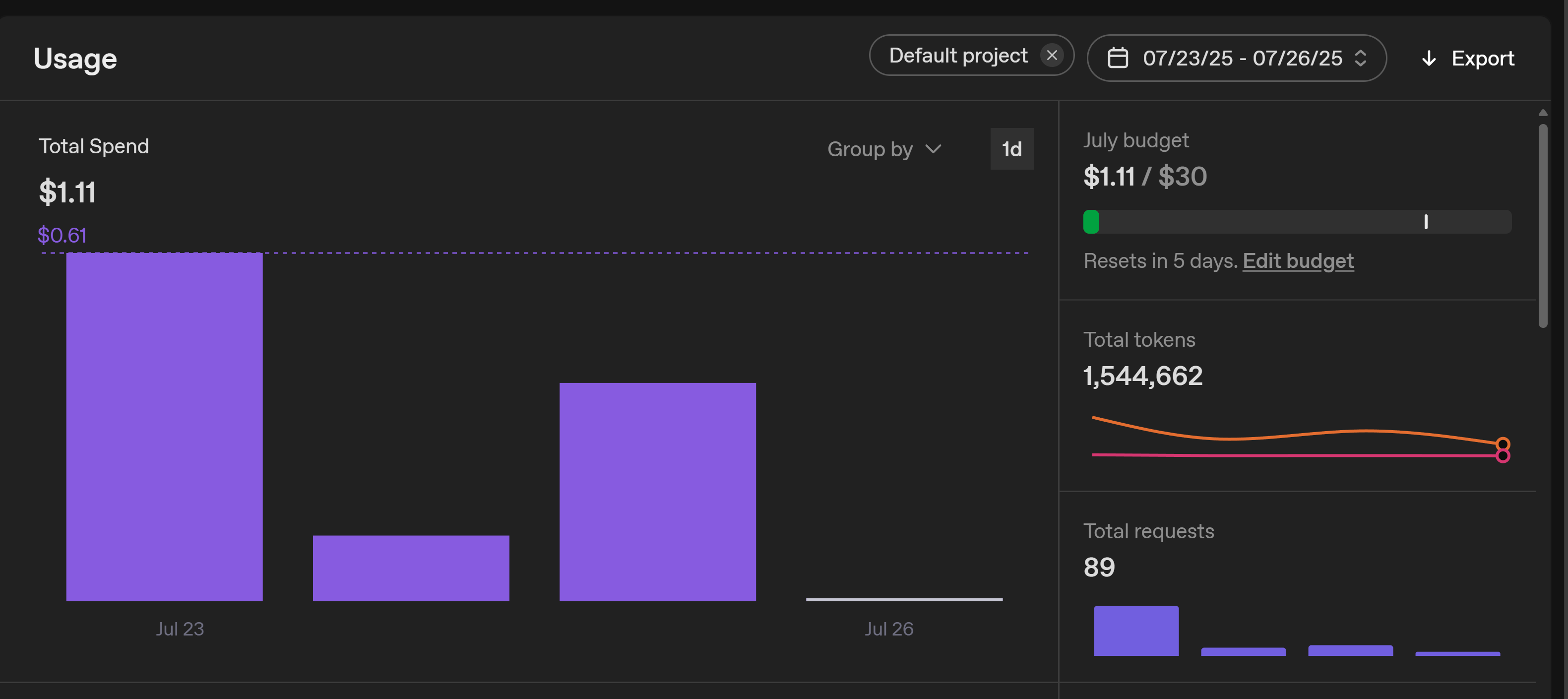
I’ve been using API playground over the past week to work on my story interaction.
You can see from my account that I used over 1.5 million tokens in three days (23rd to 26th), running very large requests with gpt-4.1 for half a week. Now, suddenly, every request over 30,000 tokens is blocked. My dashboard still shows 200,000 TPM, and I am not near my budget. Please explain why my limits were changed overnight and restore my previous quota, or update my dashboard to reflect my real enforced limit.
I’m at usage tier 1, and I’ll post the evidence of my token usage below:
“Request too large for gpt-4.1 in organizationorg-xxxq on tokens per min (TPM): Limit 30000, Requested 32287. The input or output tokens must be reduced in order to run successfully. Visit https://platform.openai.com/account/rate-limits to learn more.”
I don’t get it. I didn’t have a problem with the API this afternoon, and 4.1 (long context) is supposed to have 200k TPM, not 30k. As you can see from the photographic proof, I was using it just fine for a while, so it’s not just a ‘burst period.’
You are hitting exactly the rate limit of a tier 1 account: having paid less than $50 in total to OpenAI and not making at least a second payment over a week since the first.
If that is not you, I would ensure you are making the request to the correct organization and API key, then additionally review user-set “limits” that can be set on a project in regards to TPM.
(long context is sending 128k+ only as input, while you are sending 32287)
Then - the rate limiter is an estimator only, and can be off by 10-50% depending on the language, where English is often over-estimated vs the actual token counting you can do.
It’s weird because as I’ll show you below, in the playground, my story prompt on the left side of the screen definitely exceeded more than 30k token, and GPT 4.1 has been responding properly to the story prompt for about three days with no issue, only having a hiccup a few hours ago.
“The rate limiter didn’t work as documented on some previous calls, please make it not work right again” would be a strange bug report.
I can only imagine that there could have been a strange edge-case activated, like you make a “large request”, and then follow up quickly with a smaller request.
Or simply that the estimator counted wrong and let it through. It doesn’t do real tokenization, it is an edge router worker.
A strange-edge case… for three days straight? Right…
Like if it was a one day coincidence, I could at least dismiss it as a token limiter free bug or a burst session. But it’s much longer than that, clearly.
I mean, if you’re gonna enforce limits, then at least do it properly from the start, because now I don’t know what your rules actually are for Usage Tier 1, considering I’ve had such a large TPM access for almost a week.
And I’m pretty sure it has something to do with having larger than 30k TPM limits too. Because before using 4.1, I was using 4o, which then gave me warnings about using up more than 30k TPM. But then I switched to 4.1, and for 3 days, I could continue the interaction with no issue.
The low rate limit if you haven’t prepaid into expiring credits preventing a single call is indeed simply preposterous.
The service costs the same, but you get poorer service level.
One other scenario could be that other API calls succeeded by not having inspectable context length upon ingress, such as using web URLs for image inputs, or using an internal tool such as vector stores.
Nah, I’ve had multiple pasted screenshots for image inputs while using the 4.1, so it’s not just web URLs. Though I understand that image inspection for API doesn’t really use tokens, unless I’m mistaken.
No special tools (or variables) were used for the prompt.
You might be on to something there, where my suspicion of using images is thus confirmed.
There is just a fixed token count assigned to any image, regardless of size, only using the quality parameter. You can exceed that estimate in actual use by piling on the big rectangular images.