Wanted to start a thread documenting some details around working with the new Realtime API’s. Some things, like how it’s billed, aren’t super clear so hopefully this thread can act as repository for that knowledge…
First an experiment on costs… I have a simple instruction with two functions and I wanted to see two things. 1) how many input & output tokens is each request and do they bill you for silence…
As a test I sad “Hi”, the assistant replied, and then I waited 2 minutes before ending the session. As you can see I was charged for 1 request at 188 total tokens. They do not charge for silence which is good… The actual dollar cost was less then $0.01
6 Likes
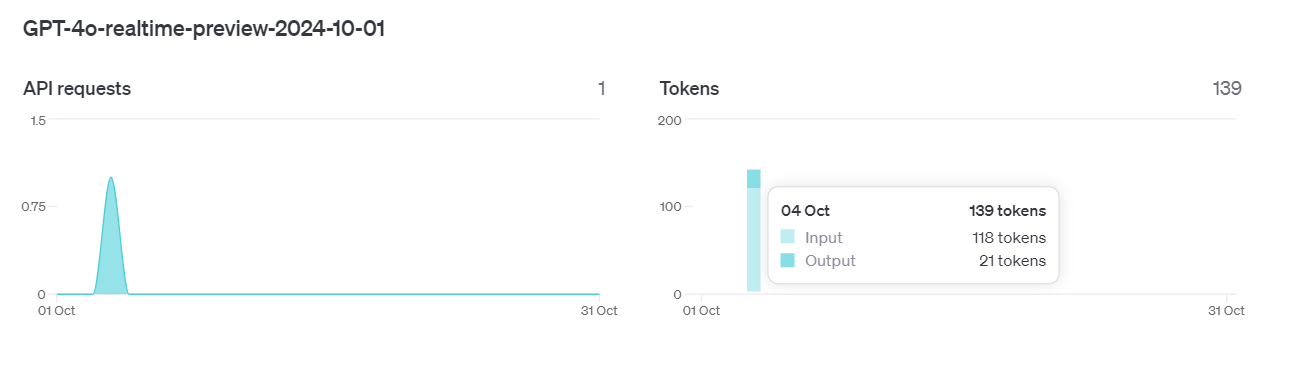
If we look at the stock prompt without any schema it’s 118 Input tokens:
The instruction itself is 110 tokens so there’s 8 additional tokens of overhead coming from somewhere but that seem negligible:
If we add a function to check the weather and then ask for the weather in seattle we can see the output tokens are slightly higher but the input tokens don’t seem to have changed. Not sure if that’s because it’s cached or what?:
2 Likes
Here’s some other costs tests around interruption…
I first created a new project and asked the model to count to 100. I then interrupted it by saying stop. I noticed that it had streamed 1 - 38 back to the client but it only had spoken 1 - 5 when I said stop.
Next I created a new project and asked the model to count to 100 again. It tried to first count by 10’s so I interrupted that with “no by 1’s”. This time I let it generate the full 100 numbers but I stopped it manually using the stop button.
My assumption is that output tokens is based on generated tokens and not necessarily spoken tokens. Since the model generates faster then it speaks you can expect to that you’re paying for more tokens then what have been generated when an interruption occurs. To verify that I did another test…
I asked the model to count to 100 again and as you can see it wanted to go by 10’s but I interrupted asking for by 1’s. This time I stopped it 24 in and then followed up by asking it how many it had counted to. It said 26 which would imply that the last delta of tokens didn’t get sent to the client when I interrupted it but it’s in the conversation history server side.
As one last test I asked the model to count to 100 again but this time I opened the log and watched the deltas stream in. The audio streams in alongside the text so when the text finishes chunking in the audio finishes shortly after. I stopped the playback while the model was on 47 but both the text and audio had long since finished streaming in. Another indication that playback rate is completely separate from audio generation rate: