Hello comunity I want to know if is a way of finetunning openai model for understand me the examples is this:
I ask this
Could you please me the number of orders in each country?
And open ai internally know which table is.
Hello comunity I want to know if is a way of finetunning openai model for understand me the examples is this:
I ask this
Could you please me the number of orders in each country?
And open ai internally know which table is.
Yes, and you don’t need to fine-tune a model for this. A decent solutions architect and a good programmer can show you a couple of different options according to your business problem. I suggest a serverless application where you store the data in the format of embeddings and feed an open AI model, answering accordingly. When your data (table) needs to be updated, you can convert the updated data into embeddings and store it in your database. I have a couple of applications using this structure, and it works really well.
Hell @allanfelipesilva nice to meet you could you please share the code or maybe an example of that kind of development?
Hi,
You can check out: https://platform.openai.com/docs/guides/fine-tuning for the documentation.
and How to fine-tune chat models | OpenAI Cookbook for an example.
Hope this helps ![]()
This solution consists of two parts:
text-embedding-ada-002 model, and stores them—along with relevant metadata—in a generic database.chunks, where each chunk has at least a text property (and optionally a title).File: processEmbeddings.js
Location: Create this file in your VS Code project directory.
javascript
Copiar
/********************************************************************
* processEmbeddings.js
*
* This script processes structured JSON files to generate embeddings
* for text chunks using OpenAI's text-embedding-ada-002 model.
* It then stores each embedding along with associated metadata in a generic database.
*
* This example is generic and does not expose any specific database details.
* Replace the database functions with your provider's implementation (e.g., AWS DynamoDB, GCP Firestore, Azure Cosmos DB).
********************************************************************/
// ----------------------
// 1. IMPORTS AND CONFIGURATIONS
// ----------------------
const fs = require('fs'); // File system module for reading files.
const path = require('path'); // Path module for handling file paths.
const axios = require('axios'); // Axios for making HTTP requests.
// OpenAI API key placeholder (store securely in production)
const OPENAI_API_KEY = 'YOUR_OPENAI_API_KEY'; // <-- Replace with your actual API key
// ----------------------
// 2. GENERIC DATABASE INTERFACE (ABSTRACTED)
// ----------------------
/**
* Saves a document to the database.
*
* Note: Replace this function's implementation with your specific
* database logic (e.g., AWS DynamoDB, GCP Firestore, or Azure Cosmos DB).
*
* @param {Object} document - The document to save.
* @returns {Promise<void>}
*/
async function saveDocument(document) {
// Example implementation: Replace with your database logic.
console.log("Document saved to database:", document);
// e.g., await dbClient.save(document);
}
/**
* Returns the current timestamp in a format compatible with your database.
*
* @returns {any} - The current timestamp.
*/
function getCurrentTimestamp() {
// Modify this function if your database requires a different timestamp format.
return new Date();
}
// ----------------------
// 3. HELPER FUNCTIONS
// ----------------------
/**
* Generates an embedding for the given text using OpenAI's text-embedding-ada-002 model.
*
* @param {string} text - The input text for which an embedding is generated.
* @returns {Promise<number[]>} - A promise that resolves to the embedding vector.
*/
async function generateEmbedding(text) {
try {
const response = await axios.post(
'https://api.openai.com/v1/embeddings',
{
model: 'text-embedding-ada-002',
input: text,
},
{
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${OPENAI_API_KEY}`,
},
}
);
return response.data.data[0].embedding;
} catch (error) {
console.error('Error generating embedding:', error.response?.data || error.message);
throw error;
}
}
/**
* Processes a structured JSON file to generate embeddings for each text chunk,
* and stores the resulting data in a generic database.
*
* The JSON file should contain an array under the property "chunks".
* Each chunk should include at least a "text" property, and optionally a "title".
*
* @param {string} filePath - The path to the JSON file to process.
