Hello, i don’t know what’s wrong with all the explanations i found on the internet about these 3 but i just don’t get it.
I kindly request someone explain here, clear and concise, what is the difference of these 3:
Any API call has an input and an output. Depending on the endpoint you use, the input equals prompt or messages parameter.
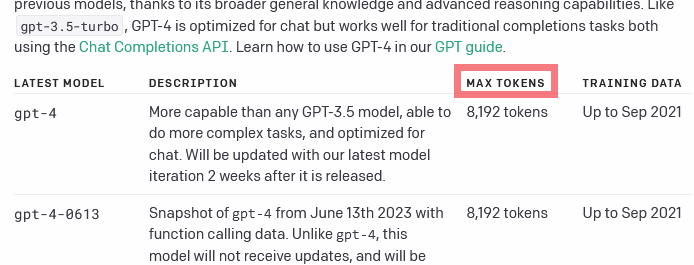
The number of total tokens (input + output) allowed by OpenAI depends on the model you use: 4k for text-davinci-003, 8k for gpt-4, etc:
1- Context length (or context window) usually refers to the total number of tokens permitted by your model. It can also refer to the number of tokens of your input (depends on the context). 2 and 3 - these ones are equivalent. They refer to the max number of tokens that you allow your API call to generate. It’s just a cap: it doesn’t mean that your call will actually generate all these tokens. It should always be less than context_window - input_tokens, or you’ll get an error from OpenAI.
Context length (where GPT-3.5 = 4K and GPT-4 = 8K/32K) refers to ALL TOKENS (words, spaces, sentences, whatever) used in ALL REQUESTS until the model “forgets” the entire conversation, INCLUDING the INPUT (e.g user questions) and OUTPUT (e.g model answers) ?
How is that Max_token and Maximum Length are equivalent?
E.g: In the Playground (OpenAI) the Maximum Length slider is up to:
text-davinci-003 → 4000 tokens
gpt-3.5-turbo → 2048 tokens
and also
gpt-4 → 2048 tokens
! Where, when using another site to acces the API (i don’t know if i’m allowed to link it here)
The “Max token” slider is up to:
gpt-3.5-turbo → 4000 tokens
gpt-4 → 8192 tokens
If Max token & Maximum length are the same, why the Playground (OpenAI) shows different values?
If Max_token is 8K (as in the site i said) and the Context length is 8K, how is this working using the rule “max_token” cannot exceed the context length?
1 - This API is stateless. It doesn’t remember any previous interaction: you need to provide it in your input parameter in every request. So one request is not affected by the previous ones. And yeah, the context length limits the sun of tokens input + output. For every request.
2 - gpt-4 and gpt-3.5-turbo slicers also allow 4k tokens of max length, not 2k. And that’s a playground constraint: they force your completion to be shorter than 4k in these models. But the API underneath can produce more tokens for gpt-4 (up to 8k, in case you did not include any prompt).
I don’t understand, what do you mean it doesn’t remember anything if I am having a conversation with it ? I give it things to do and then I talk to it relating about previous messages.
I don’t know if we are talking about same thing.
I am talking as I said, about gpt 3.5/4, which are CHAT completion, isn’t this how it should be ? To remember previous requests ? That’s how Chatgpt works. Am I wrong ?
As I said, the API is stateless. It doesn’t remember anything.
I assume that you’re talking about the playground. In that case, yeah: it “remembers” the previous interactions. But that’s only because it sends all of them to the API every time you submit a new message