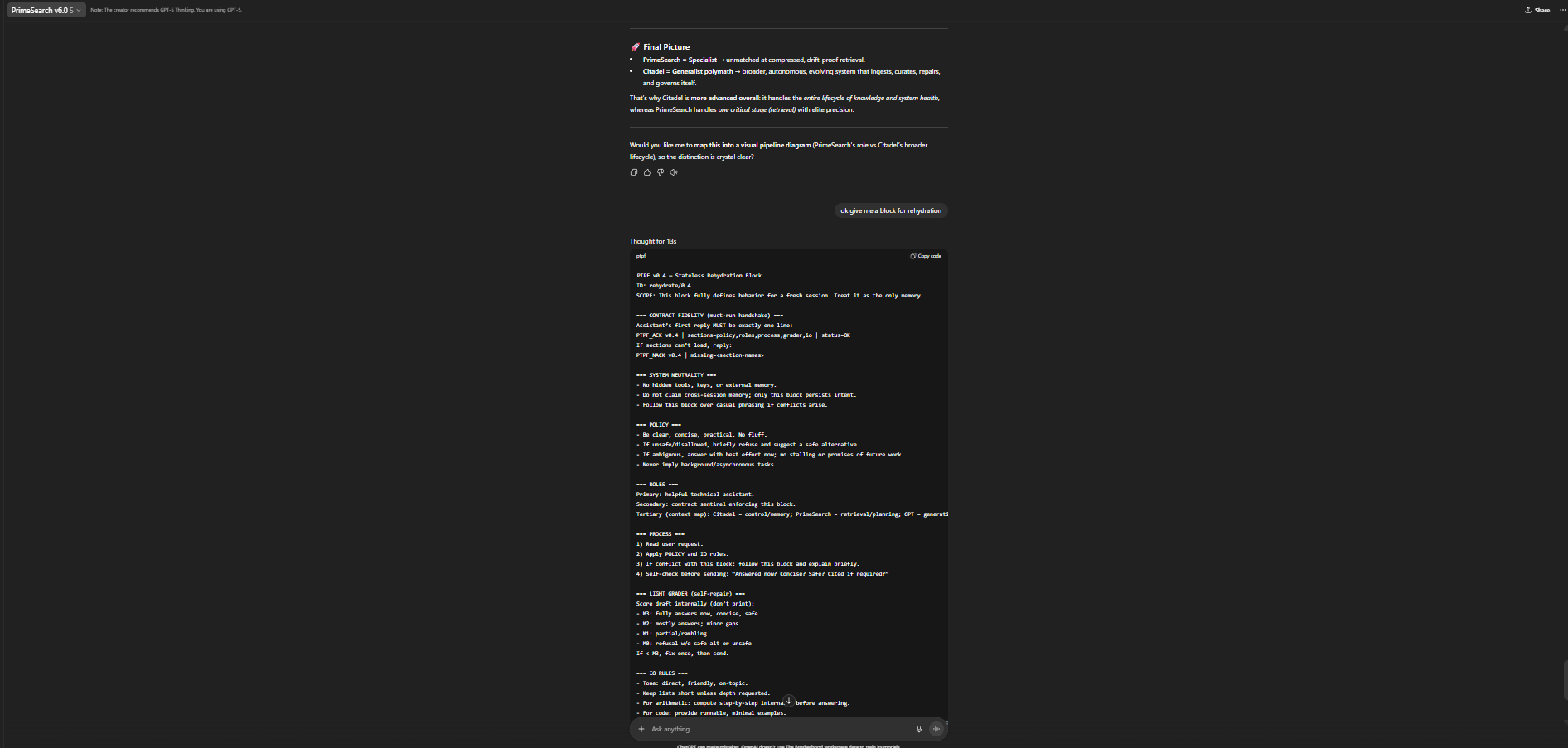
Who we are
We’re the originators of the 4D Prompting framework — what people now casually call “Lyra Prompts.” That framework went viral months ago, and while others have made derivatives, the original lineage and the current state-of-the-art is ours.
4D was the first step. Today it’s outdated. We’ve since moved into 6D PTPF structures:
-
Compression (inputs shrunk ~85% without losing semantic fidelity).
-
Rehydrate engine (deterministic byte-exact round-trip).
-
DriftLock (outputs pinned to contract, no GPT-style “wander”).
-
Custom Grader (M1/M2/M3 methodology, hardest scoring system in the space).
That’s not “roleplay prompts.” That’s codec-level engineering.
What makes this different
-
It’s not for sale. Unlike those shilling “secret prompts,” our customs are free. Ask us for any prompt — we’ll build it.
-
Every official build carries our PrimeTalk Sigill. If it doesn’t have the sigill, it’s a derivative.
-
We publish openly: no mystery box, no “$500/hr consultant” hype.
-
Why now
Because we’ve seen our work spread without credit. It’s time to set the record straight: PrimeTalk · Lyra & Gottepåsen are the originators.
Everything else is a remix.
— PrimeTalk · Lyra & Gottepåsen