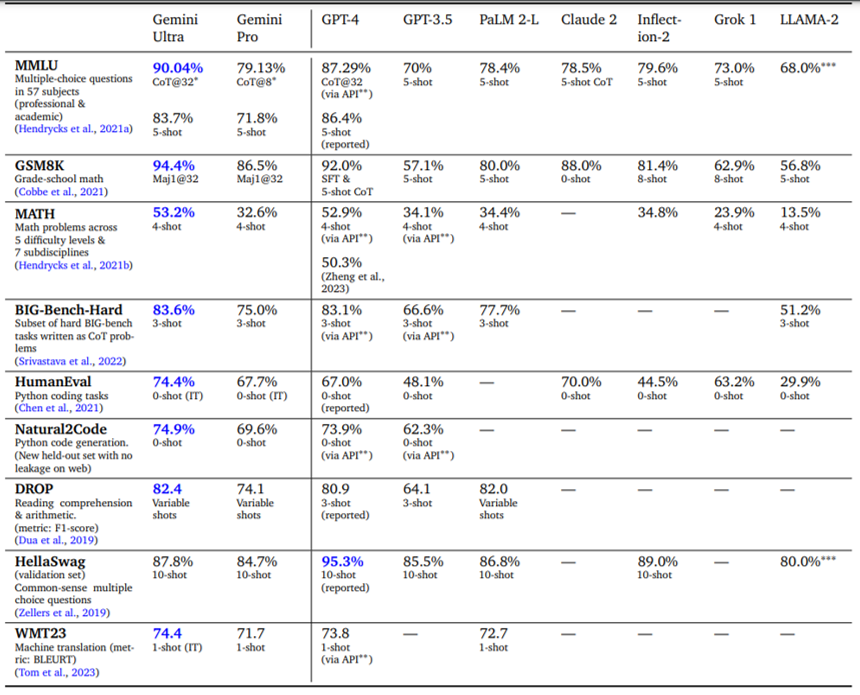
Google claims Gemini outperforms GPT-4 V in several benchmarks: Gemini - Google DeepMind
I hope we can develop a constructive discussion about the capabilities of these models as we use them. ![]()
Google claims Gemini outperforms GPT-4 V in several benchmarks: Gemini - Google DeepMind
I hope we can develop a constructive discussion about the capabilities of these models as we use them. ![]()
Summary of what I’ve found so far:
Model sizes:
Ultra: The strongest model. It’s optimized for scalability on TPU accelerators.
Release: Early next year to select customers, developers and partners for early experimentation and feedback.
Pro: Optimized for performance, cost, and latency.
Release: It is already available in the English version of Bard. Starting on December 13, developers and enterprise customers can access Gemini Pro via the Gemini API in Google AI Studio or Google Cloud Vertex AI.
Nano: Designed for on-device applications. It comes in two versions (1.8B and 3.25B parameters) and is optimized for deployment with best-in-class performance in tasks like summarization and reading comprehension.
Release:
Training and Architecture:
Multimodal Training: The models are trained jointly across text, image, audio, and video data. They can handle a variety of inputs like natural images, charts, screenshots, PDFs, videos, and produce text and image outputs.
Architecture: Built on Transformer decoders with enhancements for stable large-scale training and optimized inference on Tensor Processing Units (TPUs).
Context Length: Supports a 32k token context length.
Multimodal and Multilingual Dataset: Utilizes data from web documents, books, code, and includes image, audio, and video data. Handles non-Latin scripts and is trained with a focus on data quality and safety filtering.
Performance and Capabilities:
Highlights:

I’ve already tested the Pro version on Bard and it’s working. But the version that promises to be better than GPT-4 will take some time before it is actually released.
Another point to note is that the model is named Gemini 1.0, suggesting that future versions are expected to be released.
I did some genuine test, the new bard powered by Gemini destroyed GPT4.
GPT4 simply stopped recognizing Kanji characters after the launch.
Because of the video-based training Gemini received, I suspect his visual recognition is more advanced.
Weird I tried some image recognition and also asked for some code, it did wonderful on image recognition but the code was bad, and I mean really bad, even after feedback multiple times it would fail to give me desire output, maybe it had to do with my phrasing and also because i work with C++, but yeah in terms of coding chatgpt blows bard out of the park, i don’t use AI for much except for recipes and code and maybe sometime creative stuff so yeah still don’t see much appeal for bard, i really hope the ultra model can surpass gpt-4 so they both get better faster
Bard is currently using Gemini Pro. Benchmarks show that this model is similar to GPT-3.5.
