I am quite interested in how fast Groq and Cerebras made their systems. And I want to know if it would be possible for OpenAI to use their compute power to speed up GPT models (in theory).
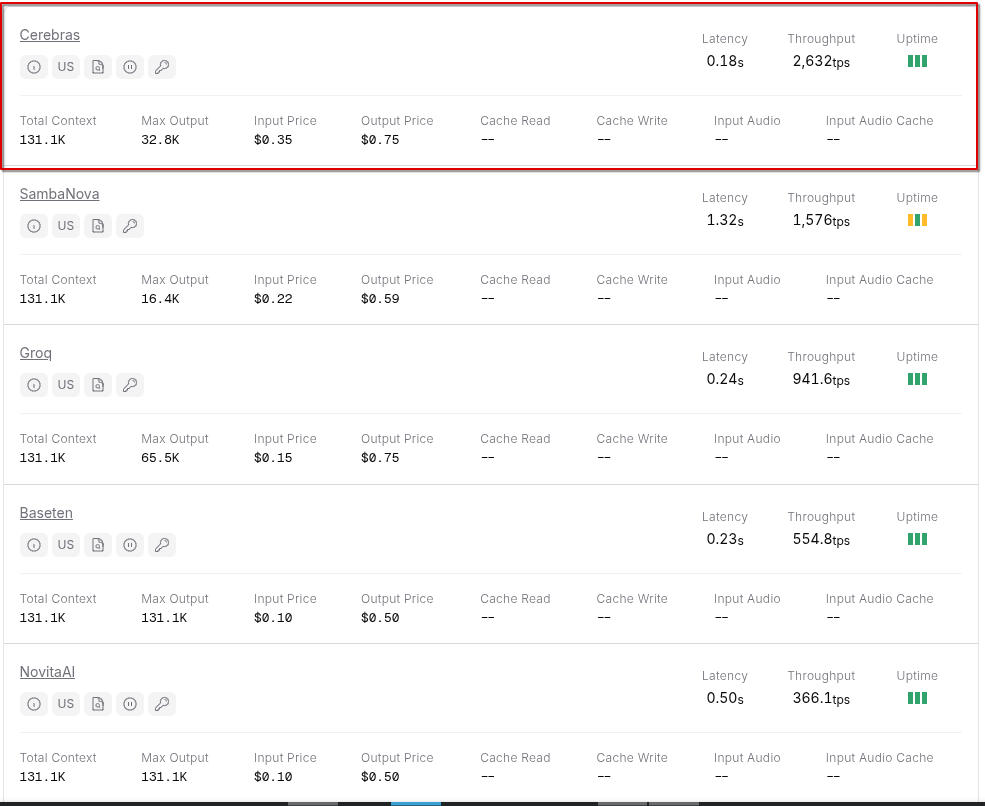
From OpenRouter, we can see a very significant increase in throughput compared to other providers:
With Qwen, the gap is 16 times (Compared with Together) (I cannot include more than one img and no links, so use OpenRouter to search for the information please).
So, is GPT not able to run on Cerebras hardware? Am I wrong and missing a critical detail?
Could OpenAI allow us to run GPT on Cerebras similar to how we can run GPT on Azure? Or could they offer the models to us running on Cerebras systems? I would even pay more per token to run it there if we have speed improvements.
There is also Groq, but Cerebras tends to be faster under the same scenarios (I tested 30 prompts 5 times with GPT OSS 120B and 20B).
I agree, but the speed of the models is not just about having more physical hardware than anyone. Cerebras’s and Groq’s chips are just faster at the calculation (at least if I understand it correctly).
If we take this blog post (www.cerebras.ai/blog/cerebras-cs-3-vs-nvidia-b200-2024-ai-accelerators-compared) by Cerebras (I know there is bias in it, but just take a look at the results), we can see that their hardware is just faster, more memory dense, and processes more data at once. So I think (PS: not a hardware expert), in theory, they should be faster than the current tech we have.
If we take a look at GPT-OSS 120B on OpenRouter (openrouter.ai/openai/gpt-oss-120b/providers?sort=throughput), we can see that the top performers for throughput are Cerebras, SambaNova (another custom chip), and Groq. So they are doing something right, or I am missing some critical information. If so, please show me where I am wrong.
