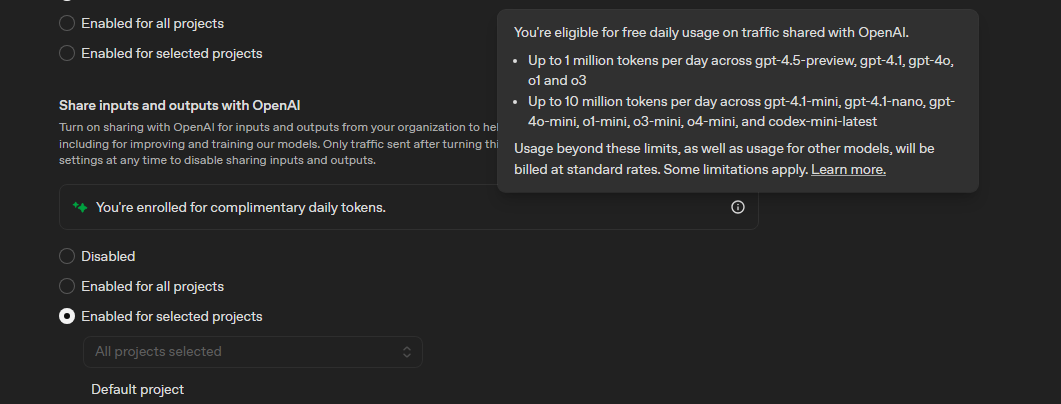
You can go to the legacy usage dashboard, go to activity, pick ALL the models of a particular free usage class (1M or 10M mini), and then get a general idea of your usage patterns, as the token counts there show up even though the usage is free:

However, besides the considerable lag, you cannot “track usage”, which is billed when you exceed the threshold in any 24 hour period.
Tracking? Start here:
print(json.dumps(json.loads(response_completed_event)["response"]["usage"], indent=2))
{
"input_tokens": 383,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 72,
"output_tokens_details": {
"reasoning_tokens": 0
},
"total_tokens": 455
}
The calls that got me something to show you also fulfilled an add-on to log usage from your API call response object (needing adaptation to the particular API call method, endpoint, or SDK plus way you’d store), and then a utility for the free usage considered right now.
Complementary usage logging
This is an AI brainstorm, expect form, not working code.
Recommended Implementation Strategy:
- Logging: Append each API call’s usage data as a JSON line to a log file (
free_calls_log.txt). JSON lines (.jsonl) format is ideal for easy parsing and appending.
- Utility: A standalone script to parse the log, filter entries within the last 24 hours, sum tokens, and optionally clean expired entries.
1. Logging Function (to append usage data):
import json
from pathlib import Path
from openai.types.chat.chat_completion import ChatCompletion
LOG_FILE = Path("free_calls_log.txt")
def log_usage(response: ChatCompletion) -> None:
"""Append usage data from OpenAI response to log file."""
entry = {
"created_at": response.created, # UNIX timestamp
"model": response.model,
"usage": {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
}
}
with LOG_FILE.open("a", encoding="utf-8") as f:
f.write(json.dumps(entry) + "\n")
2. Utility Script (to calculate usage and optionally clean expired entries):
import json
import time
from pathlib import Path
from typing import Set
LOG_FILE = Path("free_calls_log.txt")
WINDOW_SECONDS = 86400 # 24 hours
# Define model groups explicitly
HIGH_CAP_MODELS: Set[str] = {"gpt-4o", "gpt-4.5-preview", "o1"}
LOW_CAP_MODELS: Set[str] = {"gpt-4o-mini", "o1-mini", "o3-mini"}
def get_model_group(model_name: str) -> str | None:
"""Identify model group based on model name."""
for prefix in HIGH_CAP_MODELS:
if model_name.startswith(prefix):
return "high"
for prefix in LOW_CAP_MODELS:
if model_name.startswith(prefix):
return "low"
return None # Model not in free usage groups
def calculate_usage(clean_expired: bool = False) -> dict[str, int]:
"""Calculate total token usage within the last 24 hours."""
now = int(time.time())
cutoff = now - WINDOW_SECONDS
totals = {"high": 0, "low": 0}
valid_entries = []
with LOG_FILE.open("r", encoding="utf-8") as f:
for line in f:
entry = json.loads(line)
created_at = entry["created_at"]
if created_at >= cutoff:
model_group = get_model_group(entry["model"])
if model_group:
totals[model_group] += entry["usage"]["total_tokens"]
valid_entries.append(entry)
if clean_expired:
with LOG_FILE.open("w", encoding="utf-8") as f:
for entry in valid_entries:
f.write(json.dumps(entry) + "\n")
return totals
if __name__ == "__main__":
usage = calculate_usage(clean_expired=True)
print(f"Usage in last 24 hours:")
print(f"High-cap models (1M/day): {usage['high']} tokens")
print(f"Low-cap models (10M/day): {usage['low']} tokens")
Usage Example:
- Logging (after each API call):
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello"}]
)
log_usage(response)
- Checking Usage (run periodically or manually):
python calculate_usage.py
This implementation provides:
- Efficient append-only logging.
- Fast parsing and filtering by timestamp.
- Optional cleanup of expired entries.
- Clear separation of model groups and their respective caps.