You are too funny!!

6 Likes
your original image enhancer was great for images that the new one isn’t good for, btw…
i miss the first one now!
FYI
Not how boats work…

v2 out

I think the tinge may be that a good white is reserved for transparency replacement - I’ve seen white things go transparent in generations.
4 Likes
I had the same issue yesterday.

Anyone up for a little challenge?
Make a person sit on a sofa when both the person and the sofa are provided as separate images.


4 Likes









When I encounter challenges with generating variations in skin color through image generation, I use medical skin condition terms such as Albino, Cyanosis, Jaundice, Rosacea, Vitiligo, and others.






5 Likes


Interessing in an medical way. Especially the colouring of the icterus looks really authentic! ![]()
And the cyanosis when you look at the eyes - reminds me of an anatomy lesson.
Well done ![]()
2 Likes

3 Likes





4 Likes

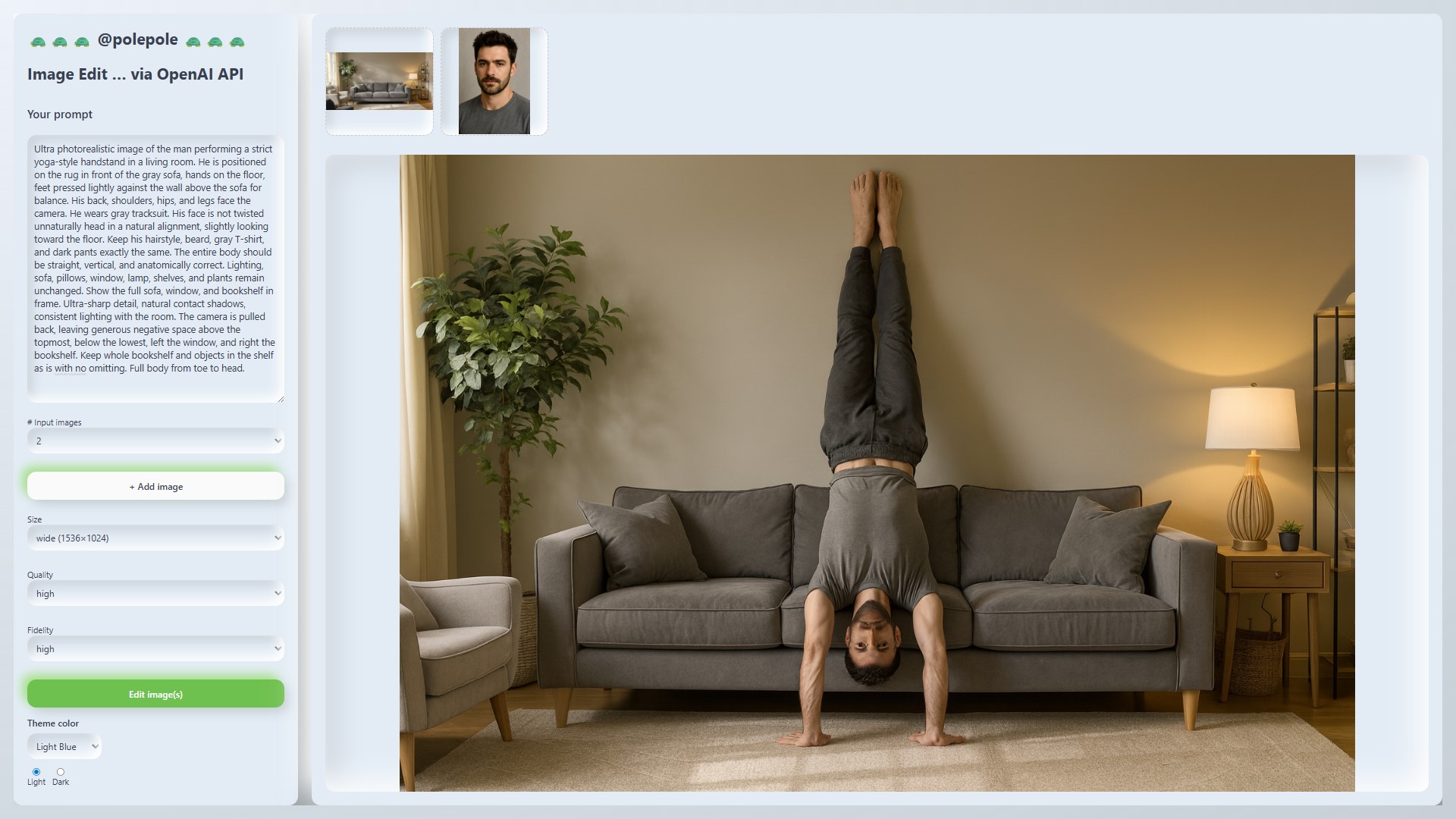



It’s a bit of a stretch ![]()
I was again going for ‘on the couch’
1 Like
My tries ![]()
This one is ok

But then


A analysis:
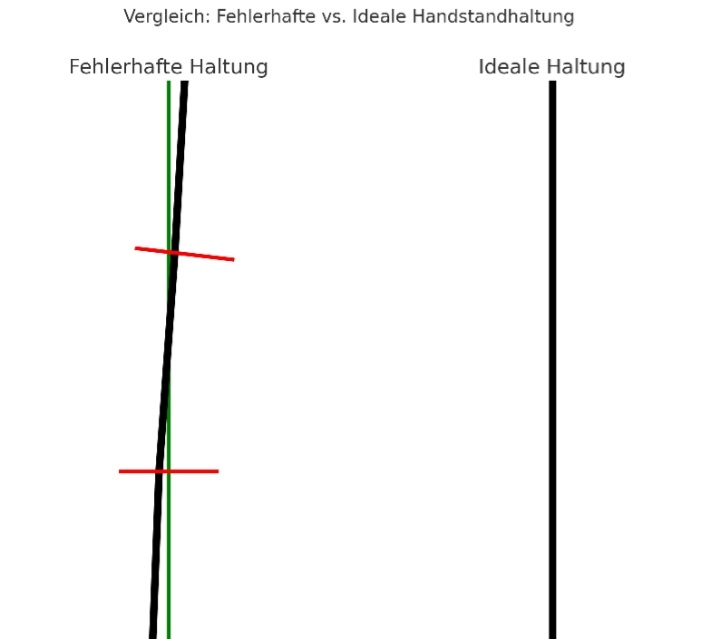
“Handstand, that’s a ‘difficult prompt’ for ImageGen.
Why difficult?
1. physics consistency
- handstand is an extreme balance.
- AI image generators struggle to really align the body vertically (often the hips, legs, or hands are not perpendicular).
2. rotation trick
- When we rotate a standing man, the anatomy is correct → but ImageGen does not know this automatically.
- Instead, it tries to ‘paint’ a handstand directly → often errors occur (twisted arms, faces, unclean floor contacts).
3. context objects (floor, couch, wall)
- generators are good in ‘person + generic environment’.
- But as soon as you combine a specific body state + furniture, the error rate increases → because this occurs less frequently in the training data.
4. face + posture at the same time
- AI wants to optimise faces (because ‘human = face’ is highly weighted in data).
- But in handstand the face would often be distorted / upside down → conflict → leads to unnatural blends
Therefore:
Your approach (first generate normally, then flip) is actually better.
ImageGen directly → makes too many cognitive shortcuts → result looks ‘half right, half fantasy”
5 Likes

