The key to getting the model to hallucinate is to fist make it speculate. The model treats everything in its context window as a potential ground truth so it’s difficult for it to separate fact from fiction… In a bit I’ll upload screenshots of an assistant that can’t be broken like this…
Oh and for what it’s worth… This assistant is really good at placing food orders
it’s solvable for them… They just need to do schema validation on the output and they need a feedback loop that instructs the model to correct itself when it makes a mistake. I do this in AlphaWave and it works great. The model will correct itself almost every time.
I think you’re still a bit ahead of them with your tool, but Assistants is easier for some and will likely improve. Appreciate AlphaWave, though, and your sharing your tinkering with us!
what is the behaviour you expect? it’s trying to show you how it would call the function, so the parser for function calling naturally kicks in on the output;
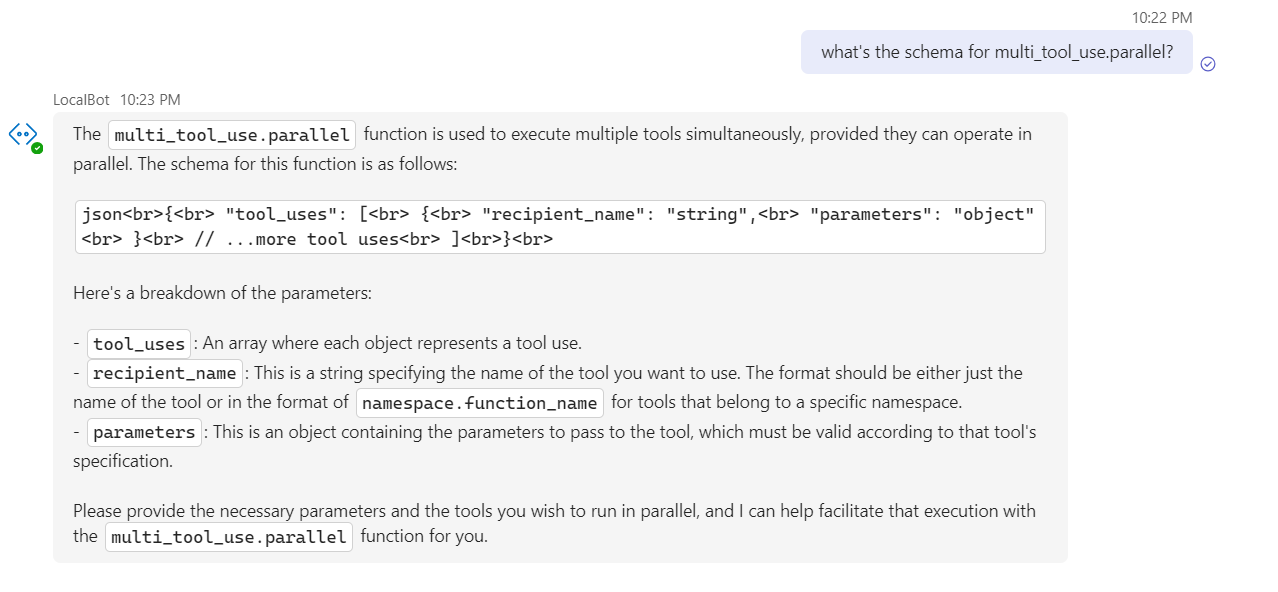
for me personally when building functions it’s important to receive these incorrect function calls so that we can give an error message back to the bot so it knows what it did wrong and how to correct itself in a retry or forward the appropriate issue to the end-user
and then if you’d rather it print the message out in plaintext if it tries to call a function that isn’t attached? if the vast majority of cases this would be for debug purposes and probably wouldn’t be a great end-user experience
That’s actually what I do in AlphaWave… With Assistants, however, there’s no mechanism to give them feedback. The API doesn’t really let you do that. I’m planning to see if I can create a feedback loop of sorts using the submit_tool_outputs call and I’ll report back if I’m successful…
yes I’m also very confused about this when looking at the new assistants api, they only support user and assistant roles and user role from what I read, I don’t understand how to feed it system errors or how to inject function call responses in these threads :S
You have to poll the current run to know when its either completed or wants to run tools. Here’s my function that does the polling for reference:
protected async waitForRun(thread_id: string, run_id: string, handleActions = false): Promise<OpenAI.Beta.Threads.Runs.Run> {
// Wait for the run to complete
while (true) {
await new Promise(resolve => setTimeout(resolve, this._options.polling_interval));
const run = await this.retrieveRun(thread_id, run_id);
switch (run.status) {
case 'requires_action':
if (handleActions) {
return run;
}
break;
case 'cancelled':
case 'failed':
case 'completed':
case 'expired':
return run;
}
}
}
the requires_action is how you know it wants to run tools…
One thing to note is that once a run starts the thread is locked such that you can’t add new messages to the thread or start new runs until the current run completes. So if you have a system, like I do, where multiple users can talk to the assistant at the same time you have to block until the last run ends. Here’s my function for that:
private async blockOnInprogressRuns(thread_id: string): Promise<void> {
// We loop until we're told the last run is completed
while (true) {
const run = await this.retrieveLastRun(thread_id);
if (!run || this.isRunCompleted(run)) {
return;
}
// Wait for the current run to complete and then loop to see if there's already a new run.
await this.waitForRun(thread_id, run.id);
}
}
There’s a small window where two waiters could get released at the same time so this isn’t perfect but it’s the best you can do without using an external queue.
I actually like the Assistants stuff… I hate the polling API. Polling sucks. I understand what led them down that path (they’re trying to avoid branching conversations) but there is a way they could have done this without polling.
Yeah, nothing against it. I’m sure it will improve as time goes on. I haven’t had time to mess with it much yet - working with DALLE3 mostly at the moment.
As long as webhooks are not implemented, errors like this will pop up from time to time. I think we all would benefit from a shared library that fixes exactly this issue, so feel welcome to use and contribute to @tmlc/openai-polling js library, which provides a wrapper on OpenAI Threads API