Hello, I work at a newspaper and we are testing the OpenAI API.
Currently, we are using both the text-davinci-003 and the gpt-3.5-turbo models and they are working for us.
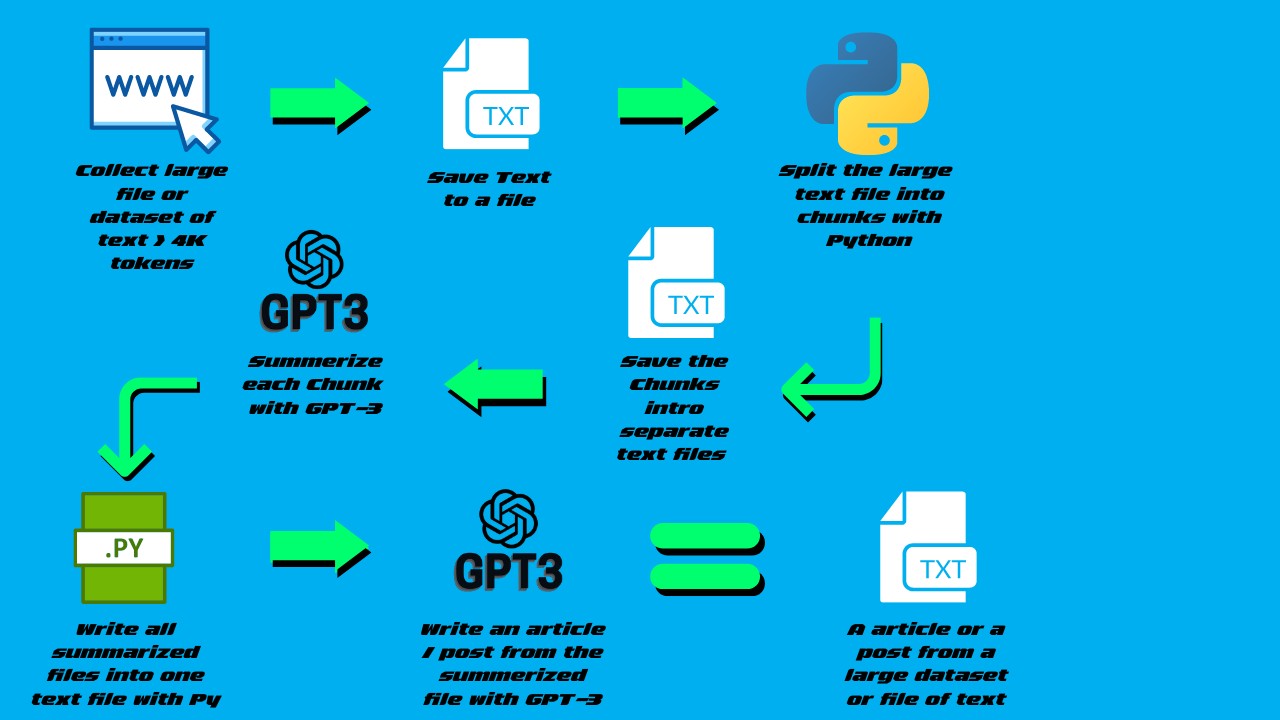
We are using the API to generate summaries of our articles. The problem we’re having is that sometimes the articles are too long and we hit the token limit, which happens about 1 out of every 100 articles.
I read that it’s possible to send pieces of text to the API. I also saw some libraries that can split the text, but I don’t think I need them. I found a library that generates the number of tokens, which seems useful. However, they don’t mention how to send the tokens. I also found some websites that can split the text.
I saw in one place that we can use the chat endpoint and in another that we can use the embed endpoint. In yet another place, I saw that we need to obtain a context ID.
Is there a guide on how to do this? I am working in PHP, but I can read/understand code in any language.
Smaller chunks allow for more understanding per chunk but increase the risk of split contextual information. Let’s say you split a dialog or topic in half when chunking to summarize. If the contextual information from that dialog or topic is small or hard to decipher per chunk that model might not include it at all in the summary for either chunk. You’ve now taken an important part of the overall text and split the contextual information about it in half reducing the model’s likelihood to consider it important. On the other side you might produce two summaries of the two chunks dominated by that dialog or topic.
i was not happy with the map reduce function of langchain as summery of a summery just lose too much detail and the overall output is still too short because of the capped output length
None of those functions would help with trying to extend the token limit. The limit of “size of input” plus “size of output” is a hard limit.