* @returns {Promise<void>}
*/
async function processEmbeddingsFromJSON(filePath) {
// Resolve the absolute path of the file.
const absolutePath = path.resolve(filePath);
// Read the content of the JSON file.
const fileContent = fs.readFileSync(absolutePath, 'utf-8');
let jsonData;
try {
// Parse the JSON content.
jsonData = JSON.parse(fileContent);
} catch (err) {
console.error('Error parsing JSON:', err);
throw err;
}
// Validate that the JSON has a "chunks" property that is an array.
if (!jsonData.chunks || !Array.isArray(jsonData.chunks)) {
throw new Error("Invalid JSON structure: the 'chunks' property must be an array.");
}
// Process each chunk in the JSON.
for (const chunk of jsonData.chunks) {
// Skip the chunk if it does not contain a "text" property.
if (!chunk.text) {
console.warn(`Chunk with id ${chunk.id || 'unknown'} does not have a 'text' property. Skipping this chunk.`);
continue;
}
// Optionally, concatenate the title with the text if available.
const textToEmbed = chunk.title ? `${chunk.title}\n${chunk.text}` : chunk.text;
// Generate the embedding for the text.
const embedding = await generateEmbedding(textToEmbed);
// Prepare the document to be saved in the database.
const document = {
title: chunk.title || null,
text: textToEmbed,
embedding: embedding,
createdAt: getCurrentTimestamp(),
};
// Save the document using the generic database interface.
await saveDocument(document);
console.log(`Processed and saved document for chunk with id: ${chunk.id || 'unknown'}`);
}
console.log(`Finished processing embeddings for file: ${filePath}`);
}
// ----------------------
// 4. MAIN EXECUTION BLOCK
// ----------------------
(async () => {
try {
// List of JSON files to process.
// Update these file paths with the actual locations of your JSON files.
const files = [
'path/to/your/firstFile.json', // <-- Replace with actual file path.
'path/to/your/secondFile.json', // <-- Replace with actual file path.
'path/to/your/thirdFile.json', // <-- Replace with actual file path.
'path/to/your/fourthFile.json' // <-- Replace with actual file path.
];
// Process each file in the list.
for (const filePath of files) {
console.log(`Processing file: ${filePath}...`);
await processEmbeddingsFromJSON(filePath);
}
// Exit the script successfully.
process.exit(0);
} catch (error) {
console.error('General error:', error);
// Exit the script with an error code.
process.exit(1);
}
})();
This example demonstrates how to implement a chat endpoint using a RAG (Retrieval-Augmented Generation) architecture. It processes a user’s prompt, generates its embedding, retrieves matching embeddings based on cosine similarity, and uses those as context to query a GPT model. The endpoint also logs the interaction. You can adapt this code to any cloud provider.
File: index.js
Location: Create this file in your VS Code project directory.
javascript
Copiar
/********************************************************************
* index.js (Generic Cloud Function Example)
*
* Chat Function Endpoint:
* - HTTP POST endpoint expecting JSON: { prompt: "..." }
* - Generates an embedding using OpenAI's text-embedding-ada-002 model.
* - Retrieves embedding documents from a generic database.
* - Selects the top matching documents based on cosine similarity.
* - Calls a GPT model using the selected context and the user's prompt.
* - Logs the interaction (question, answer, and context used) in the database.
* - Returns the response to the client in JSON format.
* - CORS enabled for any origin.
*
* This example is generic and can be adapted to AWS, GCP, or Azure.
********************************************************************/
// ----------------------
// 1. IMPORTS AND CONFIGURATIONS
// ----------------------
const express = require('express');
const axios = require('axios');
const cors = require('cors');
// Initialize Express app
const app = express();
// Middleware to parse JSON and handle CORS (allowing any origin)
app.use(express.json());
app.use(cors());
// OpenAI API key placeholder (store securely in production)
const OPENAI_API_KEY = 'YOUR_OPENAI_API_KEY'; // <-- Replace with your actual API key
// GPT model name placeholder
const OPENAI_GPT_MODEL = "gpt-4"; // <-- Replace with your desired GPT model name
// ----------------------
// 2. GENERIC DATABASE INTERFACE (ABSTRACTED)
// ----------------------
/**
* Retrieves all embedding documents from your data store.
*
* Note: Replace the implementation with your specific database logic
* (e.g., AWS DynamoDB, GCP Cloud SQL, Azure Cosmos DB).
*
* @returns {Promise<Array<Object>>} - Array of embedding documents.
*/
async function fetchAllEmbeddings() {
// Implement your database retrieval logic here.
// Example (pseudo-code): return await dbClient.query('SELECT * FROM Embeddings');
return []; // Placeholder: returns an empty array for demonstration purposes.
}
/**
* Logs the interaction (question, answer, context used) in your data store.
*
* Note: Replace the implementation with your specific database logging logic.
*
* @param {Object} interaction - The interaction data to be logged.
* @returns {Promise<void>}
*/
async function logInteraction(interaction) {
// Implement your database logging logic here.
