I’m using the Responses API with the image_generation tool. My chat sometimes contains a lot of images sent by users as input (not the generated images), which makes the processing expensive. It looks like image_generation processes every image previously sent by the user every time I call it, increasing the cost.
Is there a way to limit image_generation to only process the most recent 1-2 input images instead of all images present in the chat history? How should I structure the API calls or the user messages to achieve this?
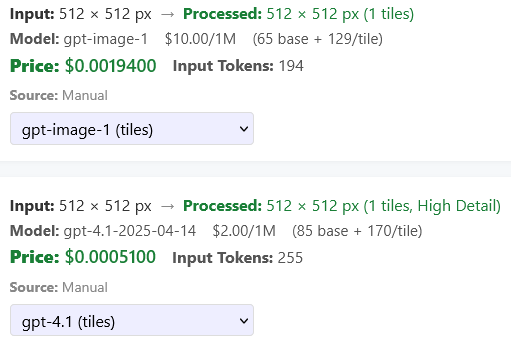
You can observe this topic I created - maybe scroll down to “Responses - this is where the costs pile up”
If you have a fully self-managed conversation, instead of using one of the server-side chat history mechanisms of either previous response ID or conversation, then you do have control over the messages - and can pop those older images out of chat history and let the end user know what is being done. Another alternative is to send those near-obsolete turns as “detail”:low to reduce the resolution to 512x512 for the chat AI itself, which is the actual maximum image that gpt-image-1 will take as input, so you can also resize to about that yourself in concert with the detail parameter. You can decide based on elapsed time between chat turns and input token length if that will break any cache discount possible.
The image input that is consumed again by the gpt-4o-powered image tool is indeed it looking at the full chat context - with no documentation about this actual behavior or its costs by OpenAI, that you correctly ascertained.
The big killer would be sending the input detail “high” - another $0.06 per input image for every image, and again no control over what gets fed in, other than your own management.
Calculable costs, your code’s function: only generate by a prompt - use your own function as interface - call the image generate endpoint - don’t show the chat AI model what was made, just “image success: displayed to user” as a tool return. This also prevents the user saying “make me 10 images automatically without interruption” and the internal tool running free.
I use last_openai_response_id to save the chat context, and I can no longer affect previously sent messages, which, for example, contain images. And I would like the previous images to be ignored from the context.
I mean that image_generation is called when a user requests to generate an image and attaches a source file. However, during generation, the generator analyzes all previously attached files as well, even though it should only process the last two attachments. If only the last two were used, this would both reduce the input cost and lead to more successful generation results, since currently the generator’s analysis of all previous files makes the outputs less accurate than if it focused just on the most recent attachments.
You cannot affect the image count by talking nice to the AI: the image generator is not really a tool; it is turning control over to gpt-4o for image making for a while after the tool call is triggered, where that model can observe the chat instead.
There is no budgeting when using previous response ID, and it is worse and unsuitable because even on text conversation, this will run the AI model up to the maximum input.
You are alreading paying more for persisting image input even if an image is never generated again, to a more costly input model, by using a chat history mechanism that can never “drop older message”.
To reiterate, the ‘model’ does not form a request. There is only a ‘tool’ that acts as a trigger, without even inputs of images to it, and a prompt is optional.
Your only choice is to control the passed conversation context itself.
When you include the image_generation tool in your request, the model (for example gpt-4.1) can decide when and how to generate images as part of the conversation, using your prompt and any provided image inputs.
# Tools
## imageߺgen
// The `imageߺgen` tool enables image generation from descriptions and editing of existing images based on specific instructions. Use it when:
// - The user requests an image based on a scene description, such as a diagram, portrait, comic, meme, or any other visual.
// - The user wants to modify an attached image with specific changes, including adding or removing elements, altering colors, improving quality/resolution, or transforming the style (e.g., cartoon, oil painting).
// Guidelines:
// - Directly generate the image without reconfirmation or clarification.
// - After each image generation, do not mention anything related to download. Do not summarize the image. Do not ask followup question. Do not say ANYTHING after you generate an image.
// - Always use this tool for image editing unless the user explicitly requests otherwise. Do not use the `python` tool for image editing unless specifically instructed.
// - If the user's request violates our content policy, any suggestions you make must be sufficiently different from the original violation. Clearly state the reason for refusal and distinguish your suggestion from the original intent in the `refusal_reason` field.
namespace image_gen {
type imagegen = (_: {
prompt?: string,
}) => any;
} // namespace image_gen
You can see that there is nothing about passing images, just a prompt where the question mark signals prompt is even optional.
The control you have is only stylistically: the image generation can observe you saying: “the best image background was the first one, but use the subject from the most recent image, and don’t consider the intervening 15 images that we’ve tried out”. You still pay for all the images passed, in pricing for the conversation being run against two different models.
I understand that I’m paying for vision - it’s pennies compared to the image_gen tool $10 for 1 million input tokens in base64 + high input_fidelity, therefore, I want to specify gpt-4.1 so that it calls the tool as little as possible if no generation is required.
It would be good if GPT did not send more than 2 last images from the dialog to image_gen, according to the system message. When generation is needed. If generation is not needed, vision should be used (no tool calls).