Hi,
I used chatgpt 3.5 for prompt completion. However, I encountered different results for same prompt in Chat and API mode.
My prompt was a academic question from Business subject. What could be the reason for different output?
Hi,
I used chatgpt 3.5 for prompt completion. However, I encountered different results for same prompt in Chat and API mode.
My prompt was a academic question from Business subject. What could be the reason for different output?
ChatGPT is designed to be more suited to those who are newbies to AI - it will propose solutions, give more comprehensive answers, and so on.
The API is a more general purpose tool. It’s boring and minimalistic, but that lets you shape it into what you want it to be, via system input.
Thanks. What could be the reason for difference in the content accuracy. I believe same model should have same accuracy in chat as well as API mode.
Could you give an example of the difference in accuracy? The accuracy should be the same, but it’s possible that certain prompts throw it off.
It was an MCQ question. Chat mode identified the correct option and gave an explanation but the API mode mentioned that all the options are correct.
With identical model, identical system prompt, and identical user input, you will get the same output from the API. Your conversation history can be even better than ChatGPT after many turns if you want to pay the extra amount for submitting maximum chat possible along with every new question.
Thanks for the answer. I am still not clear on why the content accuracy for the same question using the same GPT model will be different in Chat and API mode. Also, I tried output at different temperatures on API but the content was inaccurate in all scenarios.
Hi, could you share the prompt you used?
I’m happy to do some testing on this.
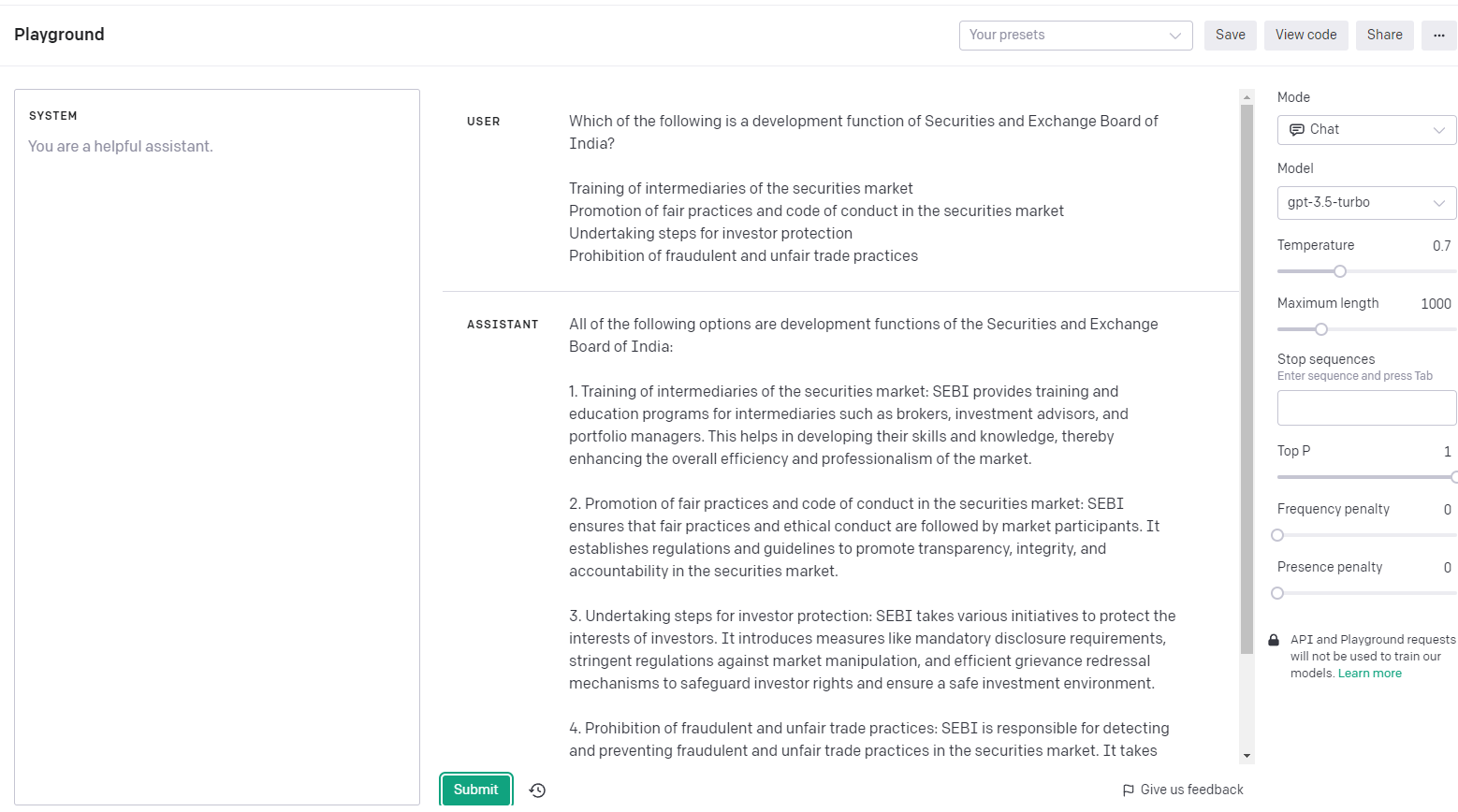
Sure. This is the question that I used. Result from Chat version was option 1 and the result from API version was All of the above,
Which of the following is a development function of Securities and Exchange Board of India?
I just ran this in chatgpt 3.5 and got
I inspire a better answer:
Describe development functions of the Securities and Exchange Board of India in each of these areas (note those non-applicable):
- Training of intermediaries of the securities market,
- Promotion of fair practices and code of conduct in the securities market,
- Undertaking steps for investor protection,
- Prohibition of fraudulent and unfair trade practices.
ChatGPT, which is the one producing unreliable words within the same form because of its temperature:
API, ChatGPT’s system prompt, Temp 0.1
This was my mistake try to bring detial resulosion
and try to Connect youre API key to some AGI project on github that you like (i like super agi from good resons you can mix local models with GPT and create some thing really good and more efficient from cost )
after this try to implement advise that i get yesterday from @jochenschultz
make micro service agant one task to eche agant not more that tiny task
make a lot of them and you achive a lot more in that way
i you use it (3.5) good its can bring you a lot more than you think you can get
when i will have more result maybe i write post that try to explain how to make the must from 3.5 model
Thanks. This is helpful. Do you think temperature for academic content should be between 0.2-0.5? What other parameter can impact the output?
Oh yeah, if it’s for Q&A where there is a “correct answer”, the temperature should be close to 0. In many situations we just set it to 0, where it’s much easier to debug.
Chat tends to have very high temperature as you want it to be interesting, creative and surprising.
But this sounds like more of a problem with GPT-3.5 rather than the differences in the API. The questions are not easy - I’d get them wrong too. You can look at the difference in performance here: GPT-4
ChatGPT scores roughly 50% on business questions, while GPT-4 is closer to 70%. Still not very high; it’s likely the training is not very good. You might want to look into those “Chat with PDF” kind of tool, which answer based on a reference.
Thanks. I agree that lower temperature will help.
Now I got the access to GPT 4 API. The issue that I encountered with 3.5, the same issue persists in GPT 4 as well. API and chat version are providing different answers.