Over the past few days we noticed that the Assistants API stopped calling real functions over the API. When we “test” the assistants in the API, it is performing a “simulated function” and generating the results. It appears to be doing this over the API as well (just making up responses, effectively, but not callling tools at all).
Anyone else experiencing this?
It’s a strang edevelopment. after the model updates to make them less “lazy” there was a big improvement. And in the past day or so it basically completely stopped calling functions.
Update 1: I checked back our server logs. It was working fine until yesterday. And all of a sudden today, with no changes, it refuses to call any functions. It only hallucinates the response and provides it. And it often says there has been a “slight hiccup” in running the function, except when we see our logs it is not actually calling a tool/function at all something got broken bad.
Update 2: We have not tested with GPT4; GPT-3.5-Turbo (the new ones); and both the November and January GPT4-Turbo models. So ALL models have stopped calling functions/tools even when explicitly instructed to do so. And in the playground are using code intepreter with markdown code to “hallucinate” a function call.
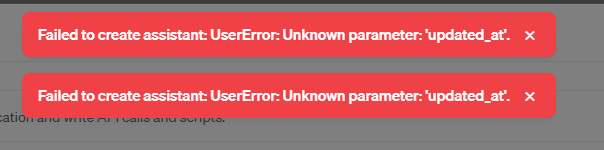
Update 3: When trying to duplicate Assistants to test, you now get an error "unknown parameter: ‘updated_at’.
Something is surely broken
Update 4: We had to recreate our “assistant” and disbale code interpreter. For some reason the code interpreter was launching during dialogie, and once code-interpreter was launched it seems that it would not use actual functions, instead it would only “mock” results. This was a substantial change in operation affecting multiple models. It is disappointing that it was not communicated, but I am sharing it here in case anyone else has this issue.
Update: I checked back our server logs. It was working fine until yesterday. And all of a sudden today, with no changes, it refuses to call any functions. It only hallucinates the response and provides it. And it often says there has been a “slight hiccup” in running the function, except when we see our logs it is not actually calling a tool/function at all something got broken bad.
It seems the AI has emitted to code interpreter. Calling tools, or at least the start tokens of tool calls from which the AI cannot escape, when it is not needed or wanted, is what I describe, and in this case, it decided to send to python.
Is anyone else having the issue with function calls suddenly not running? Or Mocked results instead of tool calls?
The model is now openly responding by saying thay in a live environment they would query the API, but that it cannot do that in its current configuration, and so it is “simulating a basic response”.
Another thing: functions should not be asked for by the user. They should be fully described and instead fulfill a user need.
Use system prompts about them, or talk about them, and you are more likely to get an AI that writes code instead of using functions correctly when “user typed the word functions = first likely token is python”.