What I do, is setting aside a number of tokens (say 300) for the response, then going through each input document, adding one paragraph in turn to a “current document piece,” until adding the next paragraph would go over the limit. Then I don’t add that paragraph, but instead send the document so far in for summarization. Then I replace the input document I had with the summary, and keep adding more paragraphs from the input. If I hit the limit again, or the end of input document, I send what I have in for summarization again. Yes, this means that you get “a summary of a summary” in the end, but it handles documents of any size.
There is a 1 million token limit method for LLMs. I don’t know how compatible it is with OpenAI’s but I suspect there will be a race to test this out. At the rate things are advancing, I’d say give it a couple of months and you won’t have to worry about that limit.
Yes, it sounds great. I’ve got 8K now with GPT4 and looking forward to 32K. But then, realistically, if the 90% of the query responses I am looking for can be found in 1 or 2 paragraphs, is it really helpful to feed the LLM 50 pages of text for each query? And, isn’t that doing to get prohibitively expensive? I mean, a million token context window will be great for summarizing a book, but how great will it be for finding the paragraph where Huckleberry Finn and Tom Sawyer first encounter Jim in Mark Twain’s “Huckleberry Finn”.
The difference is that the image suggests sending the paragraphs and then combining all the summaries at the end.
Here’s what I did:
Combine the paragraphs based on the number of tokens.
Send them to create a summary.
Combine the previous summary with the following paragraphs based on the number of tokens.
Send them to create a summary.
Go back to step 3.
This way is better because in each generation, I send the context rather than just isolated blocks of paragraphs that may not make sense with the complete text at some point.
I am running that big text system already and splitting the text into chunks. That is the easy part… The problem is api cost and time for content like 500 pages or 100.000 words. To summarize the summaries of all chunks is working well. You have to calculate the maximum size of a chunk summary to fit into maxTokens at final summary. But there is a second option I didnt test on the api but on chatGPT. When you upload the chunks you get a requestID. In fact the model holds all content in memory for your session. I will try to ask for “Summarize requestID 1 to n.” I let you know.
While I don’t know how well it preforms, I think it will do really well for complex tasks. If you think about it right now, in order to get the human like responses, you have to go through a series of prompt chaining to get those really powerful complex responses. A 1 million token limit would greatly limit the complexity of the agent built to respond in a certain way.
I think the real cutting edge stuff it going to be expert help and tasking. In order to do that effectively, the agents need to know quite a bit about your problem and current situation. For example if I need help researching circuit designs or whatever, it would be nice to stuff the prompt with a bunch of contextually relevant data from papers, books, videos, and possibly the work I have been doing up until now. You can do that now to an extent, but in a very limited manner.
One last point, I think the really high efficient token counts will actually drop the price pretty drastically.
Yes, I am beginning to see how this could be a tremendous leap forward. Just the fact that the larger token window will let you submit MORE documents (not just larger documents) to evaluate.
However, for this to be truly useful for the general public, the pricing is going to have to go WAY down. I mean, 8K is 6 cents per 1K and the 32K window is 12 cents per 1K tokens.
I have GPT4 8K access now, but just reverted back to GPT-3.5-turbo 4K window for testing because of the cost.
Yeah 100%. I’m working on a project right now, I have built a ModelPromptObject, which is based off of the DataAccessObject programming pattern. The idea is that I can easily switch between models and APIs, hopefully at some point an inhouse computer running a model. I suspect both Microsoft and OpenAI are greatly overcharging with this token count paradigm they have setup.
Anyone in AI knows that inference is the cheapest part of the whole thing and I think they are probably making quite a bit off of it. The fact that Azure didn’t raise the price compared to OpenAI’s kind of confirms that suspicion. But I have no real data to backup the claim.
But I will definitely be using whatever the cheapest method is and I’m baking in a method for all of my projects to easily swap out the backend.
Thanks for suggesting this method. But can’t we increase the context length of final summary so that we don’t loose much detail since langchain seems to retain the document context as against this method. Don’t you think so?
Hey guys.
Any news about the challenge?
I am developing a project with the aim of summarizing legal documents.
As a test, I’m trying to summarize a legal case in pdf, which has 291,358 tokens. Approximately 650 pages.
{kind=link}