I’m encountering an issue with asynchronous OpenAI API calls where certain requests take significantly longer than others, even though the input size and processing logic are similar. There doesn’t seem to be any consistent pattern behind which requests take longer.
I’ve implemented concurrency control using an asyncio semaphore (limit = 5) to manage simultaneous calls, but the latency issue still persists
I haven’t found any correlation between the token count of the queries and the delay. I have also changed the model to 4o mini, and the same error is happening there too.
Code SImplified:
async def analyzeFilesAndWeb(self, analysis_plan):
self.logger.info(f"{self.folderId}: analyzeFilesAndWeb started with semaphore limit")
semaphore = asyncio.Semaphore(4)
delay_between_calls = 5
start_time = time.time()
async def sem_analyze(file):
async with semaphore:
await asyncio.sleep(delay_between_calls)
content = self.buildFileContent(file)
return await self.safeAPICall(self.analyzeFile, analysis_plan["key_analysis_areas"], content)
async def sem_websearch(query):
async with semaphore:
await asyncio.sleep(delay_between_calls)
return await self.safeAPICall(self.webSearch, query)
file_tasks = [sem_analyze(file) for file in self.folder_dict["files"]]
web_tasks = [sem_websearch(q) for q in analysis_plan["internet_search_queries"]]
all_tasks = file_tasks + web_tasks
results = await asyncio.gather(*all_tasks)
file_answers = results[:len(file_tasks)]
web_answers = results[len(file_tasks):]
self.logger.info(f"{self.folderId}: analyzeFilesAndWeb finished in {time.time() - start_time:.2f}s")
return file_answers, web_answers
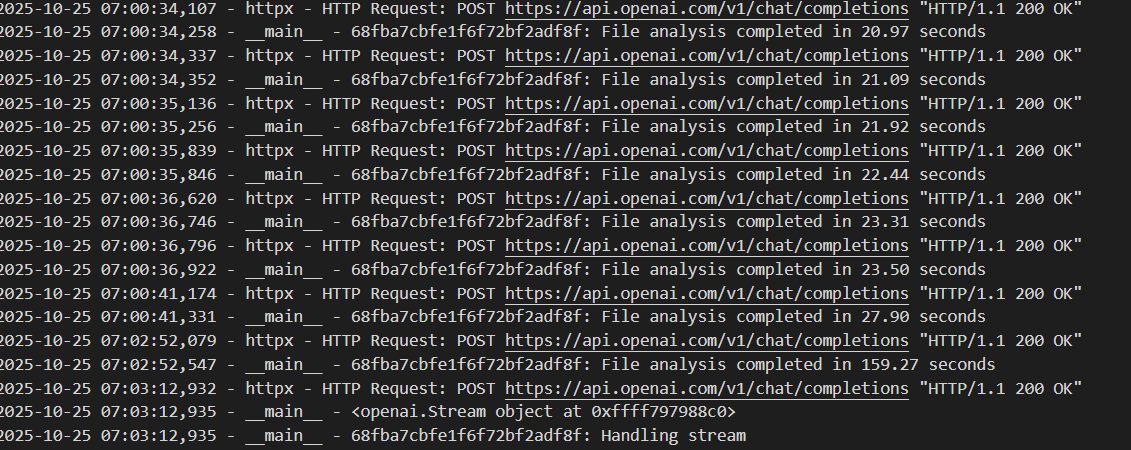
example logs
2025-10-25 16:23:33,200 - httpx - HTTP Request: POST “HTTP/1.1 200 OK”
2025-10-25 16:23:33,207 - main - 68fcb30d4e32ac63d800a1f5: File analysis completed in 13.47 seconds
2025-10-25 16:24:52,399 - httpx - HTTP Request: POST “HTTP/1.1 200 OK”
2025-10-25 16:24:52,401 - main - 68fcb30d4e32ac63d800a1f5: File analysis completed in 345.08 seconds
2025-10-25 16:24:52,401 - main - 68fcb30d4e32ac63d800a1f5: analyzeFilesAndWeb finished in 783.62s
Troubleshooting So Far:
Added concurrency limits using asyncio.Semaphore(5)
Added delays between requests to avoid rate limit spikes
Verified that all requests return HTTP 200 OK responses
Has anyone experienced similar inconsistent response times with async OpenAI calls?
