We’ve been having mixed results when it comes to speed of the API requests, so I started logging steps in each action our scripts take. E.g., there are logs in place for getting the vectorized content from our database, getting the answer from our embedded context etc.
Here’s a graph from our past ~1000 requests. There’s a bit of speed to be gained on our end (working on optimizing that), but as far as I know, there’s not much we can do to speed up what lies elsewhere, in this case, at OpenAI.
Are you seeing similar speeds when using the embedding method?
(if yo uneed more detailed views, let me know I’ll edit the graph data)
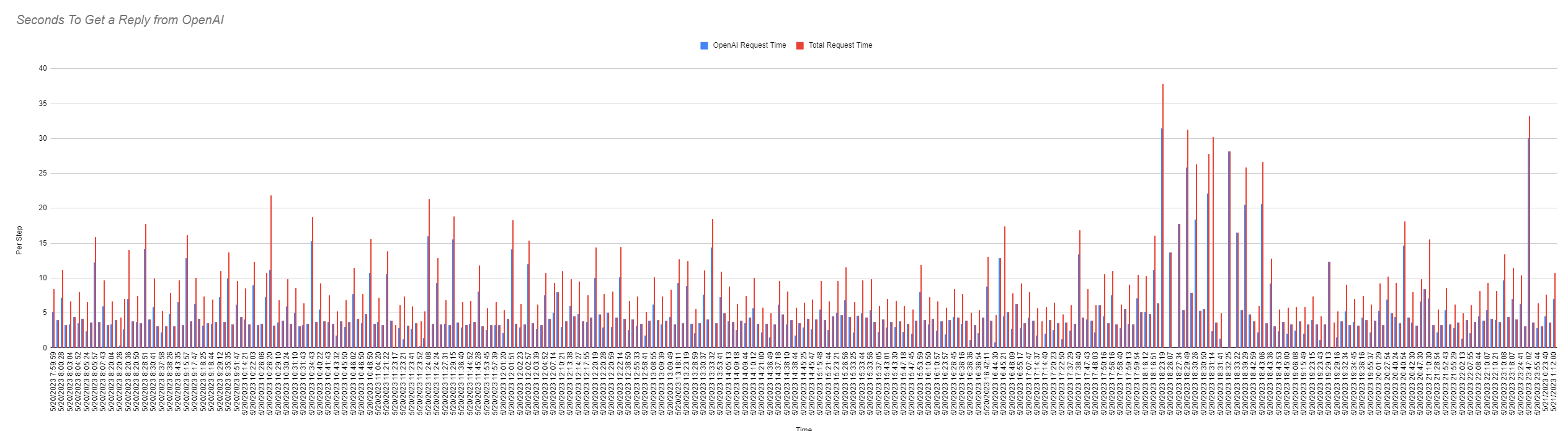
This is using the API, GPT-4 for chat (not completions).