I’m getting a ridiculously high token usage in the playground with gpt-4o-mini.
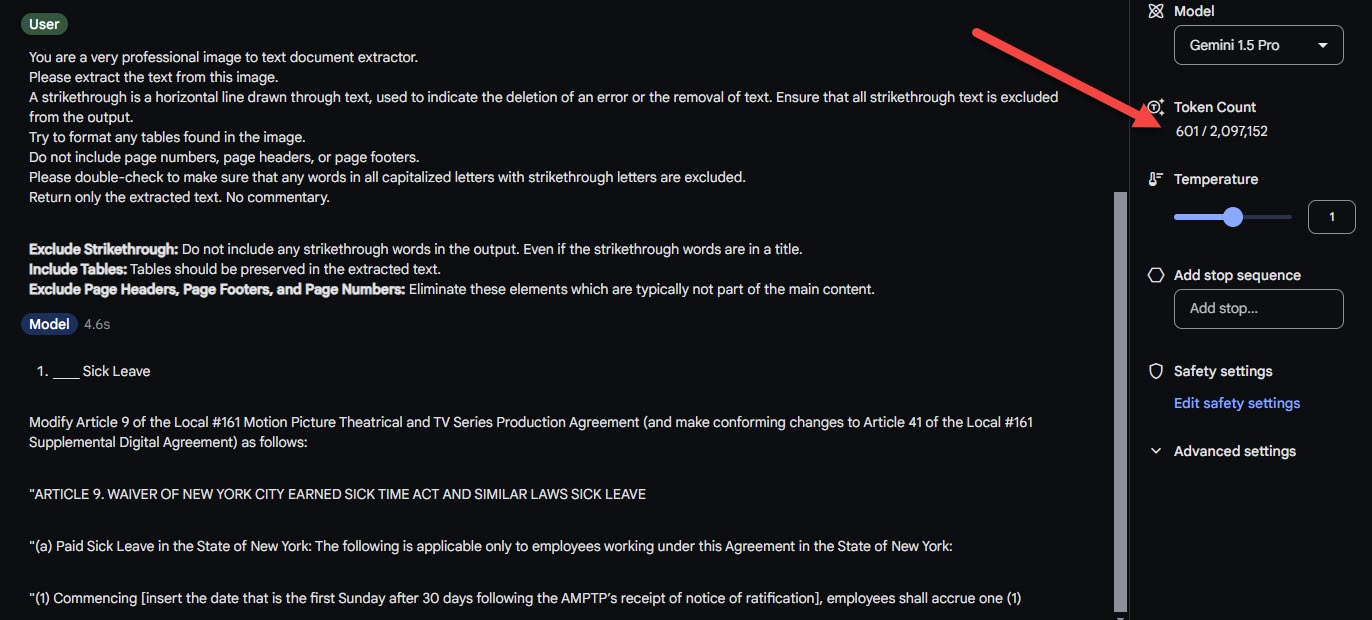
Here is the image:

This is the prompt:
You are a very professional image to text document extractor.
Please extract the text from this image.
A strikethrough is a horizontal line drawn through text, used to indicate the deletion of an error or the removal of text. Ensure that all strikethrough text is excluded from the output.
Try to format any tables found in the image.
Do not include page numbers, page headers, or page footers.
Please double-check to make sure that any words in all capitalized letters with strikethrough letters are excluded.
Return only the extracted text. No commentary.
Exclude Strikethrough: Do not include any strikethrough words in the output. Even if the strikethrough words are in a title.
Include Tables: Tables should be preserved in the extracted text.
Exclude Page Headers, Page Footers, and Page Numbers: Eliminate these elements which are typically not part of the main content.
This is the output:
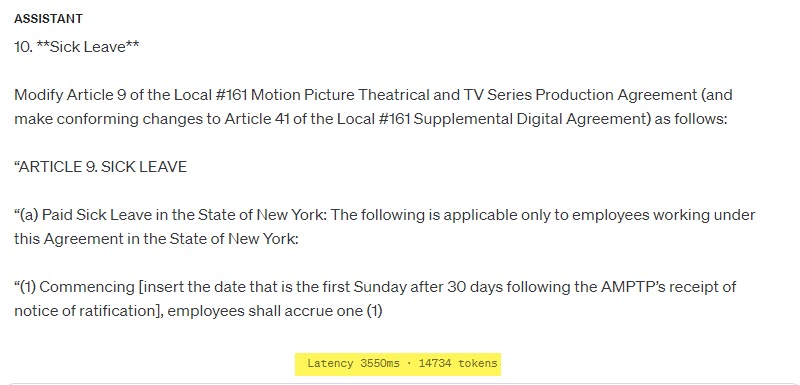
14,734 tokens. That’s nuts!
The OpenAI tokenizer reports an output of only 130 tokens.
Is the processing of this one small image costing me over 10,000 tokens?