Summary of what I’ve found so far:
Model sizes:
-
Ultra: The strongest model. It’s optimized for scalability on TPU accelerators.
Release: Early next year to select customers, developers and partners for early experimentation and feedback. -
Pro: Optimized for performance, cost, and latency.
Release: It is already available in the English version of Bard. Starting on December 13, developers and enterprise customers can access Gemini Pro via the Gemini API in Google AI Studio or Google Cloud Vertex AI. -
Nano: Designed for on-device applications. It comes in two versions (1.8B and 3.25B parameters) and is optimized for deployment with best-in-class performance in tasks like summarization and reading comprehension.
Release:
Training and Architecture:
Multimodal Training: The models are trained jointly across text, image, audio, and video data. They can handle a variety of inputs like natural images, charts, screenshots, PDFs, videos, and produce text and image outputs.
Architecture: Built on Transformer decoders with enhancements for stable large-scale training and optimized inference on Tensor Processing Units (TPUs).
Context Length: Supports a 32k token context length.
Multimodal and Multilingual Dataset: Utilizes data from web documents, books, code, and includes image, audio, and video data. Handles non-Latin scripts and is trained with a focus on data quality and safety filtering.
Performance and Capabilities:
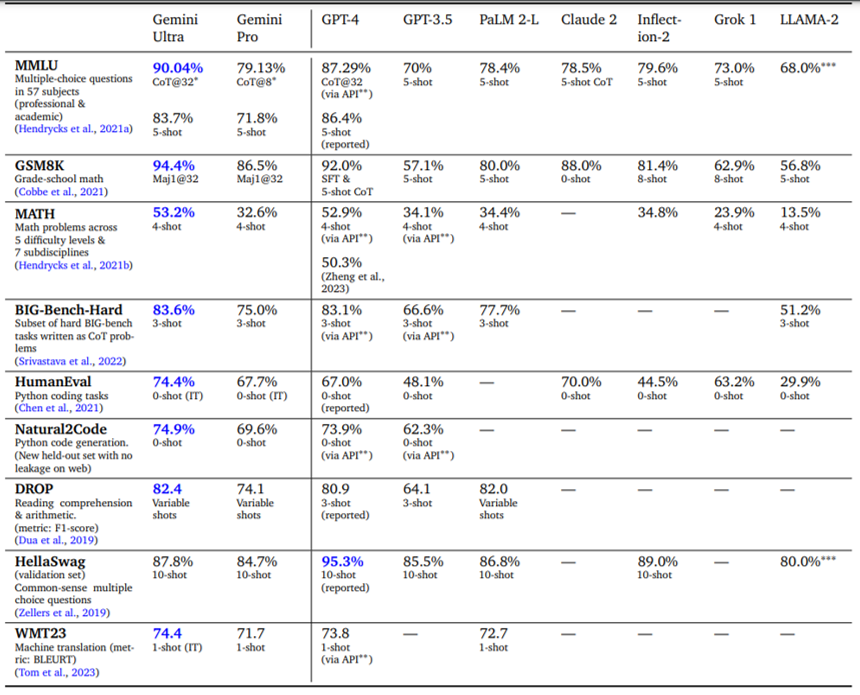




Highlights:

I’ve already tested the Pro version on Bard and it’s working. But the version that promises to be better than GPT-4 will take some time before it is actually released.
Another point to note is that the model is named Gemini 1.0, suggesting that future versions are expected to be released.