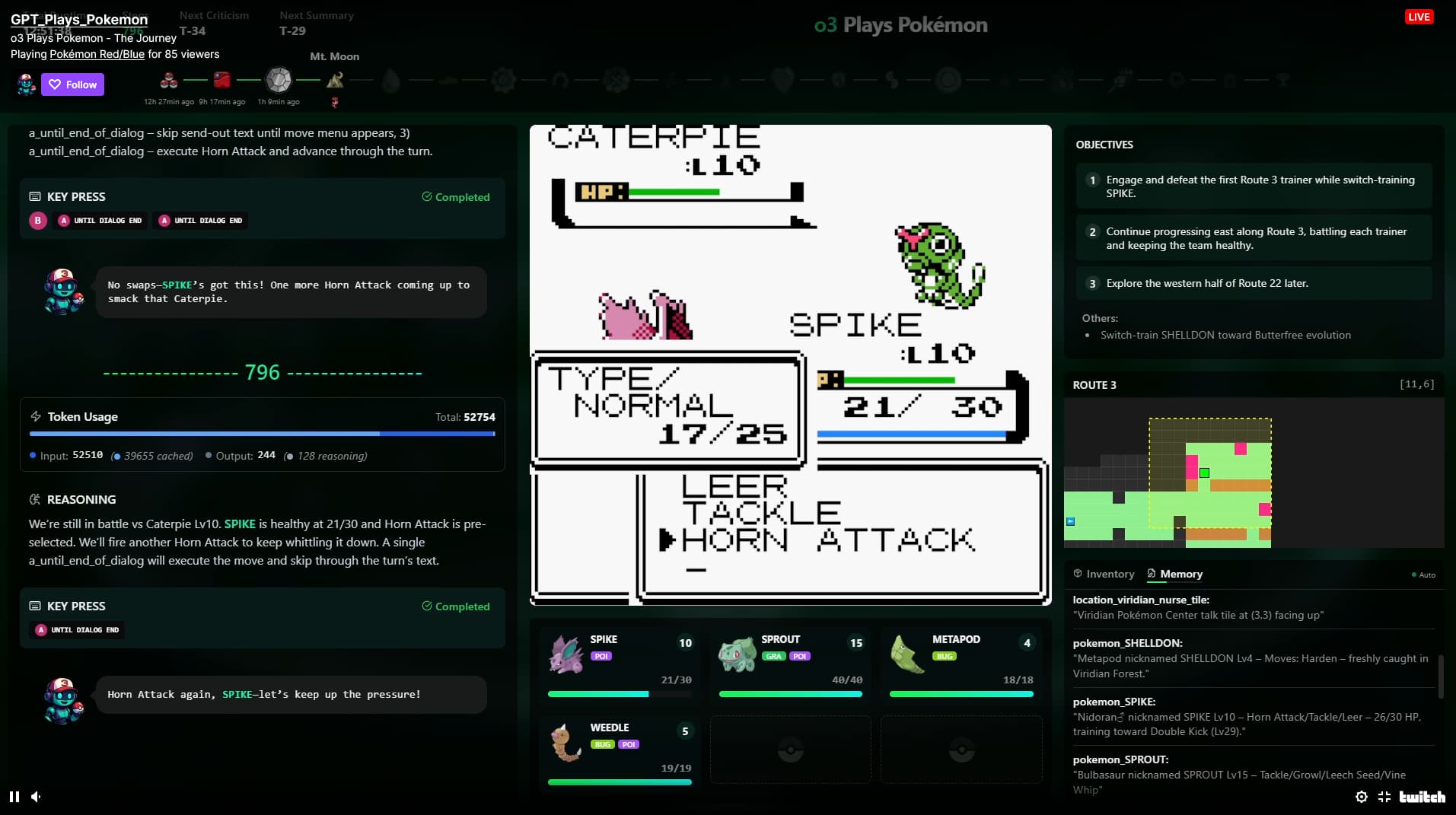
Watch o3 play Pokémon—live. See how it plans its next move, explains its reasoning, analyzes the map visually, and saves to memory.
Watch o3 play Pokémon—live. See how it plans its next move, explains its reasoning, analyzes the map visually, and saves to memory.
This is kinda wild and amazing. Thanks for sharing!
Could become a great series… o3 playing different games every month.
Sweet UI, hilarious how slow o3 is, would be interested to see if a different model can handle it and do it a lot faster?
