“Each assistant incurs its own retrieval file storage fee based on the files passed to that assistant.” …
“The tokens used for the Assistant API are billed at the chosen language model’s per-token input / output rates and the assistant intelligently chooses which context from the thread to include when calling the model” …
So, is it that there’s both…
a storage/transfer fee (really a flat fee for daily storage, or only incurred for the days on which the files are used?)
a token fee… (but it’s not possible to estimate this, as the knowledge may be used to a greater or lesser extent?)
?
“Retrieval is priced at $0.20/GB per assistant per day. If your application stores 1GB of files for one day and passes it to two Assistants for the purpose of retrieval (e.g., customer-facing Assistant #1 and internal employee Assistant #2), you’ll be charged twice for this storage fee (2 * $0.20 per day). This fee does not vary with the number of end users and threads retrieving knowledge from a given assistant.”
I don’t fully understand!
My use case is…
To set up an Assistant that would be infrequently used and only by me.
The files for retrieval would be an archive of 325 blog posts.
New blog posts generated in response to my prompt should draw partly on the archive.
So, for your use case, lets assume you have 100Megabytes of files stored or 1/10th of a gigabyte.
You would pay $0.02 per assistant per day, you have just one assistant so just $0.02 per day.
Then you would have your token costs which would be whatever your prompts and replies are plus whatever tokens are used by the retrieval system to complete each request, that quantity cannot really be predicted as it stands, but could potentially be up to the context limit of 128k tokens.
Thanks for clarifying. So there really is a storage fee per day.
Bonus question:
My blog archive is now in a 2.3Mb CSV file (column A: Title, column B: Body in Markdown), though I could also make it available in JSON.
Is it more cost-efficient to upload it as this single CSV, or to export the individual blog posts to .txt files?
I’m wondering if the algorithm would start by using the post title (which could be the individual file name), and if this would be more efficient than it ploughing through a .csv repeatedly.
On second thoughts, maybe better to assume that this is handled by OpenAI’s vector database and that this is much smarter than me?
I believe there is a 20 file upload limit, so that kind of answers your query The underlying system is Azure AI Search, so you can look up the specs of that from microsoft and hopefully that will guide you as to how it’s doing what it does.
Actually, .csv isn’t an allowed format. So I uploaded the blog archive as .json, asked Playground it to write a new post informed by the old posts. It was very slow, and then it wrote a post.
No immediate update to my Usage dashboard figure, but my current monthly bill has now moved from $0.96 to $1.10. So that’s $0.14.
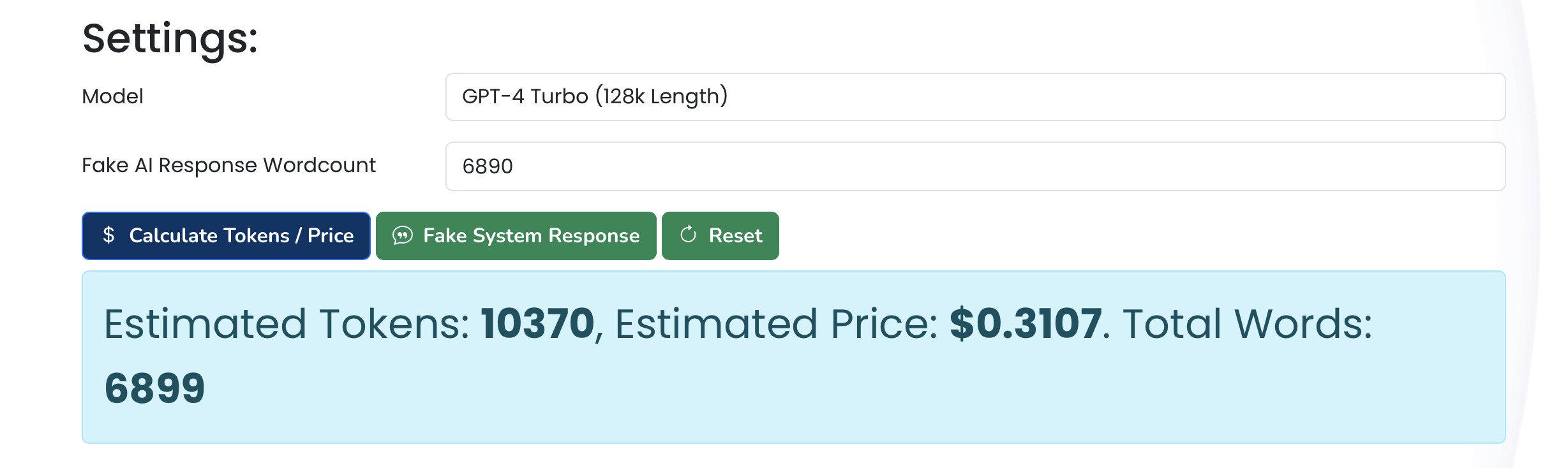
I don’t know why the job took 4 API requests (this was a single instruction to write the article). But seems to have used 10,409 “context” tokens - I guess this comprises the amount of the overall upload that was utilised to inform the output (?)…
If I’m accurately reverse-calculating this using the calculator at ArticleFiesta, this would mean about 6,890 words out of the many-more-thousands in my 300+ blog posts were used, I guess… ?