// Example (pseudo-code): await dbClient.insert('QA_History', interaction);
}
// ----------------------
// 3. HELPER FUNCTIONS
// ----------------------
/**
* Generates an embedding for the given text using OpenAI's text-embedding-ada-002 model.
*
* @param {string} text - The input text for which an embedding is generated.
* @returns {Promise<number[]>} - The embedding vector.
*/
async function generateEmbedding(text) {
const url = "https://api.openai.com/v1/embeddings";
const headers = {
"Content-Type": "application/json",
Authorization: `Bearer ${OPENAI_API_KEY}`,
};
const body = {
model: "text-embedding-ada-002",
input: text,
};
const response = await axios.post(url, body, { headers });
return response.data.data[0].embedding;
}
/**
* Calculates the cosine similarity between two numerical vectors.
*
* @param {number[]} vecA - First vector.
* @param {number[]} vecB - Second vector.
* @returns {number} - Cosine similarity score.
*/
function cosineSimilarity(vecA, vecB) {
const dot = vecA.reduce((acc, val, i) => acc + val * vecB[i], 0);
const magA = Math.sqrt(vecA.reduce((acc, val) => acc + val * val, 0));
const magB = Math.sqrt(vecB.reduce((acc, val) => acc + val * val, 0));
return dot / (magA * magB);
}
/**
* Returns the top N documents with the highest cosine similarity compared to the prompt embedding.
*
* @param {Array<Object>} docs - Array of documents containing embeddings.
* @param {number[]} promptEmbedding - Embedding vector of the user's prompt.
* @param {number} n - Number of top matches to return.
* @returns {Array<Object>} - Top matching documents with similarity scores.
*/
function getTopMatches(docs, promptEmbedding, n = 3) {
const scored = docs.map(doc => {
const sim = cosineSimilarity(promptEmbedding, doc.embedding);
return { ...doc, similarity: sim };
});
scored.sort((a, b) => b.similarity - a.similarity);
return scored.slice(0, n);
}
/**
* Calls the GPT model using the provided context and the user's prompt.
*
* @param {string} contextText - The context constructed from matching documents.
* @param {string} userPrompt - The user's question or prompt.
* @returns {Promise<string>} - The GPT model's response.
*/
async function callGpt(contextText, userPrompt) {
const url = "https://api.openai.com/v1/chat/completions";
const headers = {
"Content-Type": "application/json",
Authorization: `Bearer ${OPENAI_API_KEY}`,
};
const body = {
model: OPENAI_GPT_MODEL,
messages: [
{
role: "system",
content: `You are an AI model. Use the context below to provide an objective answer.
Context:
${contextText}`,
},
{
role: "user",
content: userPrompt,
},
],
max_tokens: 2500,
temperature: 0.5,
};
const response = await axios.post(url, body, { headers });
const { choices } = response.data;
if (!choices || choices.length === 0) {
throw new Error("The GPT model did not return a response.");
}
return choices[0].message.content;
}
// ----------------------
// 4. CHAT ENDPOINT
// ----------------------
/**
* POST /chat endpoint:
* - Processes the user's prompt.
* - Retrieves context from the database based on cosine similarity.
* - Calls the GPT model with the constructed context.
* - Logs the interaction in the database.
* - Returns the GPT response to the client.
*/
app.post('/chat', async (req, res) => {
try {
const { prompt } = req.body;
if (!prompt) {
return res.status(400).json({ error: "The request payload must include a 'prompt' field." });
}
// 1) Generate the embedding for the user's prompt.
const promptEmbedding = await generateEmbedding(prompt);
// 2) Retrieve all embedding documents from the database.
const allDocs = await fetchAllEmbeddings();
let contextText = "(No context found)";
if (allDocs.length > 0) {
// 3) Select the top matching documents based on cosine similarity.
const topMatches = getTopMatches(allDocs, promptEmbedding, 30);
// 4) Construct context text from the top matches.
contextText = topMatches
.map((match, i) => `Segment ${i + 1} (similarity: ${match.similarity.toFixed(4)}):\n${match.text}`)
.join("\n\n");
}
// 5) Call the GPT model with the constructed context and user's prompt.
const gptResponse = await callGpt(contextText, prompt);
// 6) Log the interaction (question, answer, and context used) in the database.
await logInteraction({
question: prompt,
answer: gptResponse,
contextUsed: contextText,
createdAt: new Date().toISOString(),
});
// 7) Return the GPT response and context to the client.
return res.status(200).json({
answer: gptResponse,
contextUsed: contextText,
});
} catch (error) {
console.error("Error in /chat endpoint:", error);
return res.status(500).json({ error: error.message });
}
});
// ----------------------
// 5. SERVER SETUP
// ----------------------
// Start the server on a specified port (default is 3000)
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});
/********************************************************************
* Deployment Note:
* This generic code can be adapted to a serverless function on AWS Lambda (with API Gateway),
* Google Cloud Functions, or Azure Functions. Replace the Express server setup with the corresponding
* cloud provider's function handler as necessary.