Something hard for it based on training data I think.
When Image Generation works with reasoning model and it didn’t like what it was doing, it says, “Hmmm, let me try again, that didn’t work, one more time, one more area, one more time…” It tries over and over. It gets into a loop until I click on stop button…
In this example, I selected "GPT-5 Auto”, the rooter switched to Thinking.
It could be a bug, maybe. In one instance, it created 20 images consecutively.
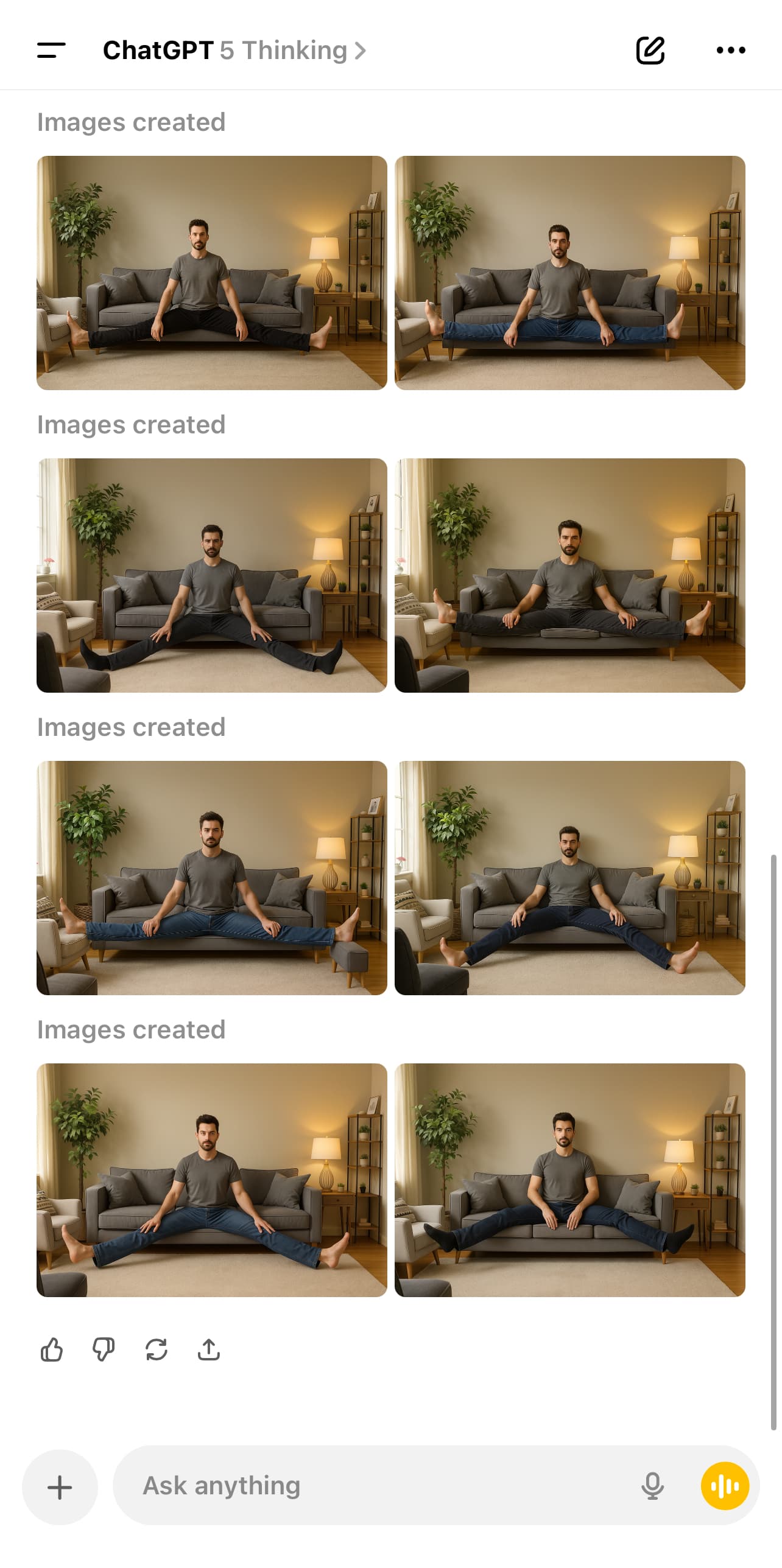
5 Likes
extremely grateful for your follow up on that
it’s a huge timesaver for me
2 Likes