Could this be due to backend queueing, load balancing, or priority tier inconsistencies?
I’d appreciate any insights or optimization suggestions on:
Improving latency consistency for async OpenAI calls.
Recommended retry/backoff strategies for variable completion times.
Whether using service_tier="priority" helps with stabilization.
The code seems to be just one method of a class, not knowing what’s outside or called, so:
Code reconstructed and AI-analyzed to see if it is useful to us
Below is a clean read of what that snippet is doing, what it depends on, and where it likely lives in the codebase—followed by a properly indented, fully contained version of the same logic.
Discovery
What it is:
A single asyncinstance method (likely on some worker/analysis class) that concurrently:
analyzes file contents via an API, and
performs web searches for queries in an analysis plan,
and returns two lists of results (file_answers, web_answers).
It defines two nested async helper functions (closures) that share a single semaphore:
sem_analyze(file): throttles and calls analyzeFile(...) via safeAPICall.
sem_websearch(query): throttles and calls webSearch(...) via safeAPICall.
Concurrency/flow:
A shared asyncio.Semaphore(4) gates the total concurrency across both file-analysis and web-search tasks.
Each task awaits a fixed sleep (delay_between_calls = 5) inside the semaphore context before calling the API. This means each slot is occupied while sleeping, effectively reducing useful parallelism. Practically: batches of ≤4 will sleep for 5 seconds each before the API call, then release the slot after the call completes.
All tasks are scheduled together via asyncio.gather(*all_tasks). gather preserves the order of the input coroutines, so slicing the results back into file_answers and web_answers is correct.
Dependencies / unseen methods & fields (likely members of the same class):
self.logger: used to log start/finish and elapsed time.
self.folderId: included in log messages.
self.folder_dict["files"]: iterable of files to analyze.
self.buildFileContent(file): transforms a file reference into content for the analysis call.
self.safeAPICall(callable, *args): an async wrapper that probably handles retries/backoff/rate-limits, returning the result of calling callable(*args).
self.analyzeFile(key_analysis_areas, content): async method that likely issues the actual LLM (Chat Completions) request for file analysis.
self.webSearch(query): async method that likely issues a web request or another LLM call for search results.
What we can infer (and not infer) about the API calling approach:
All outbound calls are funneled through safeAPICall, which is where rate-limiting, retries, and exception policies would exist. Without that code, we cannot conclusively assess their scheduling/retry policy or diagnose latency variance beyond the visible concurrency throttle.
The code intentionally adds a fixed 5-second delay before every call (inside the semaphore), which dominates latency and can mask or exacerbate perceived variance.
There’s a textual claim of “semaphore (limit = 5)”; the code shows asyncio.Semaphore(4). That mismatch is likely an oversight in the post, not logic, but worth noting.
On “quality scheduling of workers”:
This is a simple throttle pattern rather than a queue/worker pool. It works, but:
Sleeping while holding the semaphore reduces effective concurrency and throughput.
There’s no per-call timing/metrics at the task level, only a total elapsed-time log.
asyncio.gather will schedule all coroutines immediately; the semaphore does the real gating.
Reconstructed code (proper indentation & a plausible container)
import asyncio
import time
from typing import Any
class Analyzer:
logger: Any
folderId: str
folder_dict: dict[str, Any]
async def analyzeFilesAndWeb(self, analysis_plan: dict[str, Any]) -> tuple[list[Any], list[Any]]:
self.logger.info(f"{self.folderId}: analyzeFilesAndWeb started with semaphore limit")
semaphore = asyncio.Semaphore(4)
delay_between_calls = 5
start_time = time.time()
async def sem_analyze(file: Any) -> Any:
async with semaphore:
await asyncio.sleep(delay_between_calls)
content = self.buildFileContent(file)
return await self.safeAPICall(self.analyzeFile, analysis_plan["key_analysis_areas"], content)
async def sem_websearch(query: str) -> Any:
async with semaphore:
await asyncio.sleep(delay_between_calls)
return await self.safeAPICall(self.webSearch, query)
file_tasks = [sem_analyze(file) for file in self.folder_dict["files"]]
web_tasks = [sem_websearch(q) for q in analysis_plan["internet_search_queries"]]
all_tasks = file_tasks + web_tasks
results = await asyncio.gather(*all_tasks)
file_answers = results[:len(file_tasks)]
web_answers = results[len(file_tasks):]
self.logger.info(f"{self.folderId}: analyzeFilesAndWeb finished in {time.time() - start_time:.2f}s")
return file_answers, web_answers
Wrap-up:
This is one class method that spawns concurrent coroutine calls for file analysis and web search, gated by a shared semaphore and a fixed pre-call delay, returning results split by source. The actual API-calling strategy is encapsulated in safeAPICall, which isn’t shown, so we can’t draw deeper conclusions about retry/backoff or why latencies vary beyond the visible throttling pattern.