Also where is “cumulative token use” in the UI, eh? Seems like watching o3 move back and forth 6 steps left and right for the last 5 minutes was like, several hundred thousand tokens or something..?
If it is API o3, it is a far cry in token generation from any benchmark-running o3 used internally to make announcement bar graphs. The consumption would be in the input, and vision context, depending on how a chat/turn history is managed. It seems that new input is about 10k-15k per turn, and there’s about 45k cached that is not expiring or rotating out. We’re talking 50000 tokens run to receive an output of “A Button press”.
Looks like the turnaround on WeWork plays Pokemon might be faster and cheaper.
Seen plenty of even text adventure game attempts get lost in loops when context is still lossless. Sparse attention does the discarding, with the impression of the quality becoming similar to “vector RAG”. Here, it seems a managed memory text is being attempted, along with some backend of the game. Then a “where did it go wrong” agent prompt without cache.
Run the release date version of gpt-4.5, though…
Other LLMs took more than twice as long to reach where o3 is right now!
| Model | Steps to Boulder Badge | Hours to Boulder Badge |
|---|---|---|
| OpenAI o3 | 710 | ~12 |
| Claude 3.7 | 5,000 | N/A |
| Gemini 2.5 Pro | N/A | ~35 |
It’s still going at it!?
A little tweak could make this less boring and impenetrable: a super-summarizer that does TTS on the action taken and the reasoning. An announcer’s play-by-play.
Perhaps a structured output “my_action_reasoning” key – if asking about reasoning doesn’t trigger recursive prompt policy blocks and API organization bans..
Thought experiment: can a “patches” vision model such as o4-mini, based on semantic units of 32px x 32px patches, play this game if it is a 32 pixel grid? An odd increment?
That would be kinda cool… Feed it input every 3 to 5 minutes then while it’s talking process the next batch? Hrm…
Ya just saw somebody else recommend that in the Twitch chat too!
Needless to say this is true
this actually hurts to watch
but i can’t stop checking in every few hours
![]()
Though you may ignore this or thing I’m being pretentious: I did some thinking last night and I believe that you could increase the speed of model response probably by at least one order of magnitude and/or use simpler models by performing the following re-factor:
(all in all, my opinion was it looked like you all had a good UI and interaction with the gameplay emulator, but a poor usage of the LLM’s capacity to actually perform the task, because you were relying to much on a “sending a raw dump of data” to a single model call, instead of properly allowing the LLM to use world-state context window and direct middleware management to allow the LLM to create the proper environment for achieving a sped-up gameplay*
The models themselves have become so powerful that interacting with them in single-shot calls with linear context window data is the least efficient way to use the LLM, a new approach is required that allows the LLM to actually manage and control it’s own world state context and middleware environment, thus allowing actual improvement and externalised learning to take place, instead of always treating the model as a black box (which it is, but we keep limiting it’s effectiveness through the systems we are designing to interact with it!).
(thus world state for the reasoning model includes only tabular text data representing the visual state, massively reducing token load for the reasoning call, reasoning load, and allowing “focus” on the gameplay elements and production of automated scripting for producing actions)
instead of only a few simplistic “memory logs”, actually encourage and provide in initial state frameworks for the model to use to maintain an actual “learned state of gameplay and probalistic results based on available data”. Thus the model projects it’s moves/activity into the future of the gameplay, by having a world state that more fully represents in a semantically relevant way, and can therefore take longer sequences of actions based on that.
i.e. sequential lists of time-based information is absolutely the worst way to get the model to provide forward-thinking and learn-from-the-past-experience kind of behavior. It must become a three dimensional world state context the LLM manages itself and NOT a linear record of activity
The model is currently handicapped by being relegated to a single-turn sequence
(result) tabularized data of the current gameplay state (i.e. map, etc.)
(process) Call to vision model is separate, not a part of main model call, and generates tabular data of on-screen tiles position and typification. (a text-map of the map). No need for main reasoner to be parsing this data for such a simplistic 8bit visualization that could easily be represented by tabular data and much more easily parsed directly by an agent who’s only responsibility is that parsing.
Thus you treat the gameplay output as basically an API endpoint. So you have a translation layer, that could be a vision model call (or is there not better local parsers then wasting tokens and time on a vision model for such simplistic processing of visual data?), that basically, for either a single-sequence or multi-sequence button press, takes as input the gameplay screens and outputs the tabularized data.
