomes available. Stay tuned for the latest news on this case. For more details, you can visit the link provided: Trump pleads not guilty to Georgia election interference charges This was KL3GPT with breaking news.” }
This sort of mapping is powerful but limited and needs a way to deal with more than one map being returned haven’t figured that out yet
Thanks for clarifying. I knew about embeddings. I should have said it more clearly which is that OpenAI’s models should be doing “daily news embeddings”. The end goal I was getting at was making a query like “How’s the weather in Dallas today?” work.
But OpenAI may consider themselves just a provider of tech, and expect other companies to do these kinds of news services rather then them. There’s no real “correct” answer to that. I may have just convinced myself OpenAI should follow KISS principle, and not get into news reporting.
What about taking a news feed, maybe RSS, converting the contents to JSON and uploading it via Code Interpreter?
Of course the details… but that’s actually straightforward and you don’t have to involve Chat(!) GPT with anything else than reading and conversing about the news.
PS. I see that the category is API but the title says Chat GPT.
This can be fully automated. Grab a free API for news and start developing the backend process right away. The issue will be adapting the selection process for which news you are interesting in when switching to whatever real source of news you finally opt for.
Let’s say you return a few JSON objects every morning at 6 am. Run your memory process and if the user inquires about the news start the RAG.
The basic implementation should still be easy.
And you don’t have to tell the model the date, it can infer from the news items. Append/add all news every day to the existing database and you should have easy criteria to follow a story, via recency and semantic similarity of the news items.