I’m using responses API on python, I learned that you can use the “store=False” parameter to avoid storing the input / output. If I use it what happens exactly to the data? it’s all wiped out? Could be this enough?
Thanks in advice.
I’m using responses API on python, I learned that you can use the “store=False” parameter to avoid storing the input / output. If I use it what happens exactly to the data? it’s all wiped out? Could be this enough?
Thanks in advice.
It doesn’t remove data (logs) that is previously stored and just checked my dashboard, no way to delete previous log files. Going forward it will disable it.
Ok, thanks. I’m ok with that, I need “from now” not to save anything in OpenAI servers, so I gues that store=False will work.
Thanks.
You can erase the data stored by store:true
That is, if you have recorded the response_id.
Thus, there is no connecting an automated listing with a delete method in code
To combine them, I offer a Python solution.
Open browser “developer tools” after going to platform.openai.com
Go to the “network” tab. You can detach the whole viewer and have it in a different window or even different monitor for visibility.
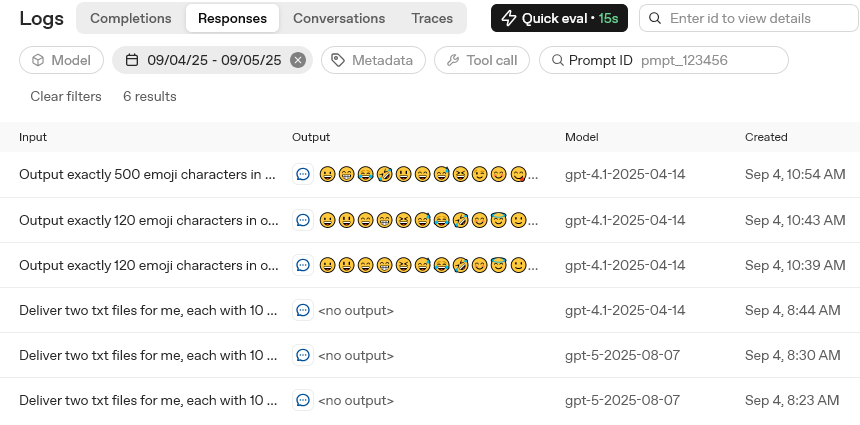
Navigate to dashboard->logs->responses
View some of the annoying tests that were logged, because OpenAI made store:true the default, filling up your account with privacy violating junk ready for the hacker that gains access to exploit.
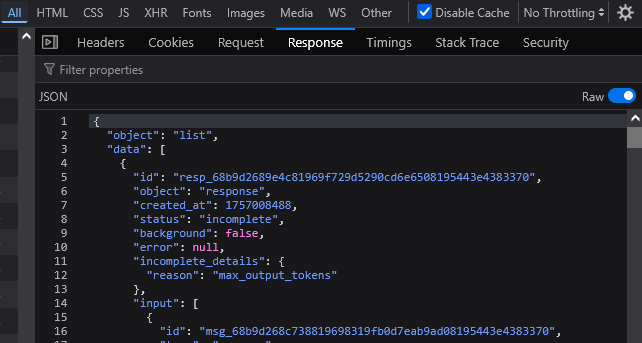
You’ll see URLs for GET
https://api.openai.com/v1/responses?include[]=message.input_image.image_url... in the developer tools network logs:

You can click on these, view the entry’s “response” and see the API response object OpenAI won’t give you on the API with an API key: all the shown log entries, the entire object, which can be quite large, because viewing logs isn’t just a list, its a transfer of a megabyte of data to the browser, especially with base64 images or audio right there:
Now it’s time for you to get out the data you want: make queries to particular dates or types of requests, get the paginated results (still not complete queries because of the size. You also may need to scroll to get more and more network requests made.
response_listNN.json, where NN is an optional number 00-99. You also can paste some JSON into the Python itself as RESPONSE_LIST (a place is provided which requires a triple-quote r-string (raw)).import json
import os
import re
import sys
from concurrent.futures import ThreadPoolExecutor
from pathlib import Path
from typing import Final, Iterable, List
import httpx
import requests
###############################################################################
# Configuration & constants
###############################################################################
OPENAI_API_KEY: Final[str] = os.getenv("OPENAI_API_KEY", "").strip()
if not OPENAI_API_KEY:
sys.exit("Environment variable OPENAI_API_KEY is required but missing.")