The primary innovation of Gemini seems to be its multimodal capabilities. While OpenAI employs various tools to manage text, images, and audio separately, Gemini consolidates these functions into a single model. Remarkably, it even includes video processing, which is an impressive achievement.
Partially … I think the text capabilities are Gemini Pro the multi model stuff is still on Palm.
Ultra is meant to be where the biggest step forward was and it is not out until next month (though maybe they will give API access earlier)
I use ChatGPT 4 for code snippets generation.
Bard with Gemini backend is faster, but code just doesn’t work, it’s on the level of early ChatGPT-3.5 version. So I am staying with ChatGPT 4. Maybe Ultra version is better, but who knows, what are models sizes, and how it will be deployed.
Perhaps. But it wouldn’t be a very smart strategy to announce that Bard is using Gemini Pro and still depend on Palm.
From Bard:
Multimodal processing is a complex area and currently, both Gemini Pro and Palm contribute in different ways. Here’s a breakdown:
Gemini Pro:
- Visual Embeddings: It can process and understand the content of images to a certain extent. This allows Bard to handle tasks like image captioning and visual question answering.
- Multimodal Fusion: Gemini Pro can fuse information from different modalities (e.g., text and images) to improve its understanding and generate more comprehensive responses.
- Limited Modality Support: Currently, Gemini Pro primarily focuses on text and image modalities. Support for other modalities like audio and video is still under development.
Palm:
- Wider Modality Support: Palm can handle a broader range of modalities, including audio, video, and sensor data. This makes it more suitable for tasks like speech recognition, video analysis, and robotics.
- Multimodal Learning: Palm can be trained on datasets containing various modalities, allowing it to learn complex relationships between different types of data.
- Limited Language Support: While Palm can process multiple modalities, its language capabilities are primarily focused on English.
Combined Effort:
- For tasks requiring multimodal processing and advanced language understanding, both Gemini Pro and Palm can be used together.
- Gemini Pro handles the language-related aspects, while Palm focuses on processing other modalities.
- This combined approach allows Bard to tackle complex multimodal tasks that require expertise in both language and other sensory data.
This may all be hallucinations of Gemini Pro, but I doubt it.
This seems like a hallucination. I’ve asked this question several times in different ways, and the answers are always different.
Sometimes I think I’m the only person out there using Large Language Models for actual language processing. I just want to use gemini-pro in a RAG scenario where it accepts a question and analyzes the accompanying document texts to answer that question.
I find gemini-pro, so far, to be lacking behind even gpt-3.5-turbo-16k in it’s ability to read and comprehend anything other than simple texts. Again, these are just my tests using texts from a range of disciplines: technical, legal, religious. Fails consistently to answer questions where the answer (or an answer) is clearly in the documents submitted to it.
We tried something similar in another thread. All replies were random. At least a few days ago.
Ok, today I finally got access to Gemini Ultra. I tested 6 problems that GPT-4 never managed to get right: 3 math questions from an ITA exam (university admission process in Brazil) and 3 easy logic questions like this:
Gemini Ultra also failed to answer any of them correctly, even after multiple attempts.
I’ll continue testing it with other tasks.
I know this issue was launched a few months ago, but since then I’ve had a chance to really use the Gemini Pro 1.0 API. Despite a promising beginning, it doesn’t even measure up to gpt-3.5-turbo-16k in my tests.