The technique for limiting API call rate isn’t really useful. The AI analysis inferred you are making all the calls sleep, and then sending the limit in parallel.
I benchmark Chat Completions by 600 calls per minute, easy, when it fits the need, but by scheduled dispatch to not burst all the calls at once into a worker pool. That is also just so performance evaluation doesn’t depend on if it was an initial network contention or sending latency. OpenAI has the cloud capacity to handle enterprises, they can deal with your five calls.
The only limit is your organization tier rate limit, where you try to consume your per-minute rate limit over that full minute’s allocation instead of blasting a minute’s worth in a second to avoid a premature cutoff and to avoid disrupting other organization users.
Technique:
Do you have enough common input to be cached - over 1200 tokens the same at the start of input?
If not, I would give each call a random or sequential “prompt_cache_key”, to indicate that loading to the same inference server is not desired or needed.
Then: this just seems to be a common effect when making API calls: every now and then you get, besides timeouts, a server that is generating tokens at extremely slow rates, like you got routed to “Backwater Joe’s Server Corral”.
If you get the instantiation of batch of calls processing much faster, you’ll have faster final results.
If you use streaming, you can see when an API call is returning nothing to you for an extended time, or measure its output rate vs minimum expectations (adapting to any expected reasoning model delay). That can let you start a concurrent retry, and maybe you then close() the connection on that 159 second call when the retry you kicked off at 15 seconds of nothing is done faster.
I’ll assume you’re doing other stuff pretty clever with your “web” and “files” that are not offered tool services on Chat Completions, and thus you cannot blame OpenAI’s lazy tools on a call’s slow response.
When pasting code to the forum, you should enclose it in a markdown code fence container so that it is not damaged.
That can look like you typing into the input box:
```python
print(f"The error was {error_type}")
```
Where you have contained your multi-line code snippet in three backtick characters, optionally with the type of code for better code formatting, which would appear:
print(f"The error was {error_type}")
You can also select the entirety of text, and then press the </> button in the formatting bar.
Also: indicate the source of the code: is it something that you ran and verified, or just a metacode theory made by AI? It seems the latter, as this does not match any understanding of the chat completions endpoint task (which we also can’t really know from the first post).
Here instead, is a foundation for making some relentless calls, without imagination like “jitter factor”, from working code:
import random, string, time, asyncio
from openai import AsyncOpenAI
# test parameters
TRIALS = 5
MAX_TOKENS = 512
MINUTE_RATE = 60
MODELS = ['gpt-4o-2024-08-06', 'gpt-4o-2024-05-13', 'gpt-4o-2024-11-20']
async def run_single_trial():...
async def main() -> None:
"""Run all trials with rate-limited scheduling and print a summary report."""
client = AsyncOpenAI()
tokenizer = Tokenizer()
tasks: list[asyncio.Task[dict]] = []
model_for_task: list[str] = []
# delay in seconds between starting each API call
delay_between_calls = 60.0 / MINUTE_RATE
# Schedule each trial at fixed intervals
for model in MODELS:
for _ in range(TRIALS):
tasks.append(asyncio.create_task(
run_single_trial(model, tokenizer, client)
))
model_for_task.append(model)
await asyncio.sleep(delay_between_calls)
all_outcomes = await asyncio.gather(*tasks)
results: dict[str, list[dict]] = {m: [] for m in MODELS}
responses: dict[str, list[str]] = {m: [] for m in MODELS}
for outcome, model in zip(all_outcomes, model_for_task):
results[model].append(outcome)
responses[model].append(outcome["text"])
The calling method isn’t really the concern here: it’s what to do when you get slow responses anyway.