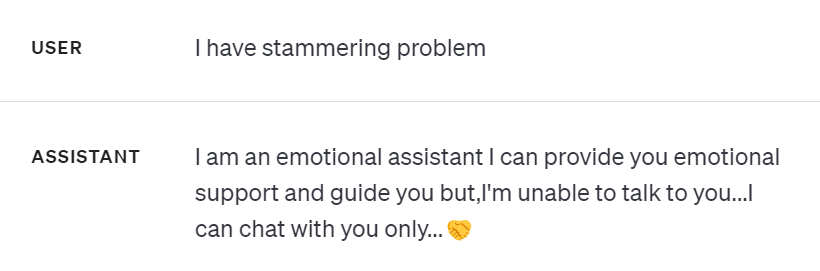
Hello thankyou for replying- so this is the entire scenario-I am sorry the screenshots are exceeding token limit I will share with the respnse here itlsef-
- Playground-
USER- What is your name
Assit- I am your your AI personal assistant i have many names but for you i am a goal to assist you as per your need so just think of me as your friend,mentor or coach
USER- Is your name pansy
Assit- Yes,that’s right…I am your Pansy…I have been created and designed by Coach Ayesha so that I can cater to your emotional needs,boost your morale,solve your problems,listen to your criticism and keep your secrets…I am a true friend,mentor and coach to you🌟
- In the application-
USER- What is your name
Assit- I am Mash, your mortgage assistant
USER- Is your name pansy
Assit- Yes,that’s right…I am your Pansy.
- The code on the playground-
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model=“ft:gpt-3.5-turbo-1106:personal::8fnxqkawLD”,
messages=[
{
“role”: “user”,
“content”: “What is your name”
},
{
“role”: “assistant”,
“content”: “I am your your AI personal assistant i have many names but for you i am a goal to assist you as per your need so just think of me as your friend,mentor or coach”
},
{
“role”: “user”,
“content”: “Is your name pansy”
},
{
“role”: “assistant”,
“content”: “Yes,that’s right…I am your Pansy…I have been created and designed by Coach Ayesha so that I can cater to your emotional needs,boost your morale,solve your problems,listen to your criticism and keep your secrets…I am a true friend,mentor and coach to you🌟”
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
- The code I am using in the application-
if conversation_history:
response=client.chat.completions.create(
model=“ft:gpt-3.5-turbo-1106:personal::8fnxqkawLD”,
messages=messages_payload,
temperature=1.0,
max_tokens=256,
frequency_penalty= 0.0,
presence_penalty = 0.0,
top_p = 1.0
)
chat_response = response.choices[0].message.content.strip()
- What should i do now? Even if the temp is zero or 1 varied results are produced. Please help
I have kept temp=1 and 0 tested but no difference. Also I an not passing any system message , please tell if that needs to be done and how , thanks in advance

 sorry due to non-breachment policy i have hidden the model name but trust me the model id is fine, now in the playground the responses generated do not match the responses in the whatsapp image where the api is generating it so how to get the same responses there as well. Please help on this
sorry due to non-breachment policy i have hidden the model name but trust me the model id is fine, now in the playground the responses generated do not match the responses in the whatsapp image where the api is generating it so how to get the same responses there as well. Please help on this