I don’t know where you have gotten the idea that a csv file, a pure text file, if not allowed, it absolutely is allowed., but the cost is, as you correctly assumed, mostly from the retrieval tokens as the files were loaded as context.
14 cents feels like the right number, as opposed to 31 cents, as the context tokens are “input” and so at the lower price. The ultimate question then becomes, is the resulting text output by the model worth more than 14 cents to you, if so… happy days, if not… some refinement needs to take place.
Very confused by that, I don’t call my csv files .csv, just .txt and I use them quite a lot, it’s just a text file with values separated by , or some other character.
I’m facing a similar confusion as the original poster (OP), and even after reading the accepted answer, I still have some questions. Here’s a bit about my setup and use case:
This setup is for my personal use.
I have only one assistant in my program.
Each time I start my program, which utilizes the assistant’s API, I retrieve the existing assistant and create a new thread.
I don’t upload files directly to the assistant or threads, just in the messages on those threads.
Since a new thread is created every time the program starts, I end up with many threads that are not in use but may have attachments.
Given this context, I have a few questions regarding the billing and file management:
File Upload and Billing:
If I upload two files using the files API, each being 500MB, but only reference one of them (500MB) in a message, am I billed for the 500MB that I used or for the total 1GB because I uploaded both and the assistant has retrieval enabled?
Retrieval Costs:
If retrieval is enabled but I never reference any file_id in messages, does that mean the assistant incurs no daily cost since it doesn’t reference any files in its messages or threads?
Storage Fees for Unused Threads:
If I create many threads and reference file_ids in messages within those threads, but never actually perform a “Run” on those threads using the assistants API, am I exempt from storage fees for those files, given that the threads contain file references but were never used?
I would really appreciate any guidance or clarification on these points. Thank you in advance for your help!
I asked the same question basically on a different thread. It’s a mystery to me why the API doesn’t at least returned tokens used for Assistant if not the cost – it can easily do the math!
It’s a major problem for commercial users who have to build a cost model to see if it is economically feasible to use the functions.
I’ve launched an open-source digital assistant called ORION. It leverages various features, including the assistant’s API, text-to-speech, speech-to-text, and seven functions for smart home features, weather updates, and file system tasks. Operating costs are a concern; with all features enabled, daily usage during testing shows approximately $1.5 with GPT-3.5 Turbo, but this can skyrocket to around $5 with GPT-4 Turbo. I haven’t enabled or used retrieval yet, but I do use the code interpreter. In other words, 2x-8x a ChatGPT subscription
Retrieval is priced at $0.20/GB per assistant per day. Attaching a single file ID to multiple assistants will incur the per assistant per day charge when the retrieval tool is enabled. For example, if you attach the same 1 GB file to two different Assistants with the retrieval tool enabled (e.g., customer-facing Assistant #1 and internal employee Assistant #2), you’ll be charged twice for this storage fee (2 * $0.20 per day). This fee does not vary with the number of end users and threads retrieving knowledge from a given assistant.
In addition, files attached to messages are charged on a per-assistant basis if the messages are part of a run where the retrieval tool is enabled. For example, running an assistant with retrieval enabled on a thread with 10 messages each with 1 unique file (10 total unique files) will incur a per-GB per-day charge on all 10 files (in addition to any files attached to the assistant itself).
note the line specifically talking about files attached to messages:
In addition, files attached to messages are charged on a per-assistant basis if the messages are part of a run where the retrieval tool is enabled.
This seems to imply that you are only charged for indexing if the files are attached when you actually perform a run.
Example:
POST https://api.openai.com/v1/threads/{thread_id}/runs