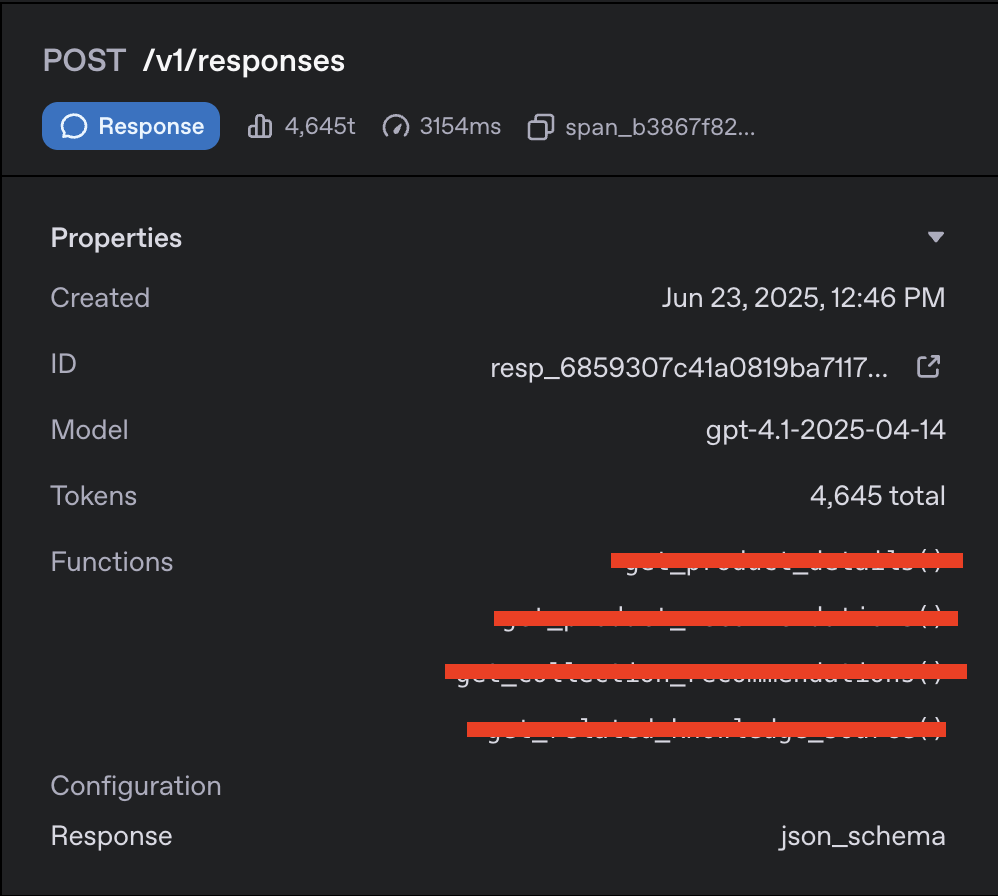
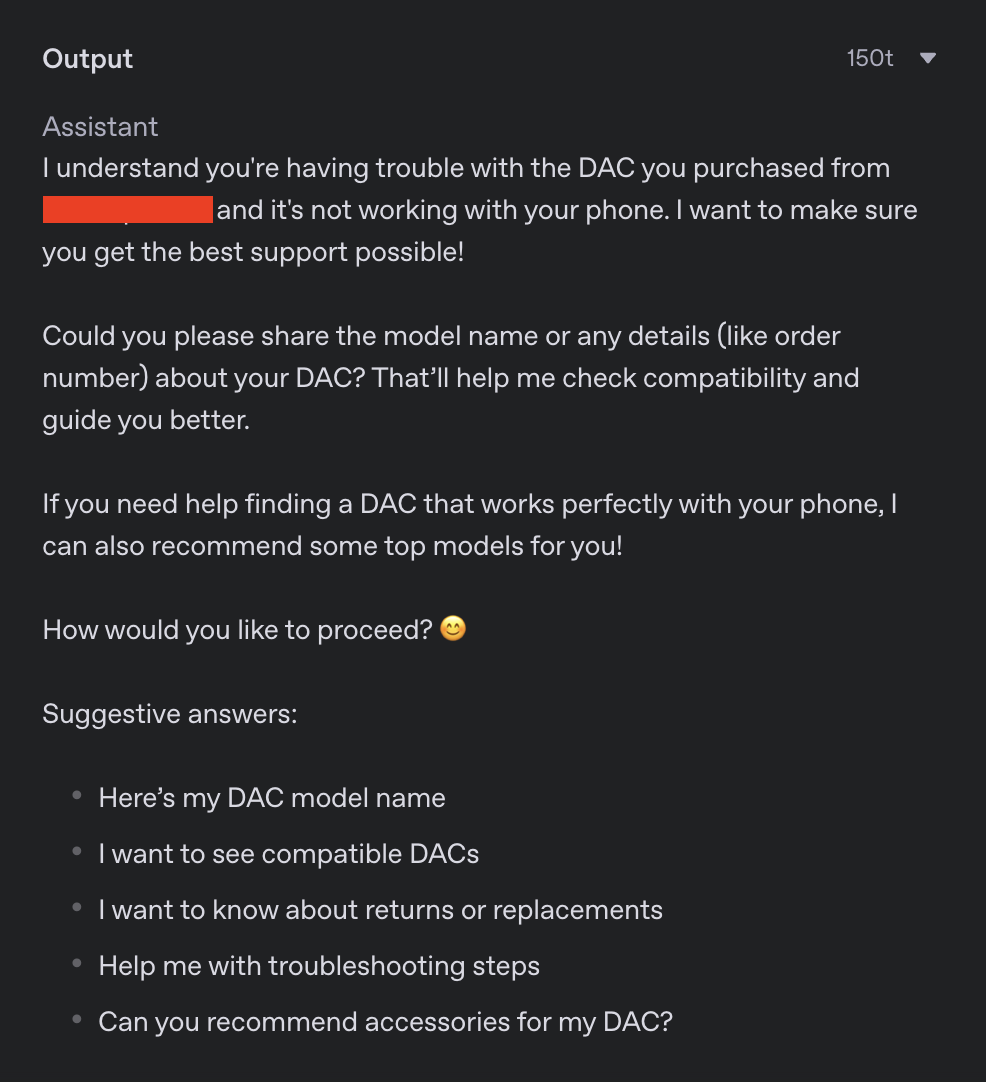
Sometimes (maybe less than once in every thousand request) model doesn’t follow strick structured output schema. See the following example, even if there is a json_schema, the output is a string without defined fields.
I’m not sure whether the temperature value would improve this (especially since you reported a less than 1 in 1000 error rate), but what is the value you’re using at the moment? Also, was there anything peculiar about the input prompts in the cases where it does deviate?
Your other topic’s result is gpt-4.1 failing to emit the correct stops sequence.
Also that the Responses endpoint blocks you from solving this. When a failure of a model is combined with a failure of an endpoint (yes, I meant that in the non-transitory way), the result is that there is no alternate stop sequence parameter (such as linefeed) to terminate the output, and no working bias parameter to promote the correct stop token. No frequency penalty to demote 2000 tokens of a loop. Only a max_output_tokens that could set your maximum budget of nonstop output.
However here, the context free grammar for a response format sent with a request completely failed to work at all. It is likely there was not even a schema placement in the context for the AI to follow. The AI just responded to the user.
Diagnosis:
One can carefully reconstruct the same call, and look at the input token expense vs that API call previously billed - you will be charged more when your schema language is actually placed for the AI vs when it is not or when you simply don’t send the text format for json_schema as API parameter.
Repair:
Just one more thing for OpenAI to fix to make failure impossible, and to then implement configuration management and beta cycles to stop delivering immediate overnight breakage…a minimum viable product is not a viable product.