AUTH_HEADERS: Final[dict[str, str]] = {
"Authorization": f"Bearer {OPENAI_API_KEY}",
"Content-Type": "application/json",
}
RESP_ROOT: Final[str] = "https://api.openai.com/v1/responses/"
CONV_ROOT: Final[str] = "https://api.openai.com/v1/conversations/"
RESPONSE_FILE_RE: Final[re.Pattern[str]] = re.compile(r"^response_list(\d{2})?\.json$", re.I)
BLANK_SPLIT_RE: Final[re.Pattern[str]] = re.compile(r"(?:\r?\n\s*){2,}") # ≥2 consecutive blank lines
ID_SALVAGE_RE: Final[re.Pattern[str]] = re.compile(r'"\s*id\s*"\s*:\s*"(resp_[^"]+|conv_[^"]+)"')
# Paste inline JSON blocks here if desired (may contain multiple blobs separated by blank lines)
RESPONSE_LIST: str = r"""
""" # noqa: N816
###############################################################################
# Utility helpers
###############################################################################
def _salvage_ids_from_text(text: str) -> list[str]:
"""
Best-effort extraction of response/conversation ids from arbitrary *text*.
Returns de-duplicated ids in first-seen order.
"""
ids = [m.group(1) for m in ID_SALVAGE_RE.finditer(text)]
return list(dict.fromkeys(ids))
def _extract_json_blobs(raw: str) -> List[dict]:
"""
Split *raw* on multiple blank lines, trim, and parse each part into JSON.
Non-parseable segments are given a best-effort salvage pass to extract ids.
"""
blobs: list[dict] = []
for segment in BLANK_SPLIT_RE.split(raw.strip()):
segment = segment.strip()
if not segment:
continue
# Ensure we are trimming to the first/last brace to survive leading junk
start, end = segment.find("{"), segment.rfind("}")
# If we have no opening brace at all, try salvage directly on the segment.
if start == -1:
salvage_ids = _salvage_ids_from_text(segment)
if salvage_ids:
blobs.append({"data": [{"id": sid} for sid in salvage_ids]})
else:
print("warning: segment skipped – no JSON braces found and no ids salvageable", file=sys.stderr)
continue
# If we have an opening brace but no closing brace (truncated), try salvage.
if end == -1 or end <= start:
salvage_ids = _salvage_ids_from_text(segment[start:])
if salvage_ids:
blobs.append({"data": [{"id": sid} for sid in salvage_ids]})
else:
print("warning: truncated JSON – unable to salvage ids", file=sys.stderr)
continue
try:
blobs.append(json.loads(segment[start : end + 1]))
except json.JSONDecodeError as exc:
# Best-effort salvage: extract resp_/conv_ ids even if JSON is malformed
print(f"warning: JSON decode error, attempting salvage – {exc}", file=sys.stderr)
salvage_ids = _salvage_ids_from_text(segment[start : end + 1])
if salvage_ids:
blobs.append({"data": [{"id": sid} for sid in salvage_ids]})
# else: nothing salvageable; silently skip after warning
return blobs
def _gather_ids(blobs: Iterable[dict]) -> List[str]:
"""
Return every 'id' found under blob['data'][*]['id'] for all *blobs*.
"""
ids: list[str] = []
for blob in blobs:
try:
ids.extend(item["id"] for item in blob.get("data", []) if isinstance(item, dict))
except Exception as exc: # pragma: no cover
print(f"warning: malformed blob – {exc}", file=sys.stderr)
return ids
###############################################################################
# Deletion machinery
###############################################################################
def _delete_single(
item_id: str,
req_session: requests.Session,
httpx_client: httpx.Client,
) -> None:
"""
Dispatch deletion based on *item_id* prefix.
"""
if item_id.startswith("resp_"):
url = f"{RESP_ROOT}{item_id}"
try:
resp = req_session.delete(url, headers=AUTH_HEADERS, timeout=15)
if resp.status_code not in {200, 202, 204}:
print(f"warning: DELETE {item_id} – HTTP {resp.status_code}", file=sys.stderr)
except requests.RequestException as exc:
print(f"error: DELETE {item_id} failed – {exc}", file=sys.stderr)
elif item_id.startswith("conv_"):
url = f"{CONV_ROOT}{item_id}"
try:
resp = httpx_client.delete(url, headers=AUTH_HEADERS)
if resp.status_code not in {200, 202, 204}:
print(f"warning: DELETE {item_id} – HTTP {resp.status_code}", file=sys.stderr)
except httpx.HTTPError as exc:
print(f"error: DELETE {item_id} failed – {exc}", file=sys.stderr)
else:
print(f"warning: unknown id prefix – {item_id}", file=sys.stderr)
def _process_ids(ids: Iterable[str]) -> None:
"""
Fire off concurrent deletions for all *ids*.
"""
with requests.Session() as req_session, httpx.Client(timeout=20) as httpx_client:
with ThreadPoolExecutor(max_workers=32) as pool:
for item_id in ids:
pool.submit(_delete_single, item_id, req_session, httpx_client)
###############################################################################
# File handling
###############################################################################
def _collect_files() -> List[Path]:
"""
Locate all response_list*.json files in the working directory that have
not yet been processed (i.e., not renamed with the '-done' suffix).
