I am using the gpt-4-vision-preview model to analyse an image and I have some questions about forming sequential requests. I may need to reprompt the model with a different question depending on what the model’s response is. To do this I am currently appending the model’s response to the message array and resubmitting the request to the API. My questions are:
Is there a limit to the number of messages that can be in the messages array?
Since the initial message with the image url is present in every request, am I being billed for image submission each time?
If yes, is there any way to not resubmit the image but keep it in context? Ideally I’d like to
I may need to ask up to 150 questions about a single image, and there may be up to 50 images to check meaning roughly 7500 requests in total. I need to minimise my bill as much as possible are there any strategies that make sense given the volume of requests?
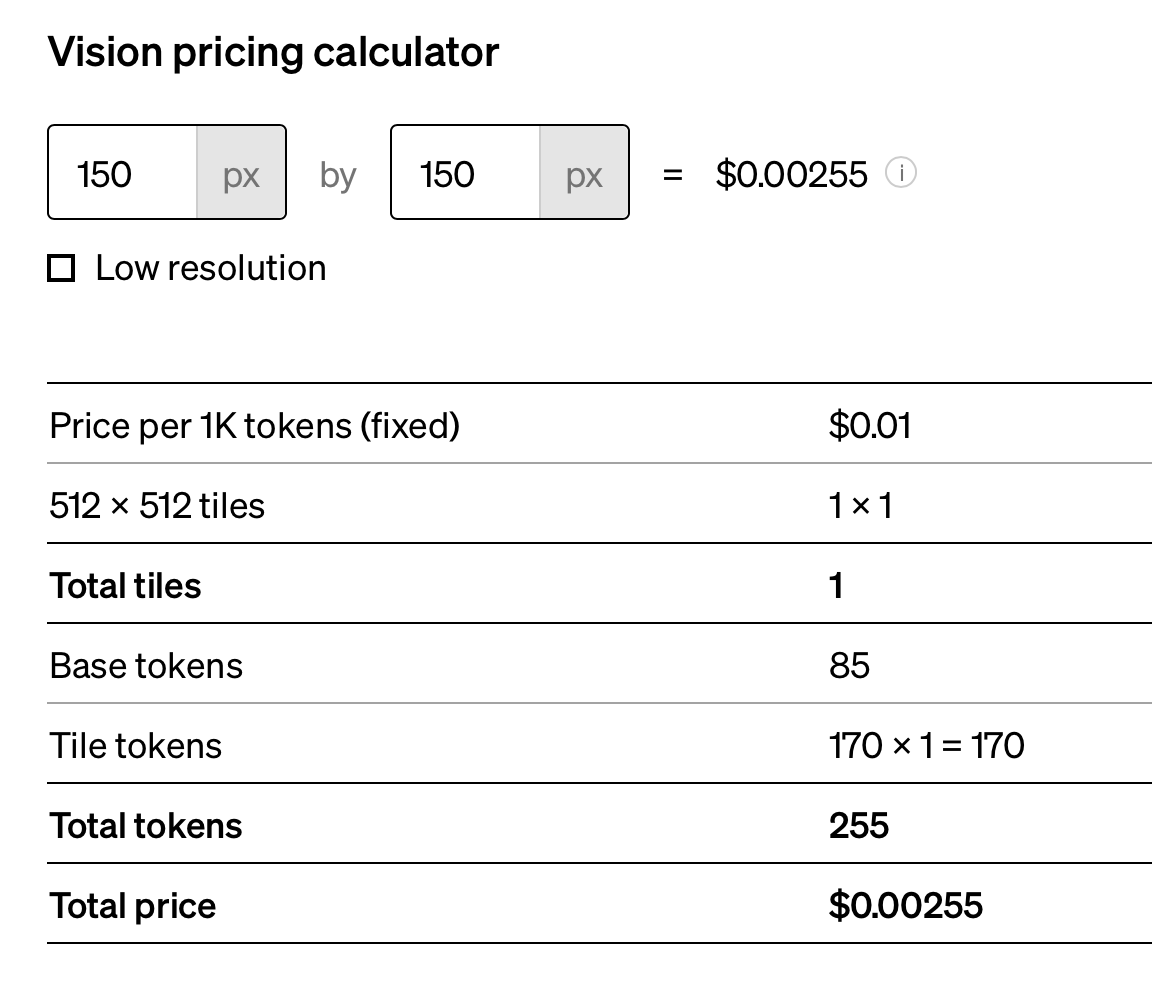
The image prompts are only going to be a single sentence of about 170 characters at max, is there any way to predict usage and cost? I’m struggling to come up with estimates for this project.