PS: Links are in plain text because I cannot add links to this post, but without them it would be difficult to contextualize the information.
What your test doesn’t show (and can’t show right now) is how Cerebas hardware can scale.
OpenAI has a massive customer base - and it’s constantly growing. Customers may view Cerebras as a risk compared to the current plans OpenAI has for compute - Just sayin…
Please note: As an independent software engineer, this is only my opinion.
What your test doesn’t show (and can’t show right now) is how Cerebas hardware can scale.
I agree with you partially. You can’t test scale if you don’t test scale. I am not saying, “Hey OpenAI, today, change your whole infra to Cerebras and see what happens,” but it would be cool if they allowed us to use them somehow for the (supposed) speed improvements.
Customers may view Cerebras as a risk compared to the current plans OpenAI has for compute
True, but they (Cerebras) offer a cloud platform, so you can literally just host models there, like we can do in Azure. Wouldn’t this solve the “trust” problem?
They could also just release a “new” model, let’s say gpt-5-cerebras, which will use the same underlying gpt-5 model just on Cerebras infra (could be their cloud platform).
Please note: As an independent software engineer, this is only my opinion.
Good, Software engineer here as well. And I am asking for it, so do not worry.
! Another note: I am saying Cerebras because I saw Cerebras first (compared to Groq, SambaNova, and DeepInfra), but if there is other faster infra, just use that. I am in no way connected to Cerebras; I just use GPT OSS 120B, and other models in OpenRouter using the Cerebras provider, and I have seen a lot of speed improvements in my products.
Well, it’s true that enterprise customers need a protected environment and gpt-oss-120b could be a compelling solution when hosted by Cerebras…
But enterprises can ceate their own H100 stack and host their own gpt-oss-120b, right?
Enterprises can create their own H100 stack and host gpt-oss-120b on-premise. Hosting the model in-house offers greater control over data, security, and costs, but it requires significant investment in specialized hardware and infrastructure.
Requirements for hosting gpt-oss-120b on-premise
Hardware
H100 GPUs: A single NVIDIA H100 80GB GPU is sufficient for running gpt-oss-120b for inference due to its highly optimized Mixture-of-Experts (MoE) architecture. For higher throughput and performance, especially under heavy load, deploying the model across multiple H100 GPUs (e.g., 4x or 8x) is recommended.
GPU memory (VRAM): A single H100 provides the 80GB of VRAM required to load the model and its active parameters.
System memory (RAM): The server or workstation requires a minimum of 128GB of system RAM for the 120B model, in addition to the VRAM on the GPU.
Networking: High-speed networking, such as the 350Gbps offered on cloud services, is essential for minimizing bottlenecks, especially in multi-GPU deployments.Reference designs: Hardware vendors like Dell offer validated solutions, such as the “Dell AI Factory,” which combines PowerEdge servers with NVIDIA GPUs for implementing AI workloads on-premises.
Software and deployment
Inference servers: To run the model efficiently, enterprises need to deploy an inference server. Common options include:
NVIDIA NIM: Optimized for NVIDIA’s Hopper and Blackwell GPUs.
vLLM: A popular and highly performant inference engine.
Ollama: A simpler tool for local or on-premise model hosting.
Model optimization: Frameworks like NVIDIA’s TensorRT-LLM can be used to optimize the model for specific hardware configurations and improve performance.
Licensing: Since gpt-oss-120b is released under a permissive Apache 2.0 license, enterprises can use it for experimentation, commercial deployment, and fine-tuning without significant restrictions.
Business and security considerations
Data sovereignty: For enterprises handling sensitive or regulated data, hosting the model on-premise ensures that data processing remains within a controlled and chosen region, meeting data sovereignty requirements.
Customization: Self-hosting gives enterprises complete control to fine-tune and adapt the model with their proprietary data, creating a more tailored and powerful solution.
Cost avoidance: Enterprises can avoid recurring API fees and manage costs more predictably than with a pay-per-use cloud service.