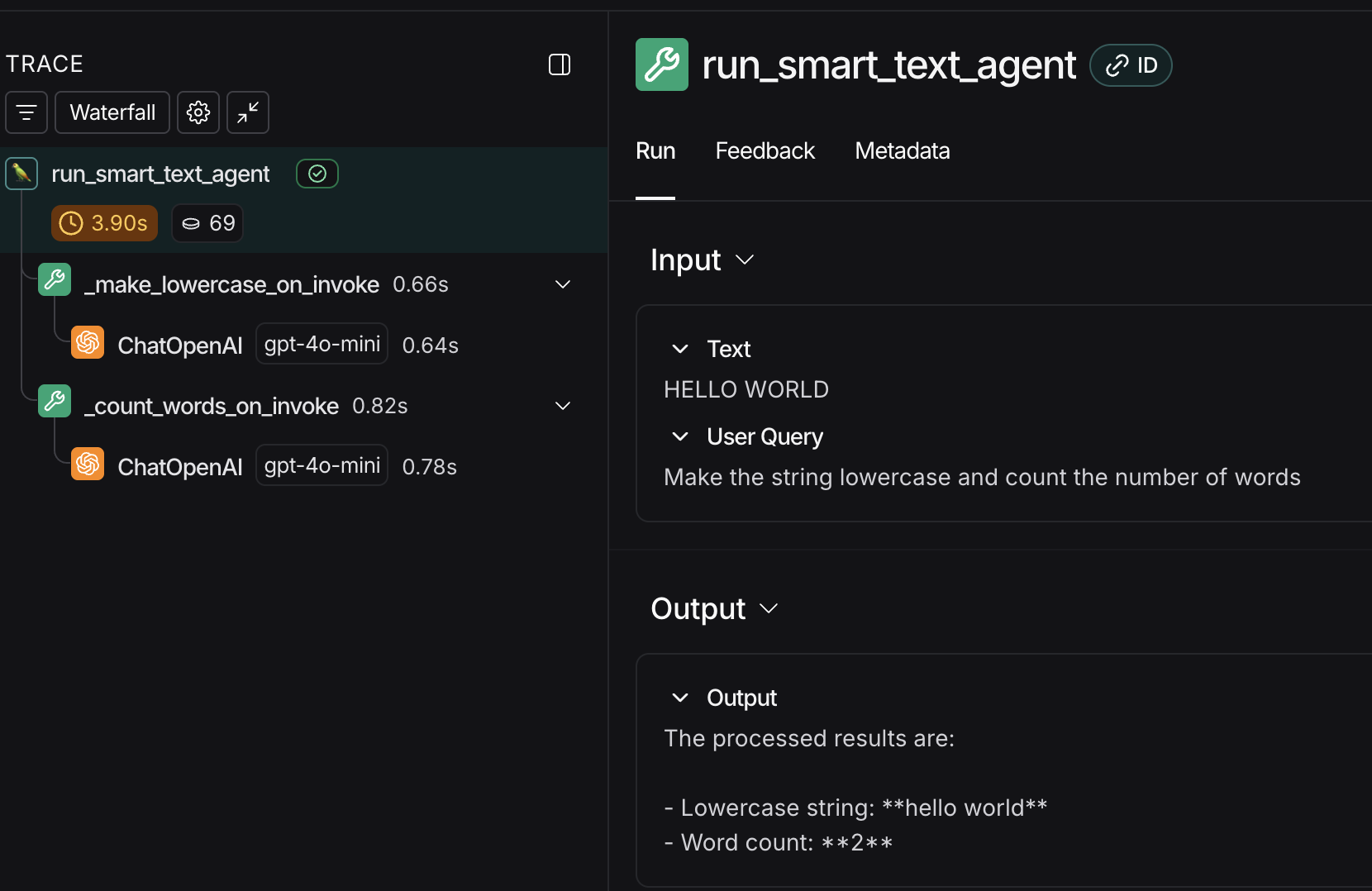
I have a simple tool responsible for making a string into lowercase using LLM as well as an triage Agent responsible for picking up the right tool for the task, in this case there is only one tool. I run the code with the OpenAIAgentsTracingProcessor defined.
This approach works well, the issue is that it created in the LangSmith UI a separate trace for the Agent vs Tool calls (LLM)
How can I have the agent and tool call under the same trace?

if __name__ == "__main__":
set_trace_processors([OpenAIAgentsTracingProcessor()])
asyncio.run(main())
@function_tool(name_override="make_lowercase_tool", description_override="Convert the given text to lowercase.")
async def make_lowercase_tool(
ctx: RunContextWrapper[Any],
args: TextInput
) -> str:
"""Tool that uses LLM to convert text to lowercase."""
client = wrap_openai(AsyncOpenAI())
response = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Convert the given text to lowercase. Return only the result."},
{"role": "user", "content": f"Convert to lowercase: {args.text}"}
],
max_tokens=100,
temperature=0
)
result = response.choices[0].message.content.strip()
usage_info = {
"model": response.model,
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens, # type: ignore
"total_tokens": response.usage.total_tokens,
"request_id": response.id,
"created": response.created,
"finish_reason": response.choices[0].finish_reason
}
print(f"make_lowercase_tool tokens | {usage_info.get("total_tokens")}")
return json.dumps({
"result": result,
"operation": "lowercase",
"original_text": args.text,
"usage_metadata": {"input_tokens": usage_info.get("prompt_tokens"),
"output_tokens": usage_info.get("completion_tokens"),
"total_tokens": usage_info.get("total_tokens")
}})
async def run_smart_text_agent(user_query: str, text: str) -> str:
"""Run the agent that uses the tool to process the input."""
instructions = (
"You are a text processing agent. You have 3 tools:\n"
"- make_lowercase_tool: converts text to lowercase\n"
"- make_capitalize_tool: capitalizes first letter of each word\n"
"- count_words_tool: counts words in text\n\n"
"IMPORTANT: When given a text and a request, immediately use the appropriate tool to process the text. "
"Do NOT explain your capabilities - just do the work and return the results."
)
agent = Agent(
name="Smart Text Processing Agent",
instructions=instructions,
tools=[make_lowercase_tool],
model="gpt-4o-mini-2024-07-18"
)
prompt = f"Process this text: '{text}'. Request: {user_query}. Use the appropriate tool immediately."
result = await Runner.run(agent, prompt)
return result.final_output