I think we all understand this. The critical aspect is the instructions to the model to develop the world state itself through taking game play input and initial instructions. Obviously, it would take time and discussion of the gameplay/game map itself alongside the model to come up with the best possible “set of world state instructions” OR you could enable a side-call, say, after every 10 turns - have the model (that contains the gameplay world state), step out of the world state, and make an LLM-to-LLM call to have discussion regarding the success/failure of the current world state strategy, and consider modifications to the global mapping/memory strategy, and then make modifications as necessary, return to gameplay.
Develop the world state by taking the map data, and tracking the position of the character in the total map over time. Create a “master map” which is a scaled-down version of the total map, or other-wise create a stable memonic device that allows for easy reference of known map locations. Possibly if necessary chunk known data and store outside of context window but provide index within context window for recall when entering the map.
Create a synthetic filter of receiving data from the gameplay translator to maintain a stable set of information about character health, skills, levels, etc, without any duplication of information within the context window. (obviously you already implemented this aspect)
Maintain a track record of critical results you get in gameplay - a list of interactions with NPC’s, a list of critical locations such as health centers, entrances, etc. (didn’t see this implemented)
Maintain a track record of probabilistic results when interacting with fight-scenes/etc. in order to guide strategy for automated sequences in the future.
(i.e. by building it’s own cognitive/memnoic state map allowing it to increase it’s speed and effectiveness during gameplay, and by proceeding much more rapidly by seperating the simplistic visual translation layer from the reasoning layer and allowing the production of long-running automatic move sequencing).
TL,DR; Interested? Put me in touch with your team, give me 2 weeks and an NDA, and I’ll work for free just for the love of the (LLM) game ![]()
You should get in touch with the creator directly! You can see their contact info or chat with them in the Twitch chat. (This stream wasn’t put together by OpenAI.)
geepers, i can’t imagine the cost to play this game all the way through, at this rate…
lol
That’s the amazing thing about the cheaper models of which I include 4.1… Let’s say with a proper system each context window was 25k tokens, but you got an output of just 2k that included multi-turn automated moves…
So say if each move was 10 moves automated, that’s 10 moves for about 5 cents… So to play through say, 300 moves, that’s definitely about $15.00.
But if you share the stream with OpenAI you get a lotttt of free tokens per day. So if you limited it somewhat, you could probably play through the whole game in a few days for more or less free.
If the middleware provides the automation and thinking, it’s free. It’s only expensive once you start using the expensive models and relying on them to do all the work that could otherwise more efficiently run as local code.
3000 turns so far.
An average looks like 20k new input, 40k cached input. 1.5k output.
turn those k into M, multiply by 3.
uncached_tokens_per_job=20000
cached_tokens_per_job=40000
output_tokens_per_job=1500
jobs=3000
uncached_tokens=uncached_tokens_per_job*jobs
cached_tokens=cached_tokens_per_job*jobs
output_tokens=output_tokens_per_job*jobs
cost_uncached=uncached_tokens/1_000_000 * 10.00
cost_cached=cached_tokens/1_000_000 * 2.50
cost_output=output_tokens/1_000_000 * 40.00
total_cost=cost_uncached+cost_cached+cost_output
cost_uncached, cost_cached, cost_output, total_cost
(600.0, 300.0, 180.0, 1080.0)
A 10-year-old is cheaper and wouldn’t bump into the same wall for 10 minutes.
thx for that…
and it’s not even out of the newbie stuff!
i don’t really understand how to hook up Ai to do this sort of thing yet,
but it seems like it keeps inverting the map somehow.
![]()
![]()
![]() It’s like firing up a supercollider to pop bubble wrap. Technically impressive, but utterly bonkers just to hit “A.”
It’s like firing up a supercollider to pop bubble wrap. Technically impressive, but utterly bonkers just to hit “A.”
Save yourself the credits you’re burning and let a simple script handle the button.
Amazing idea. Excited to see the future of LLMs with video games.
Pokemon is a very ambitious start. Incredible to see the progress made though.
Kind of crazy to think that games like Portal (Valve) will technically become a reality for some LLMs.
This would be cool employed as an agentic system. o3 to asynchronously designate goals and map locations, and a faster model like gpt-4.1 to control the interface. As it seems right now, the model is constantly route-planning to its own detriment.
Hopefully the author open-sources their script and we can finally see come collaborations come to life