********************************************************************/
While I cannot be more specific due to business constraints—after all, we developers are paid to solve these challenges—this solution provides a solid base for a RAG (Retrieval-Augmented Generation) system. You can adapt the code to use your preferred cloud provider (AWS, GCP, or Azure) and consider employing a specialized vector database like Pinecone for improved performance.
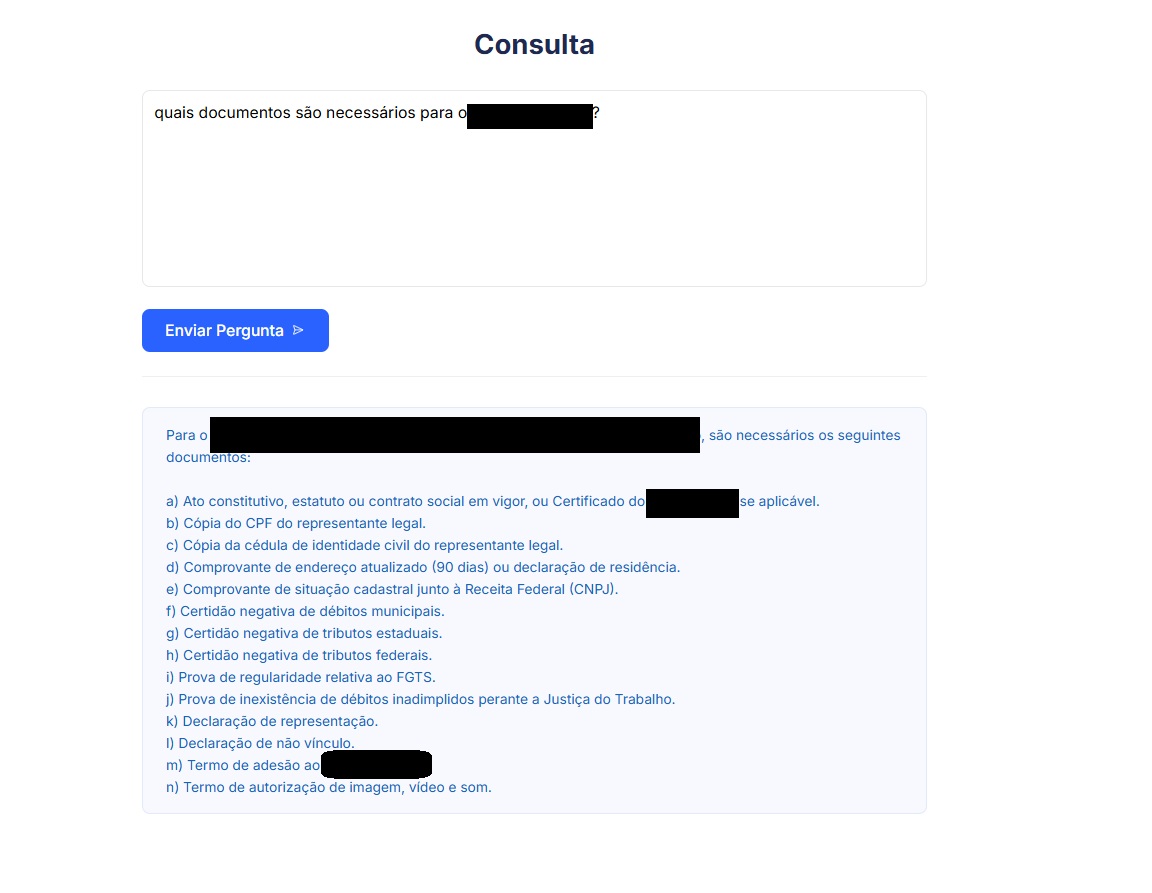
This image is an example of a response generated by a system that is fed with documents containing procedural bureaucratic information. Even without extensive fine-tuning, the system is capable of delivering solid and reliable answers based on a large volume of documents. Additionally, please note that the text is in Portuguese, as it is the primary language of the target audience.
Feel free to adjust and extend these examples to suit your specific business requirements.