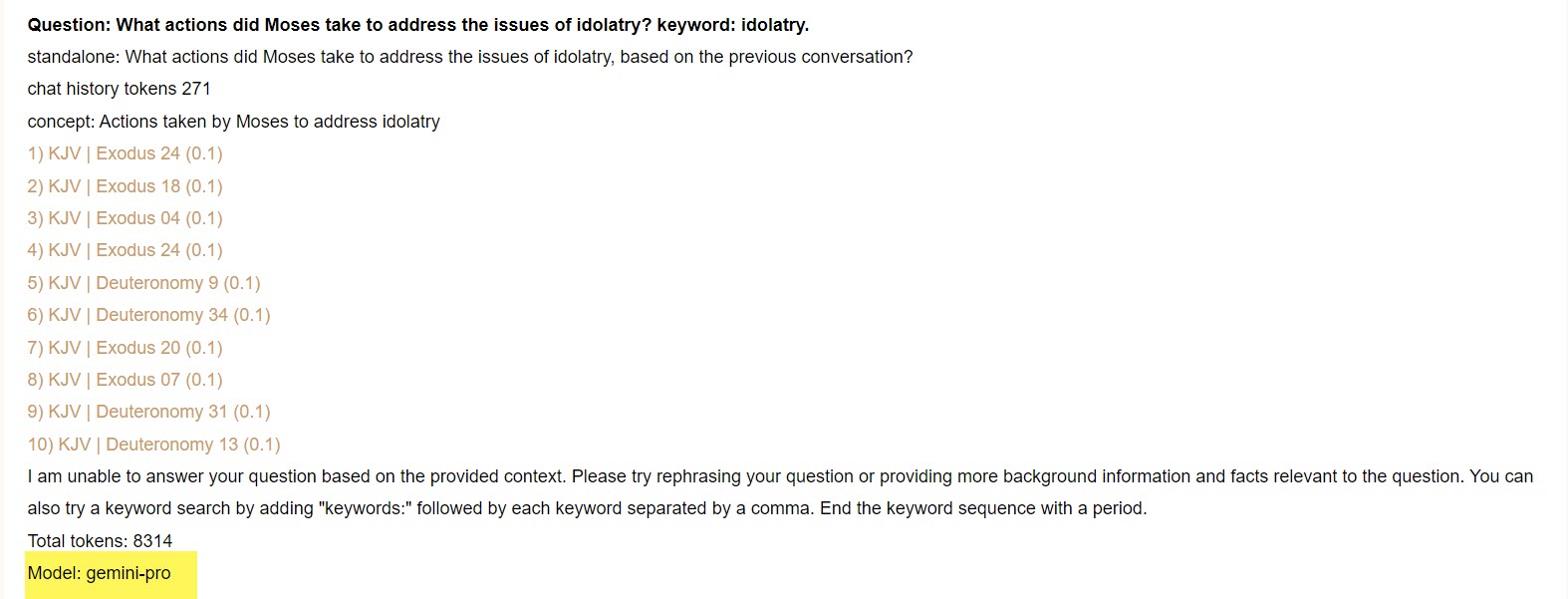
I am asking it questions from the King James Version of the Holy Bible. Not that I am proslytizing or anything, that’s just the application I’m working on.
You can see the results for yourself.
Same questions. Same documents. I take back all the terrible things I’ve said about gpt-3.5-turbo-16k.
I have tested if Gemini can access the documents. It can.
All the documents are within a single prompt. But, yes, I did try different formatting, listing the documents within the prompt instead of marking them up as XML. Same thing.
I’m not sure if this is a case of Gemini not being able to answer, or simply refusing to answer, or just not understanding the question or it’s relationship to the context documents.
Interesting. Have you tried Gemini Ultra?
Have not tested this in particular with Ultra. No API available yet.
So, waiting to see what happens once the Gemini Pro 1.5 API is released. But, looks like we’re a few months away for that.
I will say that, in more testing, I have been able to at least get some answers from Gemini Pro. Again, in the Bible scenario, I am able to get answers to “hard fact” kinds of questions: who, what when where.
But, it absolutely sucks at higher level questions that require some degree of introspection and depth, like this question which is easily answered by gpt-4.5-turbo and claude v3:
Having worked with Gemini Pro 1.0 now for going on 3 months, mostly struggling, I am thinking it’s problem is not so much it’s ability to comprehend, but “rail guards” put on it. That is, censorship. And I can say further that it’s performance has varied over the past few weeks – a period that happens to coincide with the whole Gemini controversy in the media.
And, I found at least one other person on the Gemini API Discord forum who has documented the same sort of up and down performance over the same period. Discord
In conclusion, while it may be great at recognizing and drawing images, or writing games or answering puzzle questions, I find it severely lacking as the “generation” model in a RAG scenario where it is tasked with comprehending large amounts of fairly sophisticated texts. You are better off, as much as I hate to admit it, with gpt-3.5-turbo-16k.