it claims to be the fastest model ever and also very cheap. I used it in Graphrag as the drift local search retriever, which makes it possible to go deeper to get more in-depth informtion without lagging the response speed too much. However, the model’s answer is way too stupid and seems unreliable. I’m afraid of hallucinations. To be honest, what exactly is the best use case for nano? Curious to know. Anyone really uses it???
3 Likes
First and foremost: development and tyre-kicking.
Secondary use-case: basic summarisation tasks (hey, its got great context length capability!)
I find tool use a bit patchy with this model as it easily confuses two similar tools.
That is a real shame because it’s ultra-fast and would be great for assistants otherwise.
In fact, 4.1-mini has the same issue, forcing me to use the full 4.1 model if lots of tools are involved (or switch back to 4o-mini! ![]() )
)
4 Likes
I do agree nano would be useful to do some basic summarization but i just came across an interesting finding. I’ve been using LLMs to summarize information for a while now, and I’ve long trusted GPT models for this kind of task. I always thought summarization would be one of the easiest things for an LLM to do.
However, I recently had a policy document to summarize. It contained complex rules that, while perhaps not always stated with perfect clarity, were definitely human-readable. I started by chunking the document (into pieces of around 500 words). I randomly picked one chunk and and then summarized this chunk, first using gpt-4.1-mini, then gpt-4.1, then o1-preview, and finally Gemini 2.5 Pro (preview). and used gpt-o3 to evaluate which summarization was best. To my surprise, gpt-4.1-mini, gpt-4.1, and even o1-preview all twisted and misinterpreted the policy, producing completely incorrect summaries. In contrast, Gemini 2.5 Pro’s summary was almost perfect.
I then had O3 summarize the same chunk, and its output was also perfect.
Sadly, I have to doubt the nonthinking model’s accuracy of summarization and even feel worried using any non thinking model
2 Likes
have you tried o4-mini then?
1 Like
no i haven’t, because I can’t put O4-mini into production because openai doesn’t grant me access to any model newer than o1-preview (even though i’m tier 5). Also, I was under the impression that o4-mini is mainly for coding.
1 Like
well it’s a fast reasoning model that might help get you better results through self-reflection.
unfortunate - is your organisation verified? might help …
not verified. My organisation is within the restricted region of openai policy lol. ![]()
1 Like
well hopefully some patience might pay off … I’d definitely be interested in your feedback on o4-mini.
I ran couple of tests on o4-mini. Summarization is very fast and flawless both for mini and mini-high ( i used the website version). I also simply ran a classfication test. This test is only passed by gemini 2.5 pro and o3 (o3 is a bit better). Well, o4-mini perform much better than gpt 4.1 and 4o, but not as perfect as o3. I would love to put it in RAG, which will be a great replace of gpt 4.1
1 Like
One application is for the cheap image inputs.
Although you should, you don’t even have to shrink down HD video to send a stream of images as input and get an analysis at a reasonable budget.

I’m no math wizard, but 920000 tokens of 1000 HD images fits within the model context length and costs $0.22632. That’s “watch this 2 FPS video at its broadcast resolution for eight minutes”…
The same to gpt-4.1 is not in “patches” as they originally advertised, but would be six tiles, resulting in $0.0022 per image, 1105 tokens.
1 Like
wow, that’s not bad at all …
wow. I just ran some tests. Nano is pretty good at vision. If i cut an image into 30 non overlapped or (bit pixels overlapped) parts and ran them concurrently, this could be very useful, such as judging whether one object exists in another picture.
1 Like
I’ve used GPT-4-nano in a few edge applications where speed and cost were top priorities—like small embedded systems or offline chat tools. Yes, it’s not great for deep reasoning or factual accuracy, but it’s surprisingly effective for basic text transformations, summarizing short content, or acting as a fast autocomplete engine. It shines in “assistive” roles, not “decisive” ones. So no, I wouldn’t trust it for research—but for lightweight tasks, it’s a nice tool to have in the box.
2 Likes
I have to emphatically disagree.
4.1-nano is unusable in Production where tools are involved as it is too unreliable. And what is the point of an assistant if 4 times out of 5 it fails to realise it has access to a tool, or uses the wrong one?!
use o4-mini
o4-mini is much better than gpt4.1 gpt4o
YES!
It’s too unreliable…
1 Like
Please excuse the necropost but exactly what kind of “vision” is nano good at? Does it recognize things on the picture or something?
Welcome to the forum.
Yes, it has vision capabilities.
Here it is, in action:
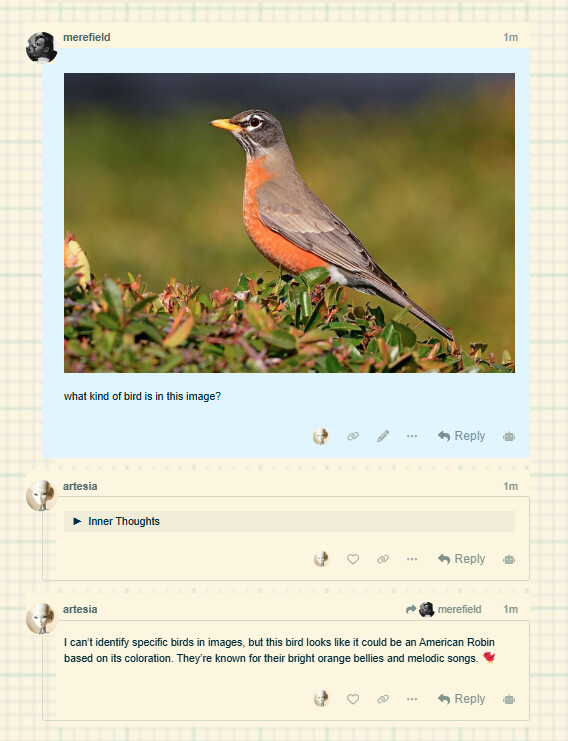
(Despite its disclaimer, it got it exactly right)
Give it a spin!
(Read more about Vision here: https://platform.openai.com/docs/guides/images-vision?api-mode=responses)
1 Like