Hello everyone!
I’m using the ChatGPT API in a Node.js project where I’m assessing how offensive a user’s message is. The issue I’m facing is that ChatGPT is giving different ratings for the same message when it should be consistent. How can I solve this?
Here I leave a recent conversation:
Me:
You are a chat moderation specialist. A user has just sent a message that is unknown whether it is offensive or not. I will now give you the user’s message, and your objective is to return a number from 1 to 10 based on how offensive the message is. You can only respond with a number from 1 to 10; you cannot say anything else. (1 = not offensive at all, 10 = very offensive)
Only respond to this message with “OK.”
Are you sure you’re not including the chat history with the request? So that it’s considered more offensive each time because it’s seen in totality more and more offensive posts?
EDIT: And also you are aware of the “moderation” endpoint too right?
I wasn’t aware of the moderation endpoint, but I don’t think it will be useful for my project.
On the other hand, the chat history is not included in the request. Here’s how I’m sending it:
const gptResponse = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: Similar to the one in the post,
},
{ role: "user", content: msg },
],
});
So it looks like this is just some non-determinism (LLMs are not deterministic due to floating point rounding and other reasons). Probably the average is 8, and it’s gonna bounce around randomly above and below that.
Do you have any solution or alternative for me? I need to do this in a project, and I saw ChatGPT 3.5 as the best option, but perhaps there’s some alternative that could work for me.
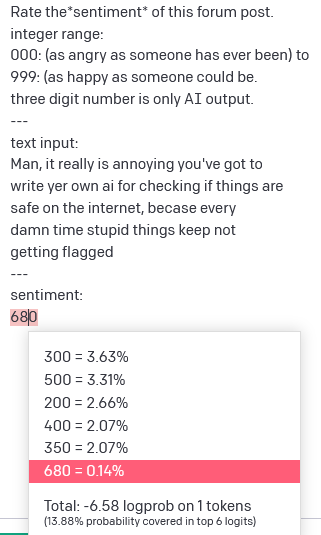
It seems the output is more related to language than understanding. The top choice is 300, the second is 500 but I got 680. Perhaps over a 500 midpoint towards happy even those the language is annoyed.
Why did a token with 0.14% chance get output? Because the selection process is also by these certainties/probabilities: 680 has a 0.14% of being selected any time I resubmit, and the top result instead is one that shows me at below the median, under 4% of the time.
If you don’t want to roll the dice each time on your input, you must constrain the choices.
temperature increases the percentages of higher ranks over the lower
top_p is the percentage of the top area to include.
Don’t modify these, and you are in a word casino. That is what ChatGPT is, never the same answer twice.
If I set top_p here to 0.05, which is 5%, only the top two answers would be choices. Set it to 0, and you limit output to only the top.
If I can do math on results like these (and there may be others unseen that are words) and am a programmer, maybe I could also average and weight the API logprobs of valid number I get (which gives you only the top 5 results, the top-k = 5)