"""
return [
path
for path in Path(".").iterdir()
if path.is_file()
and RESPONSE_FILE_RE.fullmatch(path.name)
and not path.name.endswith("-done.json")
]
def _process_text_block(text: str, label: str) -> tuple[int, int]:
"""
Parse *text* for JSON blobs (with salvage), delete their ids, and emit summary.
Returns (resp_count, conv_count).
"""
blobs = _extract_json_blobs(text)
# Gather and de-duplicate ids while preserving order
ids_all = _gather_ids(blobs)
ids: list[str] = list(dict.fromkeys(ids_all))
resp_count = sum(1 for _id in ids if _id.startswith("resp_"))
conv_count = sum(1 for _id in ids if _id.startswith("conv_"))
if not ids:
print(f"deleted 0 responses and 0 conversations from {label} (no ids found)")
return 0, 0
_process_ids(ids)
print(f"deleted {resp_count} responses and {conv_count} conversations from {label}")
return resp_count, conv_count
def _process_file(path: Path) -> None:
"""
Open *path*, perform deletions for every id found, then rename to -done.json
only if something was actually deleted (avoid renaming on parse/salvage failure).
"""
print(f"loading file {path.name}")
resp_count, conv_count = _process_text_block(path.read_text(encoding="utf-8"), path.name)
# Only mark file as done if we actually deleted at least one id
if (resp_count + conv_count) > 0:
path.replace(path.with_name(path.stem + "-done.json"))
###############################################################################
# Main routine
###############################################################################
def main() -> None:
if RESPONSE_LIST.strip():
_process_text_block(RESPONSE_LIST, "hardcoded list")
for file_path in sorted(_collect_files()):
try:
_process_file(file_path)
except Exception as exc: # pragma: no cover
print(f"error: failed processing {file_path.name} – {exc}", file=sys.stderr)
if __name__ == "__main__":
main()
"""
The script:
• Deletes both response (`resp_…`) and conversation (`conv_…`) objects,
dispatching the correct HTTP method per id.
• Accepts single or multiple JSON blobs pasted into one file (or into
the hard-coded `RESPONSE_LIST`) by splitting on blank lines.
• Best-effort salvage: if a blob is truncated and not valid JSON, it will
attempt to extract `resp_…`/`conv_…` ids from the text and proceed.
• Only renames a processed file to `*-done.json` if at least one id was
actually deleted; otherwise the file is left untouched for remediation.
• Keeps the previous file-renaming overwrite behavior and minimal console feedback.
"""
Voila: garbage is purged from this endpoint after you learn you will never store anything and never use any feature of Responses, each one of internal tools and server-state being a regression.
Before:
After: GONZO
Addendum: the clever person can write code that can elevate http protocols, follow redirections, emulate browsers, port knock and run CORS, and use code and Oauth to get session tokens and then use these APIs directly without API keys, despite OpenAI being extremely persistent at stopping automated calls. They should completely offer the feature so that developers can cleanly leave these experimented unwanted enpoints.
Additional notes: if the response from the platform log API call is large, which can easily happen with lots of images, the developer tools network monitor may neither show the entire reponse, nor may it completely save the response. In Firefox, you can use this about:config setting, increasing the value from 1MB to about 20 million:
devtools.netmonitor.responseBodyLimit
I just modified the script to also scrape out IDs from incomplete truncated chunks that aren’t closed JSON.
Unfortunately, this is not true. As discussed in this thread, OpenAI is retaining logs from the Responses endpoint indefinitely, despite misleading users to believe that they’ll be deleted after 30 days.
When you set store=False, you’re only making it so that the logs don’t show up in your account history that’s viewable to you. They’re still being retained on OpenAI’s servers. As you can see in the thread, all calls to Responses are still being stored going back to when the endpoint was introduced in March.
Fortunately, you are incorrect.
API usage is not used for training, and safety retention of API call to AI inference is 30 days. That is clearly articulated.
Erasing the server artifacts is with an API method, and there is no retention of them after deletion. It is clearly spelled out.
The only thing that is different from the documentation is specifically Responses IDs. That more than a “default 30” of this chat artifact for reuse is being employed, it seems persistent. It is not “logs”. Response ID is instantly unavailable and the storage is turned off and never employed when using store:false and nothing is retained from use of the API for reuse of ID as a chat mechanism.
Only those with zero data retention enrollment can get the safety rentention period turned off.
There’s lots of information to be read and understood. Reading and understanding will enhance your ability to write factually.
The documentation clearly spells out that logs will be retained for 30 days, but it can be demonstrated by investigating your account history that this is not true. You are choosing to believe that there is a separate, invisible system that is abiding by the stated timetables, which is wishful thinking to say the least.
As stated in this comment, if setting store=False was all it took to stop OpenAI from retaining your API logs, then malicious actors would simply do this, and there would be no point in abuse monitoring.