Any advice that can be given will be greatly appreciated!
The limit is 128k tokens, not messages. Each word is roughly 0.75 tokens.
Yes, the model is stateless. Each call is its own brand new universe to the model.
No, they have implemented a stateless design.
This is a hard one to answer, since you are charged for the image size on each API call. If the image is huge, you may try multiple questions at once, and only pay for the image once and get multiple answers. But the model response quality may degrade if you ask too many questions at once. So it’s a trade on image resolution and expected response quality.
A corollary to this, is if you have only a single question, you should get the best quality, but you take the hit on the image pixels each time.
So this is subjective.
From current pricing:
Take your total input tokens, divide by 1000 and multiply by $0.01. + Total output tokens, divide by 1000, multiply by $0.03. Each token is roughly 0.75 words.
Exact tokens require a library like tiktoken to estimate.
Finally, add in the cost of the image itself. This is a function of the image size (pixels) so it’s best to check out the pricing page and use the cost estimator for sending the image on each call.
Hey @curt.kennedy, I have one last question for you if that’s ok?
The questions I will be asking about the image are to check whether the image complies with some terms and conditions. The questions are mostly straightforward and don’t require additional context, however some questions won’t have inherent context.
I know that the Assistants API is able to do RAG so I could provide my pdf’s as context but it currently doesn’t support Vision.
Do you know of any work around for using Assistants with Vision?
If not, is there any way I can provide documents as context when prompting Vision models?
Could a potential solution be to include the relevant section/paragraph of the document as part of the prompt? E.g “Using the following paragraph as context: (PARAGRAPH). Answer the following question with regard to the image provided: (QUESTION)”
Almost all RAG’s right now are text based. If there were Vision support for Assistants, it would be a while out, since it’s not the norm.
But I have thought about RAG systems than use a mixture of vision and text. Just think the image as a URL or file, with a text description (from Vision), also embedded, and any associated text with the image (embedded as well).
This would be the starting ingredients to create a hybrid Vision/RAG system.
You may also want to look at models that create embedding vectors from the image directly too, instead of only embedding the text description from Vision.
As for promoting, that is another challenge. The Vision prompts are finicky. It took me several hours to get a working prompt on a very simple (I thought) task. You may have to iterate a lot to get the prompts dialed in.
@curt.kennedy The images are screenshots of a website so I also have the option to use Assistants and instead of an image use webpage’s HTML. Do you think that could be a better way to go? That way I get RAG capabilities and also I just realised that for 7500 requests to Vision, I’ll need to be on tier 5 to get that kind of rate limit! If the Assistant struggles gives me a poor output on the HTML then I could try using Vision with the screenshot on a case by case basis as a fallback.
Once again really appreciate the advice, you should think about setting up a https://www.buymeacoffee.com account, I’d love to give a little something back as thanks!
If you are trying to check if a website complies with certain terms and conditions, I was wondering if you could just fine-tune a base model from the HTML as input, and a binary 0/1 output, single token, at temp = 0, to see if it complies or not. If there are a handful of questions, then a fine-tune for each question or aspect of compliance, and 0/1 response.
Also mine the HTML directly with code, not sure what you are looking for in the compliance part here.
If it’s super visual, and you need vision, then you may have to play around with the prompting, or breaking the image into pieces, or different zoom levels, not sure. A lot more is involved when using the vision model. So I would put that on the back burner, and only use it if you really have no other options.
As for the RAG part, I am a bit confused, are you going to have the LLM generate a response back from what the system determines? It seems like you are classifying a webpage for compliance across several dimensions, and just storing the results. If so, you would use standard DB queries to gather your data, or use embeddings for search, but no “G” or generation is required, right?
For all of this, I would avoid assistants. I don’t use them anyway, as they are a thin wrapper over the API, and you have little to no control over the system.